标签:des style blog http io ar color os 使用
前段时间遇到很多例统计信息更新不及时导致执行计划较差引发性能问题的情况,现在总结分析下,与各位分享。
问题描述:
订单表用于存放用户订单信息,其中有字段DT存放订单的创建时间,PID存放用户编号,根据业务需求,我们分别创建在列DT上索引IDX_DT,在PID上创建索引IDX_PID,我们通常会在业务低峰期进行索引维护和统计更新,在双11期间,订单暴增而统计信息没有得到及时更新,部分查询选用了不合适的索引,导致性能较差。
问题演示:
首先我们生成100W的数据,并将统计更新到最新。
DROP TABLE TB001 GO CREATE TABLE TB001 ( ID INT IDENTITY(1,1) PRIMARY KEY, PID INT DEFAULT 0, DT DATETIME DEFAULT GETDATE(), CT CHAR(500) DEFAULT ‘0‘ ) GO --导入100W数据 INSERT INTO TB001(CT) SELECT TOP(20000) T2.name FROM sys.all_columns T2 CROSS JOIN sys.all_objects T1 GO 50 --更新DT字段 UPDATE TB001 SET DT=DATEADD(MINUTE,ID,GETDATE()), PID=ID%100000 GO --创建索引 CREATE INDEX IDX_PID ON TB001(PID) CREATE INDEX IDX_DT ON TB001(DT) GO
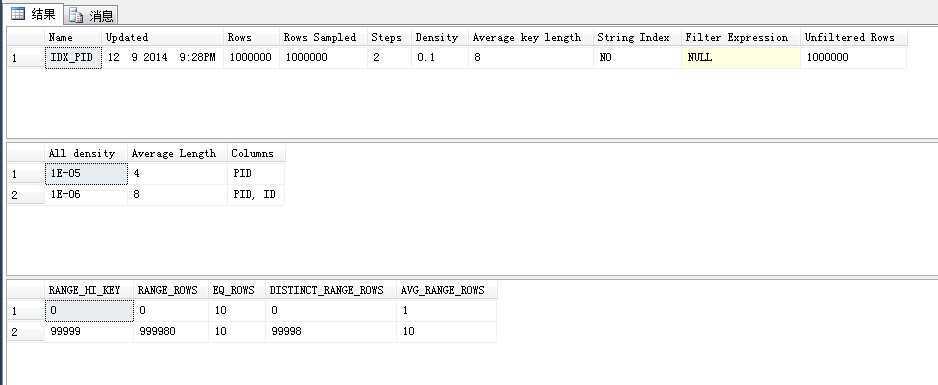
查看PID上统计信息
DBCC SHOW_STATISTICS(‘TB001‘,‘IDX_PID‘)
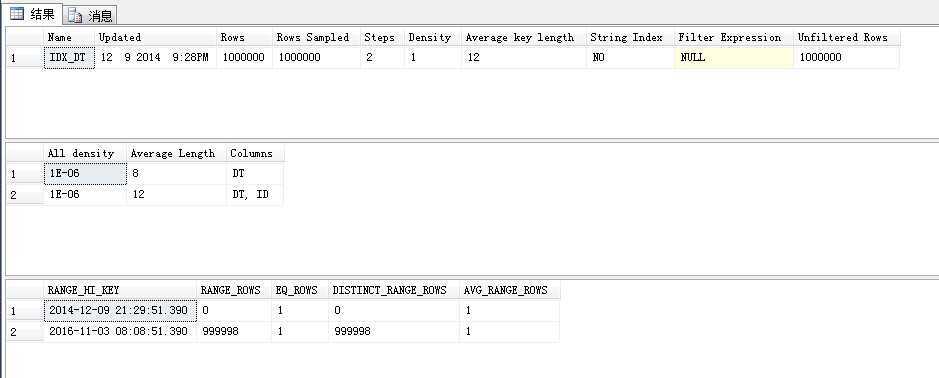
查看DT上的统计信息
DBCC SHOW_STATISTICS(‘TB001‘,‘IDX_DT‘)
然后模拟新增15W数据,新增的数据的创建时间均大于统计生成的时间。
INSERT INTO TB001(PID,DT,CT) SELECT RID%100000, DATEADD(MINUTE,1000000+RID,GETDATE()), name FROM( SELECT ROW_NUMBER()OVER(ORDER BY name) AS RID, name FROM ( SELECT TOP(150000) T2.name FROM sys.all_columns T2 CROSS JOIN sys.all_objects T1 ) AS T3 ) AS T4
查看最后5w订单的时间
SELECT MAX(DT) AS MAX_DT, MIN(DT) AS MIN_DT FROM ( SELECT TOP(50000) * FROM TB001 ORDER BY id DESC ) AS T1

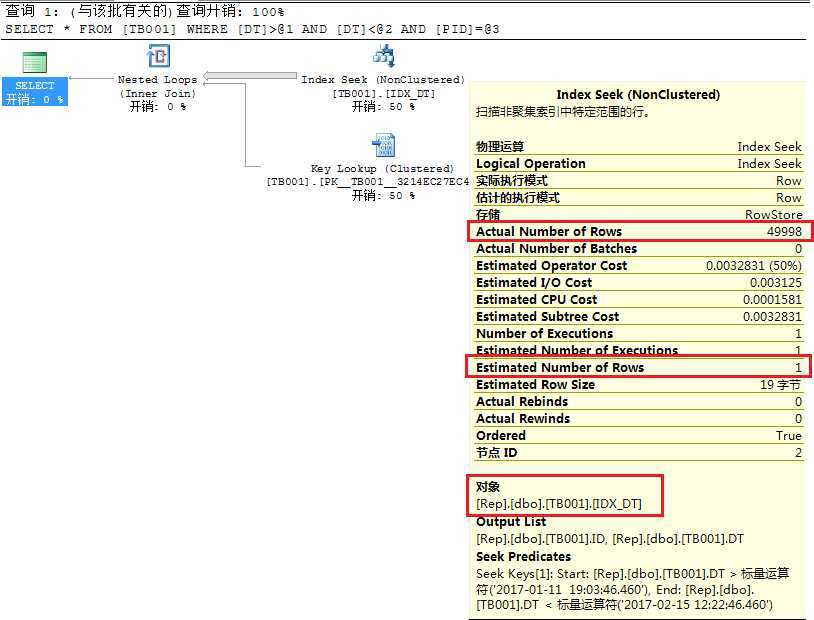
虽然在订单表中新增了15W订单呢,但是这15万订单被平均分摊,每个用户只新增1.5个订单,每个用户平均有11.5个订单,因此如果要查询2016-09-29 14:39:52.973到2016-11-03 07:58:52.973期间某个用户的订单的话,走IDX_PID会是最佳选择,但执行计划选择了IDX_DT的索引。
--表 ‘TB001‘。扫描计数 1,逻辑读取 150109 次,物理读取 0 次,预读 0 次, --lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SELECT * FROM TB001 WHERE DT>‘2017-01-11 19:03:46.460‘ AND DT<‘2017-02-15 12:22:46.460‘ AND PID=10
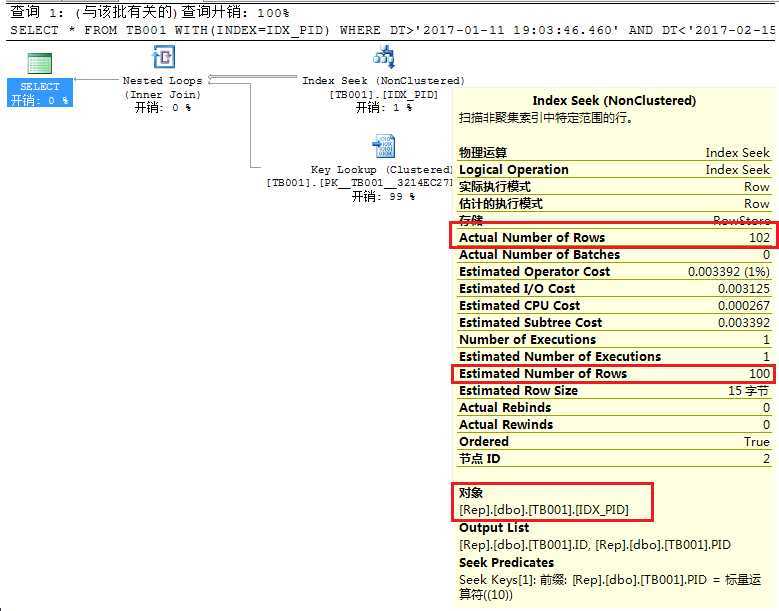
如果我们强制执行计划走索引:
--表 ‘TB001‘。扫描计数 1,逻辑读取 324 次,物理读取 0 次,预读 0 次, --lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SELECT * FROM TB001 WITH(INDEX=IDX_PID) WHERE DT>‘2017-01-11 19:03:46.460‘ AND DT<‘2017-02-15 12:22:46.460‘ AND PID=10
或修改查询,避免使用索引IDX_DT:
--表 ‘TB001‘。扫描计数 1,逻辑读取 324 次,物理读取 0 次,预读 0 次, --lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SELECT * FROM TB001 WITH(INDEX=IDX_PID) WHERE DT+0>‘2017-01-11 19:03:46.460‘ AND DT+0<‘2017-02-15 12:22:46.460‘ AND PID=10
--=====================================================================
在SQL SERVER 2014之间版本中,对于超出统计信息范围的参数,基数评估认为其不存在,评估行数为1。在Demo中,由于DT的两个参数均不在统计信息IDX_DT的直方图范围内,认为满足DT条件的数据为1,因此认定为使用IDX_DT索引为最优。
此类问题针对的是递增类型的数据,如自增ID,创建时间,货物批号等,随着时间推移,新增的数据总是超出统计信息的范围,当查询这些新增数据并且执行计划重新生成时,就可能导致执行计划出现问题,这也是我们常说的“统计信息未及时更新导致执行计划问题”。
--=====================================================================
解决办法:
1. 对递增类数据提高统计的更新频率(更新频率过快也是问题啊)
2. 升级到2014版本(在CdinalityEstimationModeVersion=120下,会采用新的预估算法,不过谁无事玩升级啊)
3. 使用查询提示强制使用索引(是个办法,一般也不这么玩)
4. 修改SQL(我目前采用的办法,使查询无法使用索引IDX_DT)
--====================================================================
很早拜读过群里一位大神Fanr_Zh的博客《SQL Server 2014新特性——基数评估(白皮书阅读笔记)》,感悟颇多,结合最近遇到的一些性能问题,弄个Demo与各位看官一起学习下!再次拜谢下Fanr。
--====================================================================
标签:des style blog http io ar color os 使用
原文地址:http://www.cnblogs.com/TeyGao/p/4154803.html