标签:style blog http ar color os sp 数据 div
本文主要讨论的内容包括:BST的性质以及基本操作分析。
作为最基本的数据结构,二叉查找树(后文记为BST)本身不仅易于理解,代码精简,而且通过添加不同的特性,可以实现许多高级的数据结构,例如:添加颜色信息,升级为红黑树;添加高度和平衡信息,升级为AVL树;更改节点数量,成为2-3-4树等更为复杂的数据结构。而正如其名,BST及其变种在搜索领域有不可替代的作用。
在BST上执行的基本操作与树的高度成正比。对于一棵含n个节点的完全二叉树(perfect binary tree),这些操作的最坏运行时间为O(lgn)。但是,如果树是含n个节点的线性链,则这些操作的最坏运行时间为O(n)。
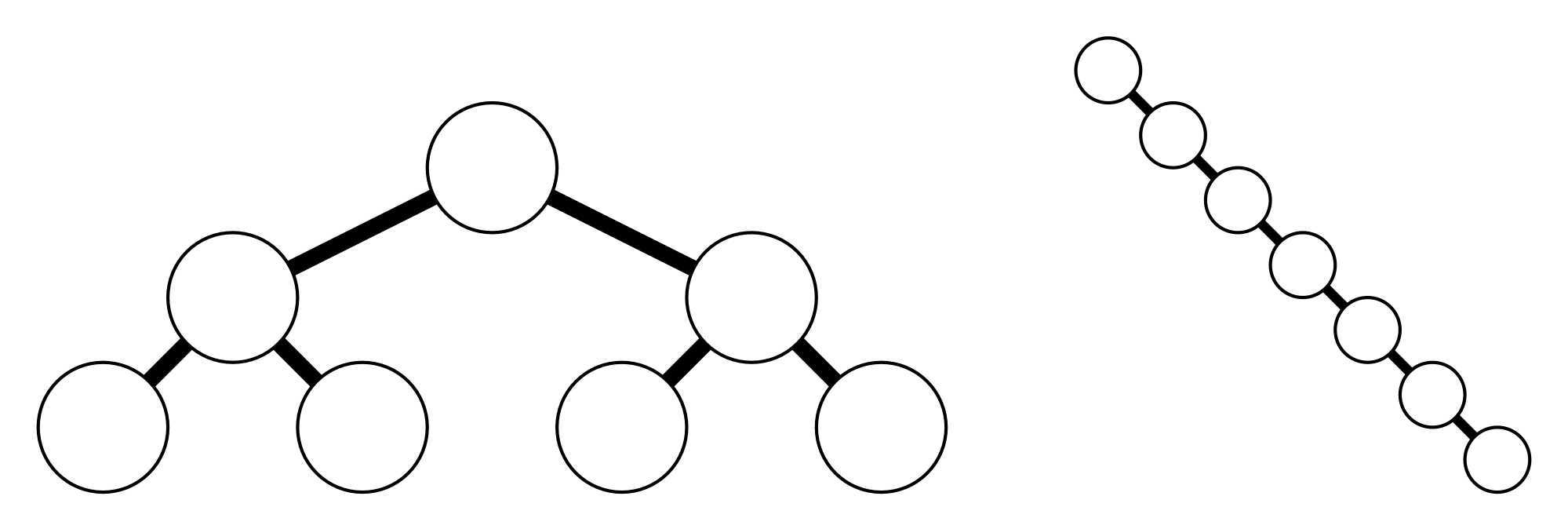
BST作为最基本的树结构(其实还有更基本的单纯的树,不过在这里没有讨论意义),并没有特殊性质去维护其平衡性,如下图,同样都是含有7个结点的二叉树,其高度却不尽相同。因而其基本操作时间也不尽相同。对于一棵含有n个节点的BST,其高度为lgn(完全二叉树)到n(线性链)。故操作时间也不同。后面我们将会看到,一颗随机构造的BST其期望高度为O(lgn),从而基本操作平均时间为O(lgn)。
如图所示,BST是按二叉树结构组织而成。可以用链表结构表示。一般而言,一个BST的结点声明如下:
1 struct _BST_Node { 2 int key; // key域 3 DataType *data; // 卫星数据 4 struct _BST_Node *parent; // 父节点 5 struct _BST_Node *left; // 左子结点 6 struct _BST_Node *right; // 右子节点 7 }
8
9 typedef struct _BST_Node BST_Node;
如果某个指针对象不存在,则设为NULL。根节点是树中唯一父结点为NULL的结点。
BST中关键字总是按照如下方式存储来保持二叉搜索树的性质:设x是BST中一个结点,则
如果y是x左子树中的一个结点,则 y.key <= x.key;反之,如果y是x右子树中的一个结点,则 y.key >= x.key。
根据BST的性质,我们可以用一个递归算法来依次输出书中所有关键字。根据顺序的不同,有三种遍历算法:
前序遍历(Preorder Traversal):中根-左子树-右子树;
中序遍历(Inorder Traversal):左子树-中根-右子树;
后序遍历(Postorder Traversal):左子树-右子树-中根;
此外,还有一种常用的遍历算法为广度优先搜索(Breadth-First Search, BFS),又称层序遍历,即在遍历中,每进入下一层之前,先将本层结点输出。
下面我们给出中序遍历的伪代码:
1 void InorderTraversal(BST_Node *root) { // root为要输出的树的根节点 2 3 if (root != NULL) { // 当前根节点不为空时进入遍历 4 InorderTraversal(root->left); // 继续中序遍历左节点 5 Print(root); // 输出当前结点 6 InorderTraversal(root->right); // 继续中序遍历右结点 7 } 8 9 return; 10 }
于是我们可以很容易得出前序和后序遍历的代码,即改变代码4~6行中的次序即可。
接下来我们讨论BST的BFS实现方法:
实现层序遍历需要用到队列结构。首先根节点进队,随后出队,出队前,需要将其左右两个子女依次进队。保持循环直到队列为空为止。下面给出伪代码:
1 void BFS(BFS_Node *root) { // root为要输出的树的根节点 2 3 if (root != NULL) { // 当根节点不为空时进入遍历 4 5 Create queue; // 新建空队列 6 Enqueue(queue, root); // 根节点进队 7 8 while (!isEmpty(queue)) { // 队列不为空时循环输出 9 Enqueue(queue, queue.top->left); // 当前节点左右子女进队 10 Enqueue(queue, queue.top->right); 11 Print(queue.top); // 输出队头 12 Dequeue(queue); // 队头出队 13 } 14 }
15 16 return; 17 }
事实上,广度优先搜索不仅在树中,在后面重要的数据结构图(graph)中也有着重要的作用。
定理:如果tree是一棵包含n个节点的树的根,则遍历树tree过程的时间为O(n)。
对于二叉查找树,最常见的操作就是查找树中某个关键字。除了搜索任意关键字Search操作外,还应支持查找最小值(Min)、最大值(Max)、后继(Successor)、前驱(Predecessor)。
在一棵高度为h的树中,这些操作都可以在O(h)时间内完成。
查找操作很容易实现,由于BST的性质,使得查找操作的实现类似于二分搜索。我们给出递归和非递归两个版本的搜索实现。
1 BST_Node *Search(BST_Node *root, int key) { // key为搜索关键字 2 3 if (root == NULL || key == root->key) // 查询到key则返回包含key的结点,否则返回NULL 4 return root; 5 if (key < root->key) // 根据BST性质查找左子树或右子树 6 return Search(root->left, key); 7 else 8 return Search(root->right, key); 9 } 10 11 // 搜索过程的非递归版本,一般而言速度会比递归版本快一点 12 BST_Node *Search(BST_Node *root, int key) { 13 14 while (root != NULL && key != root->key) { 15 if (key < root->key) 16 root = root->left; 17 else 18 root = root->right; 19 } 20 21 return root; 22 }
根据BST的性质,我们可知一棵树的最小关键字结点一定是最左子节点,同理最大关键字节点一定是最右子节点。于是我们得到了如下代码:
1 BST_Node *Min(BST_Node *root) { 2 while (root->left != NULL) 3 root = root->left; 4 return root; 5 } 6 7 BST_Node *Max(BST_Node *root) { 8 while (root->right != NULL) 9 root = root->right; 10 return root; 11 }
首先我们应当定义一个节点的前驱和后继分别代表什么。一般而言,前驱是指中序遍历时,在该节点前输出的那个结点,后继是在该节点后面输出的那个节点。换句话说,如果一棵树中所有关键字都不相同,则结点node的前驱为所有小于node关键字的最大关键字结点,后继为所有大于node关键字的最小关键字结点。在有了中序遍历算法的情况下,我们很容易得出搜索前驱和后继的算法,但如果每次查找前驱后继都需要遍历二叉树,未免显得太过复杂。事实上,根据BST的结构性质,不需要对关键字进行比较及遍历,即可找到某个节点的前驱或后继。
前驱:对于结点node,如果其有左子树,则后继为其左子树最右节点;如果左子树为空,则其后继为其最低祖先结点、且该节点右结点也为node的祖先。
后继:对于结点node,如果其有右子树,则后继为其右子树最左结点;如果右子树为空,则其后继为其最低祖先结点、且该节点左结点也为node的祖先。
这两个定义很绕口,我们需要看图来辅助理解,如图:
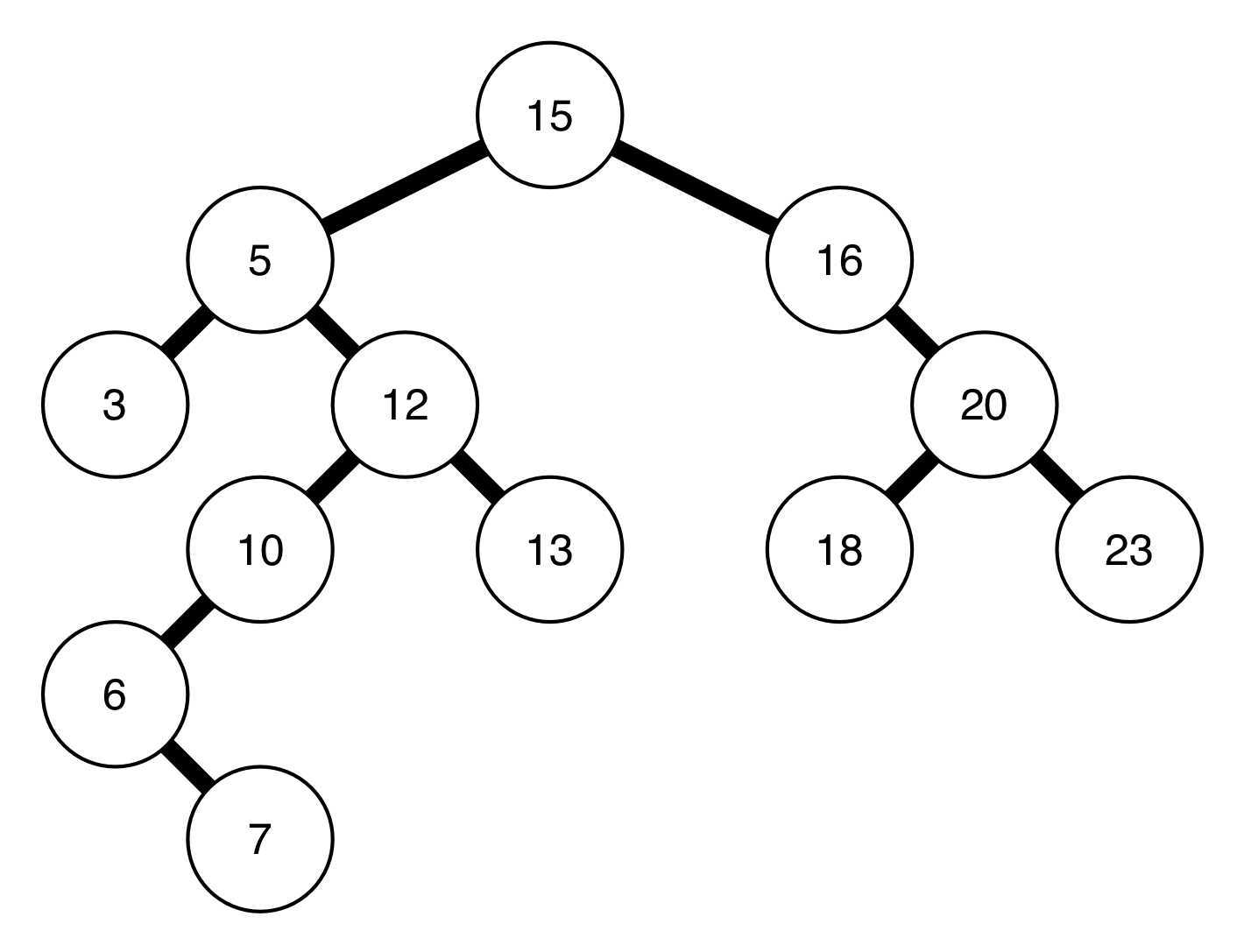 我们先找结点6的前驱。根据性质,结点6无左结点,所以我们延其祖先路径向上寻找。我们需要找到这样一个最低的祖先结点:其右结点也是结点6的祖先。结点10不是,它没有右结点。结点12也不是,它的右结点并不是结点6的祖先。结点5是,它的右结点12也是结点6的祖先,并且他是我们遇到的第一个满足该性质的结点。所以结点5是结点6的前驱。
我们先找结点6的前驱。根据性质,结点6无左结点,所以我们延其祖先路径向上寻找。我们需要找到这样一个最低的祖先结点:其右结点也是结点6的祖先。结点10不是,它没有右结点。结点12也不是,它的右结点并不是结点6的祖先。结点5是,它的右结点12也是结点6的祖先,并且他是我们遇到的第一个满足该性质的结点。所以结点5是结点6的前驱。
我们再来找结点12的前驱,根据性质,结点12有左结点,因而其前驱是其左子树的最右结点,即最大结点。因而结点10是结点12的前驱。
我们再来找结点13的后继。根据性质,结点13无右结点,所以需要延其祖先路径想上寻找。我们需要找到这样一个最低的祖先结点:其左结点也是结点13的祖先。结点12不是,它的左结点不是结点13的祖先,结点5不是,他的左结点不是结点13的祖先。结点15,即根节点是,因为它的左结点5,也是结点13的祖先,并且它是我们遇到的第一个满足该性质的结点。所以结点15是结点13的后继。
最后我们找结点5的后继。根据性质,结点5有右结点,所以其后继是右子树的最左结点,即最小结点。因而结点6是结点5的后继。
下面我们给出伪代码实现:
1 BST_Node *Predecessor(BST_Node *node) { 2 3 if (node->left != NULL) 4 return Max(root->left); 5 6 BST_Node *predecessor = node->parent; 7 while (predecessor != NULL && node == predecessor->left) { 8 node = predecessor; 9 predecessor = node->parent; 10 } 11 12 return predecessor; 13 } 14 15 BST_Node *Successor(BST_Node *node) { 16 17 if (node->right != NULL) // 若结点node右子树不为空,则其后继为右子树中的最左结点,即右子树最小关键字结点 18 return Min(root->right); 19 20 BST_Node *successor = node->parent; // 若结点node右子树为空,则其后继为其最低祖先借点,且该节点做结点也为node的祖先 21 while (successor != NULL && node == successor->right) { 22 node = successor; 23 successor = node->parent; 24 } 25 26 return successor; 27 }
性质:如果BST中的某个结点有两个子女,则其后继没有左结点,前驱没有右结点。(CLRS 12.2-5)
证明:其实这个很容易理解。这里只证明后继的部分。如果结点x有两个子女,记为xLeft和xRight,则x的后继必定在xRight子树上,且xRight上所有结点关键字都大于x(假设没有重复关键字)。设结点y为x的后继,根据定义有y为大于x的最小节点。如果y有左结点,则该左结点比后继还小,与定义不符。
在插入和删除时,最关键的就在于要维护BST性质。在一棵高度为h的树中,这些操作都可以在O(h)时间内完成。
插入过程还是很简单的,首先查找到插入位置,然后链接下新节点跟父节点就可以了。这里假设newnode已经设定好了,两个子女均为NULL。
1 void Insert(BST_Node *root, BST_Node *newnode) { 2 3 BST_Node *parent; 4 BST_Node *temp = root; 5 6 // 寻找到合适的插入位置,并记录其父节点 7 while (temp != NULL) { 8 parent = temp; 9 if (newnode->key < temp->key) 10 temp = temp->left; 11 else 12 temp = temp->right; 13 } 14 15 // 如果所记录父节点为空,则插入到根节点,否则链接新结点与父节点 16 newnode->parent = parent; 17 if (parent == NULL) 18 root = newnode; 19 else { 20 if (newnode->key < parent->key) 21 parent->left = newnode; 22 else 23 parent->right = newnode; 24 } 25 }
删除过程要考虑三种情况:设待删除节点为z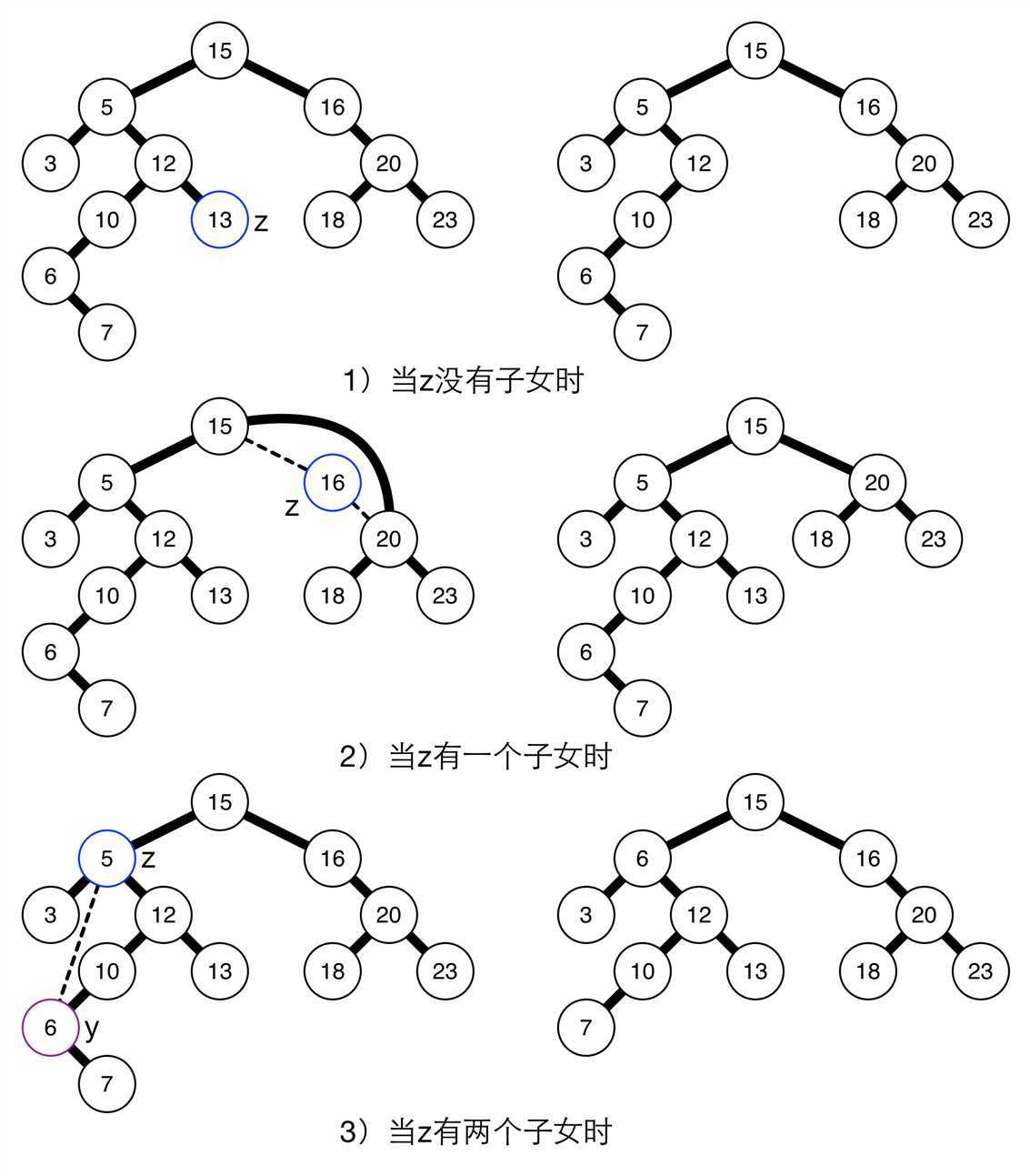
1) 如果z没有子结点,则修改其父节点z.parent指向NULL;
2) 如果z只有一个子结点,则修改其父节点z.parent指向z的唯一子节点;
3) 如果z有两个子节点,则用z的后继y来代替z,并删除y(已经证明z的后继没有左结点,但有可能有右结点,所以还需要处理y的子结点)。事实上,这里也可以用前驱,并无差别。
1 void Remove(BST_Node *root, BST_Node *z) { 2 3 BST_Node *x,y; 4 // 确定处理输入结点z(至多一个结点),还是其后继(有两个节点) 5 if (z->left == NULL || z->righ == NULL) 6 y = z; 7 else 8 y = Successor(z); 9 // x被置为y的非空子女 10 if (y->left != NULL) 11 x = y->left; 12 else 13 x = y->right; 14 // 修改被删除节点的子节点的父节点指针 15 if (x != NULL) 16 x->parent = y->parent; 17 // 修改被删除节点的父节点的子节点指针 18 if (y->parent == NULL) { 19 root = x; 20 else { 21 if (y == y->parent->left) 22 y->parent->left = x; 23 else 24 y->parent->right = x; 25 } 26 // 用后继替换原结点内容 27 if (y != z) { 28 z->key = y->key; 29 z->data = y->data; 30 } 31 32 return; 33 }
数据结构选讲-二叉查找树(Binary Search Tree)
标签:style blog http ar color os sp 数据 div
原文地址:http://www.cnblogs.com/rancher/p/4122381.html