标签:style blog class c code java

import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.InputFormat; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.Partitioner; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken().toLowerCase()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
http://www.cnblogs.com/xuqiang/archive/2011/06/05/2071935.html
关键语句:
Job job = new Job(conf, "word count");//构造一个job作业
job.setMapperClass(TokenizerMapper.class);//设置job作业的map类
job.setReducerClass(IntSumReducer.class);//设置job作业的reduce类
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);//等待Job完成
图:数据流程图
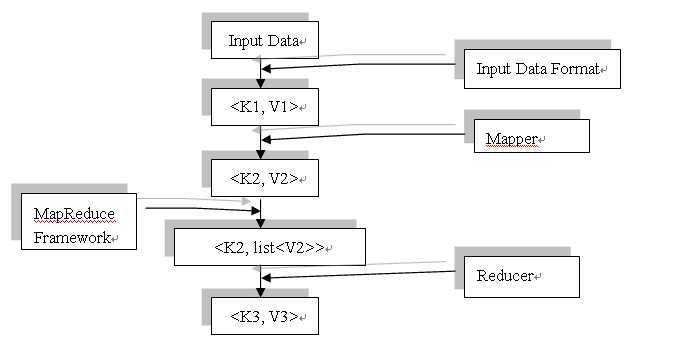
InputDataFormat类将行记录变成<行号,行内容>对;
Mapper类将记录行<行号,行内容>变成<键值,键对应内容>;
MapReduceFramwok框架将相同键值组合成<键值,对应内容列表>;
Reduce类中就是把<键值,对应内容列表>对变成<键值,键对应内容>;
我们所关注的是Mapper类和Reduce类
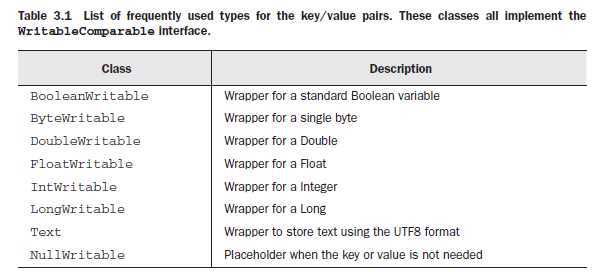
前言:数据在整体框架上能够流动是因为key和value是可以序列化和反序列化的;
value值类型通过接口Writable来定义实现;key和value值类型可以通过WritableComparalbe<T>接口实现;这些通过类实现,那么这个类就是该key和value的数据类型。
系统已经预定义实现了如下类:
同理:对于Mapper类和Reduce类
一个map类必须实现Mapper接口,一个reduce类必须实现Reduce接口;
如何实现:
重点是实现Mapper接口下的函数map;Reduce接口的reduce函数。具体原型及其代码见wordcount代码。
其中Mapper接口继承于MapReduceBase类;Reduce接口继承于MapReduceBase类。
MapReduce之浅析Map接口和Reduce接口,布布扣,bubuko.com
标签:style blog class c code java
原文地址:http://www.cnblogs.com/miner007/p/3738957.html