标签:style blog http io ar color 使用 sp java
缓存作为计算机历史上最重要的发明之一,对计算机历史起到了举足轻重的作用,因为缓存可以协调两个速度不一致的组件之间的并行运作。内存作为CPU和非易失性存储介质之间的缓存,避免CPU每次读取指令,读取数据都去速度缓慢的硬盘读取。快速缓存作为内存和CPU之间的缓存进一步提高了CPU的效率,现在大部分CPU都支持指令预取,CPU会预测后面要执行的指令预取到快速缓存中。而我们平时也直接或间接地会用到缓存技术,那如果要自己实现一个线程安全的缓存,要注意哪些问题呢?我们一步步来探讨这个问题。
假设我们提供一个服务,客户端提供一个字符串,我们返回一个对应的Long数值(当然这只是为了演示方便举的简单例子),为了提高效率,我们不希望每次都重复计算,因此我们把计算结果保存在一个缓存里,如果下次有相同的请求过来就直接返回缓存中的数据。
首先我们把计算任务抽象成Compute接口:
public interface Compute<A,V> { V compute(A args); }
一个不使用缓存计算的类:
public class NoCache implements Compute<String, Long> { @Override public Long compute(String args) { // TODO Auto-generated method stub return Long.valueOf(args); } }
这样每次都要重复计算,效率比较低,因此我们引入了一个Map来保存计算结果:
public class BasicCache1<A,V> implements Compute<A, V> { private final Map<A, V> cache=new HashMap<>(); private final Compute<A, V> c; public BasicCache1(Compute<A, V> c) { this.c=c; } @Override public synchronized V compute(A args) throws Exception { V ans=cache.get(args); if(ans==null) { ans=c.compute(args); cache.put(args, ans); } return ans; } }
这里因为HashMap不是线程安全的,因此计算方法被写成了同步方法,这样的话,每次请求最后实际都是串行执行的,大大降低了系统的吞吐量。就像下面这幅图表示的:
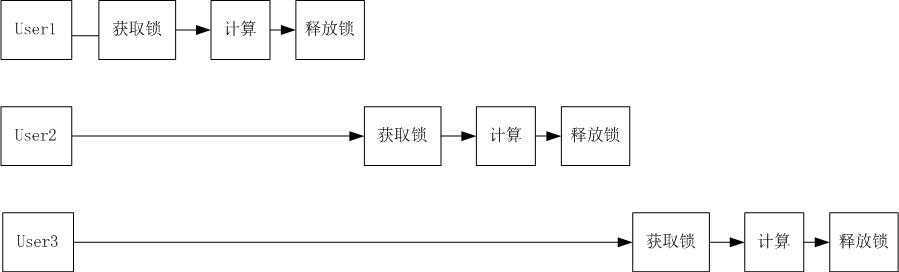
既然这样,我们就改用ConcurrentHashMap试试:
public class BasicCache2<A,V> implements Compute<A, V> { private final Map<A,V> cache=new ConcurrentHashMap<>(); private final Compute<A, V> c; public BasicCache2(Compute<A, V> c) { this.c=c; } @Override public V compute(A args) throws Exception { V ans=cache.get(args); if(ans==null) { ans=c.compute(args); cache.put(args, ans); } return ans; } }
这里没有同步compute操作,因此系统可以并发地执行请求,但是假如多个有相同参数的请求短时间内先后到达,这个时候先到达的请求还没来得及把结果写入缓存(因为计算耗时),后来的请求就会重复计算,降低了缓存的效率。一图胜前言:
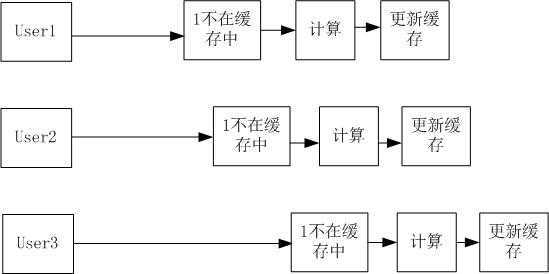
因此我们就想,能不能先更新缓存再去计算呢,这样不就可以消除了重复计算吗?听起来不错,可是我们如何在更新了缓存后获取计算结果呢(因为这时计算还没有完成)?这里就要用到JDK提供的Future和Callable接口,Callable接口和Runnable接口一样,是线程任务的抽象接口,不同的是Callable的call方法可以返回一个Future对象,而Future对象的get方法会阻塞等待任务执行结果。既然有这么好的基础设施,那我们赶紧开撸:
public class BasicCache3<A,V> implements Compute<A, V> { private final Map<A, Future<V>> cache=new ConcurrentHashMap(); private final Compute<A, V> c; private ExecutorService executors=Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()+1); public BasicCache3(Compute<A, V> c) { this.c=c; } @Override public V compute(final A args) throws Exception { Future<V> ans=cache.get(args); if(ans==null) { Callable<V> computeTask=new Callable<V>() { @Override public V call() throws Exception { return c.compute(args); } }; ans= executors.submit(computeTask); cache.put(args, ans); } return ans.get(); } }
上面这段代码里把计算任务提交到线程池去执行,返回了一个结果句柄供后面获取计算结果。可是仔细观察后,我们发现似乎还是有点不对,这样似乎减小了重复计算的概率,但是其实只是减小了发生的窗口,因为判断是否在缓存中和put到缓存中两个操作虽然单独都是线程安全的,但是还是会发生先到达的请求还没来得及put到缓存的情况,而其本质原因就是先检查再插入这样的复杂操作不是原子操作,就好比++这个操作,CPU需要先取原值,再操作加数,最后写回原值也会出现后一次写入覆盖前一次的情况,本质都是因为复杂操作的非原子性。下图演示了这种情况:
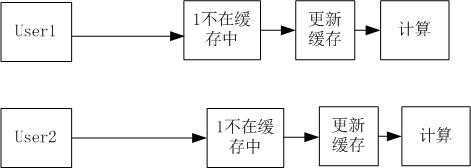
因此JDK中的ConcurrentMap接口提供了putIfAbsent的原子操作方法,可是如果我们像前一个例子中一样先获取计算结果的Future句柄,即便是我们不会重复更新缓存,计算任务还是会执行,依然没达到缓存的效果,因此我们需要一个能够在任务还没启动就可以获取结果句柄,同时能够自由控制任务的启动、停止的东西。当然JDK里也有这样的东西(这里插一句,JDK的concurrent包的代码基本都是Doug Lea写的,老头子代码写的太牛逼了),就是FutureTask,既然如此,赶紧开撸:
public class BasicCache4<A,V> implements Compute<A, V> { private final ConcurrentMap<A, Future<V>> cache=new ConcurrentHashMap<>(); private final Compute<A, V> c; public BasicCache4(Compute<A, V> c) { this.c=c; } @Override public V compute(final A args) throws Exception { Future<V> ans=cache.get(args); if(ans==null) { Callable<V> computeTask=new Callable<V>() { @Override public V call() throws Exception { return c.compute(args); } }; FutureTask<V> ft=new FutureTask<V>(computeTask); ans=cache.putIfAbsent(args, ft); if(ans==null)// { ans=ft; ft.run(); } } return ans.get(); } }
上面这段代码中,我们创建了一个FutureTask任务,但是并没有立即执行这个异步任务,而是先调用ConcurrentHashMap的putIfAbsent方法来尝试把结果句柄更新到缓存中去,这个方法的返回值是Map中的旧值,因此如果返回的是null,也就是说原来缓存中不存在,那我们就启动异步计算任务,而如果缓存中已经存在的话,我们就直接调用缓存中的Future对象的get方法获取计算结果,如果其他请求中的计算任务还没有执行完毕的话,get方法会阻塞直到计算完成。实际运行效果见下图:

至此,我们算是构建了一个有效线程安全的缓存了,当然这个版本其实还是会有很多问题,比如如果异步计算任务被取消的话,我们应该循环重试,但是一方面我们为了简单只考虑了正常情况,另一方面FutureTask是局部变量,在线程栈层面已经保证了其他线程或代码无法拿到该对象。最后用一张xmind图作为总结:

参考资料:《Java Concurrency in Practice》
标签:style blog http io ar color 使用 sp java
原文地址:http://www.cnblogs.com/developerY/p/4150057.html