做性能测试先要懂性能,响应时间(response time)作为性能测试过程中两大重要指标之一是我们必须关注的。
从用户角度来说,用户最讨厌等待。在大量的处理环境中,超过3秒以上的响应时间将会严重影响工作效率。然而最终用户的感受不仅仅是绝对时间问题,他们对于响应时间的期望是参照以往的经验,而这种期望是相对于他们使用该应用的基准性能。如果使用该应用的当前感受和以往的经验有很大的差别时,抱怨以及需要支持的电话就会成倍地增加。响应时间对于用户来说既有客观成分,也有主观成分。
例(1):对于小说网站来说,页面的主要功能是向用户提供可阅读的内容,那么用户很可能会将“小说内容”这个时间作为自己感受到的响应时间;
例(2):对于报税系统来说,页面的主要功能是提供给用户申报纳税的页面,那么用户只有用户打开申报页面,申报纳税成功后,才会觉得页面响应完成。
对于例(1)而言,小说内容完全可以分段加载,先加载500字内容,等待之前500字加载完成之后,再加载之后的内容,当看完一定内容,用户做鼠标滚动或翻页操作时再加载之后的内容。
对于例(2)而言,申报纳税需要等待,服务器处理、数据库处理、外部系统通信、浏览器前端加载等整个流程处理结束之后,才能算作响应成功。
对于例(1)可以将响应时间理解为“应用系统从请求发出开始到客户端收到响应所消耗的时间”。而对于例(2)而言响应时间定义为“应用系统从请求发出开始到客户端接收到最后一个字节数据所消耗的时间”。造成这种差异的原因是可以采用一些技巧在数据尚未完全接收完成时进行呈现来减少用户感受到的响应时间。
下图为Web应用的页面响应时间简要构成。从图中可以看到,页面的服务端响应时间可被分解为网络传输时间(N1+N2+N3+N4)、应用处理时间(T1+T3)、数据库处理时间(T2)和前端浏览器加载时间(T4)。之所以要如此细分响应时间,主要目的是能够更准确地定位性能瓶颈。
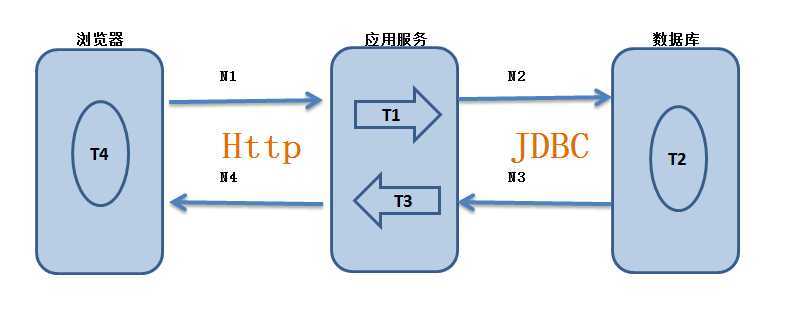
TCP为Http提供了一条可靠的比特传输管道。从TCP连接一端填入的字节会从另一端以原有的顺序、正确地传送出来。
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。 简单地说,JDBC可做三件事:与数据库建立连接、发送操作数据库的语句并处理结果。
数据库建立连接一般通过连接池管理连接,当连接池中某条查询语句执行完成,连接池所获取的连接不会立即释放,而会等待下次查询调用连接。因为建立连接也是极为耗时的操作。
servlet生命周期
- 客户端请求该servlet
- 加载servlet类到内存
- 实例化、初始化该servlet
- init()初始化参数
- service()(doGet()或者doPost())
- destroy()
加载和实例化Servlet。这项操作一般是动态执行的,在weblogic这类中间件中能够配置servlet并发线程数,同时能监控servlet并发线程数。Server通常会提供一个管理的选项,用于在Server启动时强制装载和初始化特定的Servlet。
Server创建一个Servlet的实例
第一个客户端的请求到达Server
Server调用Servlet的init()方法(可配置为Server创建servlet实例时调用,在web.xml中<servlet>标签下配置<load-on-startup>标签,配置的值为整型,值越小servlet的启动优先级越高)
一个客户端的请求到达Server
Server创建一个请求对象,处理客户端请求
Server创建一个响应对象,响应客户端请求
Server激活Servlet的service()方法,传递请求和响应对象作为参数
service()方法获得关于请求对象的信息,处理请求,访问其他资源,获得需要的信息
service()方法使用响应对象的方法,将响应传回Server,最终到达客户端。service()方法可能激活其它方法以处理请求,如doGet()或doPost()或程序员自己开发的新的方法。
对于更多的客户端请求,Server创建新的请求和响应对象,仍然激活此Servlet的service()方法,将这两个对象作为参数传递给它。如此重复以上的循环,但无需再次调用init()方法。一般Servlet只初始化一次(只有一个对象),当Server不再需要Servlet时(一般当Server关闭时),Server调用Servlet的Destroy()方法。
在执行和获取结果前,数据库系统对此sql将进行几个步骤的处理过程:
当发布一条SQL或PL/SQL命令时,Oracle会自动寻找该命令是否存在于共享池中来决定对当前的语句使用硬解析或软解析。
通常情况下,SQL语句的执行过程如下:
- SQL代码的语法(语法的正确性)及语义检查(对象的存在性与权限)。
- 将SQL代码的文本进行哈希得到哈希值。
- 如果共享池中存在相同的哈希值,则对这个命令进一步判断是否进行软解析,否则到5步骤。
- 对于存在相同哈希值的新命令行,其文本将与已存在的命令行的文本逐个进行比较。这些比较包括大小写,字符串是否一致,空格,注释 等,如果一致,则对其进行软解析,转到步骤6。否则到4步骤。红色字体描述有误应该转到步骤5
- 硬解析,生成执行计划。
- 执行SQL代码,返回结果。
软解析在缓冲区里找到相同或相似的SQL语句,可以直接利用,不用重新进行分析生成执行计划了。硬解析则相反,即整个SQL语句的执行需要完完全全的解析,生成执行计划。而硬解析,生成执行计划需要耗用CPU资源,以及SGA资源。在此不得不提的是对库缓存中闩的使用。闩(latch)是锁的细化,可以理解为是一种轻量级的串行化设备。当进程申请到闩后,则这些闩用于保护共享内存的数在同一时刻不会被两个以上的进程修改。在硬解析时,需要申请闩的使用,而闩的数量在有限的情况下需要等待。大量的闩的使用由此造成需要使用闩的进程排队越频繁,性能则逾低下。
总结
在此大致描述了响应时间的概念,以及响应时间的组成,读懂了响应时间,才是性能测试的开始。