标签:style blog http io ar os sp for java
由于下载的是hadoop的最新版,网上各种杂七杂八的东西都不适用。好在官网上说的也够清楚了。如果有人看这篇文章的话,最大的忠告就是看官网。
官网2.6.0的安装教程:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/SingleCluster.html
hdfs指令:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
注意:2.6.0默认的都是64位系统的,如果用32位的机器总是会出现下面的警告: 这个可以无视,不会影响结果
Java HotSpot(TM) Client VM warning: You have loaded library /home/software/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It‘s highly recommended that you fix the library with ‘execstack -c <libfile>‘, or link it with ‘-z noexecstack‘.
14/12/04 21:52:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1.安装jdk 我写在另一篇文章里了http://www.cnblogs.com/dplearning/p/4140334.html
2. ssh免密码登陆 http://www.cnblogs.com/dplearning/p/4140352.html
3.配置
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. $ bin/hdfs namenode -format //格式化
5. $ sbin/start-dfs.sh //开启进程
成功的话,jps查看进程应该是
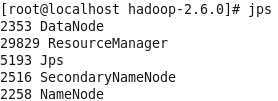
如果没有DataNode 查看一下日志
如果有错误
java.io.IOException: Incompatible clusterIDs in /tmp/hadoop-root/dfs/data: namenode clusterID = CID-2b67ec7b-5edc-4911-bb22-1bb8092a7613; datanode clusterID = CID-aa4ac802-100d-4d29-813d-c6b92dd78f02
那么,应该是/tmp/hadoop-root 文件夹中还有之前残留的文件,全部清空后重新format,重新启动程序应该就好了。
运行例子:
1.先在hdfs上建个文件夹 bin/hdfs dfs -mkdir -p /user/kzy/input
bin/hdfs dfs -mkdir -p /user/kzy/output
2.先上传一些文件:bin/hdfs dfs -put etc/hadoop/ /user/kzy/input 把etc/hadoop文件上传到hdfs的/user/kzy/input中
3.执行指令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /user/kzy/input/hadoop /user/kzy/output/o ‘dfs[a-z.]+‘
注意/user/kzy/output/o 是个没有建立过的文件夹,如果用已有的文件夹会有个警告
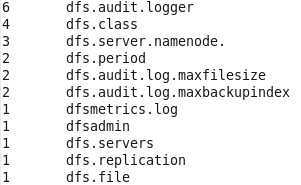
4.查看结果
bin/hdfs dfs -cat /user/kzy/output/o/*
再运行一些wordcount,官网的在http://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
运行
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /user/kzy/input/hadoop /user/kzy/output/wordcount
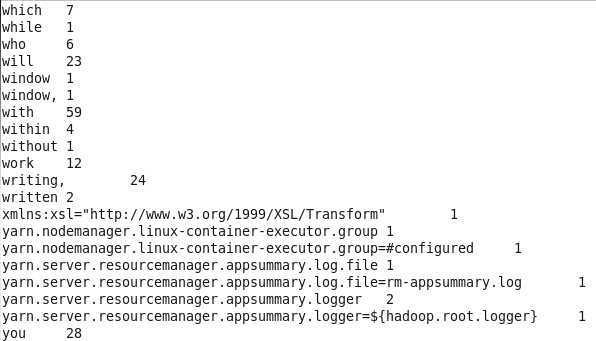
用
bin/hdfs dfs -cat /user/kzy/output/wordcount/* 看结果
标签:style blog http io ar os sp for java
原文地址:http://www.cnblogs.com/dplearning/p/4145209.html