标签:style blog http io ar color os 使用 sp
1.CompressionCodecFactory简介
当在读取一个压缩文件的时候,可能并不知道压缩文件用的是哪种压缩算法,那么无法完成解压任务。在Hadoop中,CompressionCodecFactory通过使用其getCodec()方法,可以通过文件扩展名映射到一个与其对应的CompressionCodec类,如README.txt.gz通过getCodec()方法后,GipCodec类。关于Hadoop的压缩,可以参考我的博文《Hadoop压缩》http://www.cnblogs.com/robert-blue/p/4155710.html
实例:使用由文件扩展名推断而来的codec来对文件进行解压缩
1 package cn.roboson.codec; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FSDataInputStream; 7 import org.apache.hadoop.fs.FSDataOutputStream; 8 import org.apache.hadoop.fs.FileStatus; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IOUtils; 12 import org.apache.hadoop.io.compress.CompressionCodec; 13 import org.apache.hadoop.io.compress.CompressionCodecFactory; 14 import org.apache.hadoop.io.compress.CompressionInputStream; 15 16 /* 17 * 通过CompressionCodeFactory推断CompressionCodec 18 * 1.先从本地上传一个.gz后缀的文件到Hadoop 19 * 2.通过文件后缀推断出所用的压缩算法 20 * 3.解压上传的压缩文件到统一个目录下 21 */ 22 public class StreamCompressor02 { 23 24 public static void main(String[] args) { 25 26 Configuration conf = new Configuration(); 27 conf.addResource("core-site.xml"); 28 29 try { 30 FileSystem fs = FileSystem.get(conf); 31 32 //本地文件 33 String localsrc="/home/roboson/桌面/README.txt.gz"; 34 Path localPath= new Path(localsrc); 35 36 //目的处路径 37 String hadoopdsc="/roboson/README.txt.gz"; 38 Path hadoopPath = new Path(hadoopdsc); 39 40 //复制前/roboson目录下的文件列表 41 FileStatus[] files = fs.listStatus(new Path("/roboson/")); 42 System.out.println("复制前:"); 43 for (FileStatus fileStatus : files) { 44 System.out.println(fileStatus.getPath()); 45 } 46 47 //复制本地文件到Hadoop文件系统中 48 fs.copyFromLocalFile(localPath,hadoopPath); 49 50 //复制后/roboson目录下的文件列表 51 files = fs.listStatus(new Path("/roboson/")); 52 System.out.println("复制后:"); 53 for (FileStatus fileStatus : files) { 54 System.out.println(fileStatus.getPath()); 55 } 56 57 //获得一个CompressionCodecFactory实例来推断哪种压缩算法 58 CompressionCodecFactory facotry = new CompressionCodecFactory(conf); 59 60 //通过CompressionCodecFactory推断出一个压缩类,用于解压 61 CompressionCodec codec =facotry.getCodec(hadoopPath); 62 if(codec==null){ 63 System.out.println("没有找到该类压缩"); 64 System.exit(1); 65 } 66 67 /* 68 * 1.CompressionCodecFactory的removeSuffix()用来返回一个文件名,这个文件名==压缩文件的后缀名去掉 69 * 如README.txt.gz调用removeSuffix()方法后,返回的是README.txt 70 * 71 * 2.CompressionCodec的getDefaultExtension()方法返回的是一个压缩算法的压缩扩展名,如gzip的是.gz 72 */ 73 String uncodecUrl=facotry.removeSuffix(hadoopdsc, codec.getDefaultExtension()); 74 System.out.println("压缩算法的生成文件的扩展名:"+codec.getDefaultExtension()); 75 System.out.println("解压后生成的文件名:"+uncodecUrl); 76 77 //在Hadoop中创建解压后的文件 78 FSDataOutputStream out = fs.create(new Path(uncodecUrl)); 79 80 //创建输入数据流,并用CompressionCodec的createInputStream()方法,将输入数据流中读取的数据解压 81 FSDataInputStream in = fs.open(new Path(hadoopdsc)); 82 CompressionInputStream codecIn = codec.createInputStream(in); 83 84 //将输入数据流写入到 输出数据流 85 IOUtils.copyBytes(codecIn, out, conf,true); 86 87 //解压后/roboson目录下的文件列表 88 files = fs.listStatus(new Path("/roboson/")); 89 System.out.println("解压后"); 90 for (FileStatus fileStatus : files) { 91 System.out.println(fileStatus.getPath()); 92 } 93 94 //查看解压后的内容 95 System.out.println("解压后的内容:"); 96 in=fs.open(new Path(uncodecUrl)); 97 IOUtils.copyBytes(in,System.out, conf,true); 98 } catch (IOException e) { 99 // TODO Auto-generated catch block 100 e.printStackTrace(); 101 } 102 } 103 }
运行结果:
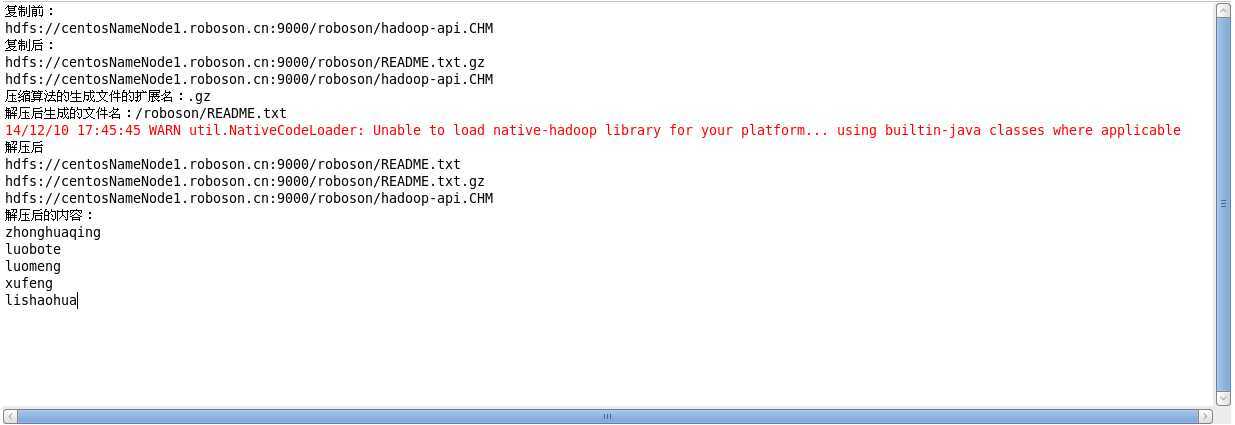
2.原生类库
什么是 原生类库?就是本地类库(native),例如,Java也有实现的压缩和解压,但是如上所示,用到的gzip并非java实现,而是Linux系统自带的,我们都知道gzip是Linux中常用的压缩工具。Hadoop本身包含有32位和64位Linux构建的压缩代码库(位于lib/native目录)。对于其它平台,需要根据Hadoop wiki的指令更具需要来编译代码库。
可以通过Java系统的java.library.path属性来指定原生代码库。bin文件夹中的hadoop脚本可以设置这个属性。默认情况下,Hadoop会根据自身运行的平台搜索原生代码库,如果找到相应的代码库就会自动加载。所以,无需为了使用原声代码库而修改任何设置。还有为了性能,最好使用原生类库来实现压缩和解压缩,因为效率更高!Hadoop中的压缩哪些是原生实现的,哪些是Java实现的?
| 压缩格式 | Java实现 | 原生实现 |
| DEFLATE | 是 | 是 |
| gzip | 是 | 是 |
| gzip2 | 是 | 否 |
| LZO | 否 |
是 |
Hadoop压缩之CompressionCodecFactory
标签:style blog http io ar color os 使用 sp
原文地址:http://www.cnblogs.com/robert-blue/p/4156117.html