标签:des style blog http io ar color 使用 sp
稀疏自编码器的学习结构:
神经网络
反向传导算法
梯度检验与高级优化
稀疏自编码器Ⅱ:
自编码算法与稀疏性
可视化自编码器训练结果
Exercise: Sparse Autoencoder
已经讨论了神经网络在有监督学习中的应用,其中训练样本是有类别标签的(x_i,y_i)。
自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值x_i = y_i 。
下图是一个自编码神经网络的示例。
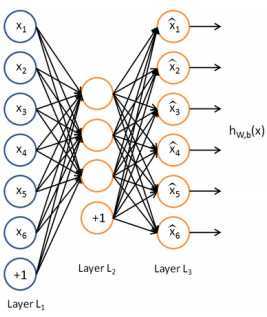
一次autoencoder学习,结构三层:输入层单元数=输出层单元数,隐藏层。自编码神经网络尝试学习一个输入约等于输出的恒等函数。
给自编码神经网络加入某些限制,我们就可以从输入数据中发现一些有趣的结构。比如限定隐藏神经元的数量。
当输入数据是完全随机的,比如输入特征完全无关,难学习。
当输入数据中隐含着一些特定的结构,比如输入特征是彼此相关的,算法就可以发现输入数据中的这些相关性。
事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
以上是稀疏性的含义,具体获得稀疏性的方法ufldl教程中有详细讲述,这里只说核心概念框架。
隐藏神经元 j的平均活跃度(在训练集上取平均)
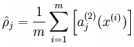
注意,计算用到了前向传播算法,而BP也用到了,内存够保存算一遍,否则两遍。
限制 其中p是稀疏性参数,通常是一个接近于0的较小的值(比如 p=0.05 )
其中p是稀疏性参数,通常是一个接近于0的较小的值(比如 p=0.05 )
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些 和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内(稀疏性)。
惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:
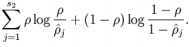
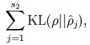
KL divergence 性质:相等为0,随着之间的差异增大而单调递增。
现在,我们的总体代价函数可以表示为:
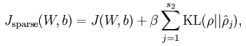
To incorporate the KL-divergence term into your derivative calculation, there is a simple-to-implement trick involving only a small change to your code.
具体地,在BP第二层中:
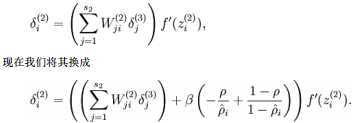
训练完(稀疏)自编码器,我们还想把这自编码器学到的函数可视化出来,好弄明白它到底学到了什么。我们以在10×10图像(即n=100)上训练自编码器为例。

实验
首先是从如下图这样的10 image(512×512),中sample 10000 image patches(8×8)。


sample 10000 image patches(8×8) and concatenate them into a 64×10000 matrix
display a random sample of 204 patches from the dataset

以下是一些设置参数,就是学习单个自动编码器,学到一个隐含层的基(参数W,b)。
|
visibleSize = 8*8; % number of input units hiddenSize = 25; % number of hidden units sparsityParam = 0.01; % desired average activation of the hidden units. % (This was denoted by the Greek alphabet rho, which looks like a lower-case "p", % in the lecture notes). lambda = 0.0001; % weight decay parameter beta = 3; % weight of sparsity penalty term |
以下是序列输出结果
|
>> train Iteration FunEvals Step Length Function Val Opt Cond 1 3 8.63782e-03 3.98056e+01 1.03759e+03 2 4 1.00000e+00 6.68382e+00 2.49253e+02 ……. 399 414 1.00000e+00 4.49948e-01 1.45238e-02 400 415 1.00000e+00 4.49947e-01 1.40765e-02 Exceeded Maximum Number of Iterations 时间已过 20.942873 秒。 |
教程中说Our implementation took around 5 minutes to run on a fast computer.
sparse autoencoder algorithm learning a set of edge detectors.
隐藏层权重可视化后,我们可以看出学到了一组边缘检测器,一组基或称字典。

标签:des style blog http io ar color 使用 sp
原文地址:http://www.cnblogs.com/JayZen/p/4129386.html