标签:style blog http ar color os 使用 sp for
1.提出问题
在上篇博文中,提到了为什么要配置ssh免密码登录,说是Hadoop控制脚本依赖SSH来执行针对整个集群的操作,那么Hadoop中控制脚本都是什么东西呢?具体是如何通过SSH来针对整个集群的操作?网上完全分布模式下Hadoop的搭建很多,可是看完后,真的了解吗?为什么要配置Hadoop下conf目录下的masters文件和slaves文件,masters文件里面主要记录的是什么东西,slaves文件中又记录的是什么东西,masters文件和slaves文件都有什么作用?好,我看到过一篇配置文件是这样的,namenode、辅助namenode节点在一个主机上,jobtracker节点在另一台主机上!当时他是这么配置的,将namenode(辅助namenode)和jobtracker主机的ip都加到了masters文件中,这样配下来虽然不会报错,可是,并没有理解masters的作用!!
2.记录一下几个知识点
<1>Hadoop中的控制脚本到底有哪些
<2>查看一些主要的控制脚本,看看都是什么作用
<3>为什么要配置ssh免密码登录
<4>Hadoop中conf目录下的masters文件和slaves文件该写什么,有什么作用?
3.Hadoop中的控制脚本
配置过Hadoop的人都知道,不管是伪分布式,还是完全分布式,最后一步都是start-all.sh,没错,这个命令就属于控制脚本。
我们可以从Hadoop的bin目录下面查看Hadoop中的控制脚本,如下图所示,start-all.sh、start-dfs.sh等。
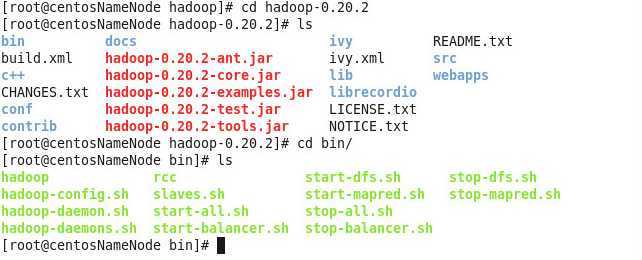
4.Hadoop一些重要的脚本
我们可以在命令行下通过cat指令来查看脚本文件,看看都有什么作用:
<1>start-all.sh脚本
这个控制脚本毋庸置疑,安装过Hadoop的都知道,安装完最后一步,就是start-all.sh
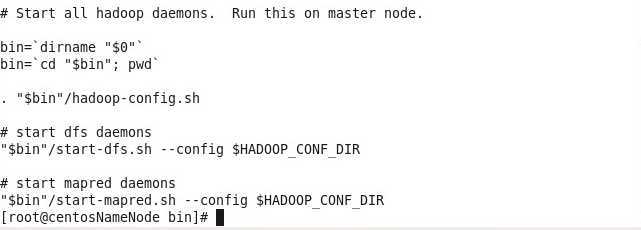
分析,可以得到,这个里面主要又包含了三个控制脚本:
(1)hadoop-config.sh
(2)start-dfs.sh
(3)start-mapred.sh
这三个控制脚本也属于Hadoop的控制脚本,在3.Hadoop中的控制脚本可以看到,所以,start-all.sh其
实是让上面那三个脚本运行,再来看看上面那三个脚本
<2>start-dfs.sh脚本
我们再来通过指令cat来看看start-dfs.sh的内容,看看它有什么作用

可以看到,这个控制脚本,也调用了别的控制脚本,分析后面的内容:
(1)hadoop-daemon.sh --start namenode 根据内容,知道这个是开启namenode守护进程
(2)hadoop-daemons.sh --start datanode 根据内容,知道这个是开启datanode守护进程
(3)hadoop-daemons.sh --start secondarynamenode 根据内容,知道这个是开启辅助namenode守
护进程
所以,start-dfs.sh的作用就是调用控制脚本hadoop-daemon.sh和hadoop-daemons.sh!那么再来看
看这两个脚本是干什么的
<3>start-daemon.sh脚本
同上面一样,我们用cat查看这个脚本,一堆脚本程序,大致的意思就是:主要是生成namenode 的日
志文件,然后将具体的操作请求转发给 org.apache.hadoop.hdfs.server.namenode.NameNode 这个
类。
<4>start-daemons.sh脚本
用cat查看这个脚本

启动datenode时,调用slaves.sh 同时将本地的hadoop_home传递过去,所以说slaves和master的
hadoop路径要一致了
启动辅助namenode时将具体的请求转发给
org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode这个类
OK,再看看salves.sh做了什么
<5>slaves.sh脚本
(1)读取slaves文件里ip配置
(2)ssh每个slave机器
(3)到Hadoop_HOME目录下
(4)执行hadoop-daemon.sh脚本
(5)传递的启动参数为 start datenode
(6)使用conf文件为slave机器HADOOP_HOME下的
再看看slaves机器上的执行情况,其实是把请求转交给了
org.apache.hadoop.hdfs.server.datanode.DataNode这个类来处理了。
<6>start-mapred.sh脚本
(1)hadoop-config.sh //mapreduce的配置相关
(2)hadoop-daemn.sh //start jobtracker
(3)hadoop-daemons.sh //start tasktracker
再看对mapred的处理,其实是把请求转给一下两个类。
org.apache.hadoop.mapred.JobTracker //master机器上
org.apache.hadoop.mapred.TaskTracker //slaves机器上
5.为什么ssh要免密码登录
通过上面对控制脚本的分析,我们大致知道了,当在执行start-all.sh或者start-dfs.sh脚本的时候,最终都会调用slaves.sh控制脚本,这个脚本根据slaves文件中的ip地址,通过ssh远
程登陆到datenode,并启动 datenode守护进程,如果每次都需要手动输入密码,数千台计算机,很不可能,所以,我们要实现ssh免密码登录
6.Hadoop中conf目录下面的masters和slaves文件
在配置Hadoop分布式文件系统的时候,会让你配置masters和slaves这两个文件,那么这两个文件都有什么作用,里面都记录什么?
masters文件主要记录运行辅助namenode的所有机器。
slaves文件主要记录了运行datanode和tasktracker的所有机器。
有些人把masters文件,当作是记录所有masters主节点的ip,这么的话,jobtracker,namenode、辅助namenode上面都会启动辅助namenode守护进程,这并不是用户的初衷
标签:style blog http ar color os 使用 sp for
原文地址:http://www.cnblogs.com/robert-blue/p/4133475.html