标签:style blog http io ar color sp for java
需求
去除掉海量文件中的存在着的重复数据,并将结果输出到单个文件中。
比如有文件1中有以下数据:
hello
my
name
文件2中有以下数据
my
name
is
文件3中有以下数据
name
is
fangmeng
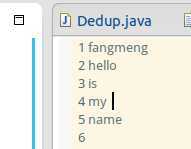
那么结果文件的内容应当如下(顺序不保证一致):
hello
my
name
is
fangmeng
方案制定
Map阶段:
1. 获取到输入后,按照默认原则切分输入。
2. 将切分后的value设置为map中间输出的key,而map中间输出的value为空值。
Shuffle阶段让具有相同的key的map中间输出汇集到同一个reduce节点上
Reduce阶段:
将获取到的键值对的第一个键取出,作为reduce输出的键,值依然为空,或者你也可以输出键值对的个数。
注意是第一个键。因为会传递过来很多键值对 - 他们都有同样的键,只用选取第一个键就够了。
这和其他案例中需要依次遍历Shuffle阶段传递过来的中间键值对进行计算的模式是不同的。
代码示例
1 package org.apache.hadoop.examples; 2 3 import java.io.IOException; 4 5 //导入各种Hadoop包 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 import org.apache.hadoop.util.GenericOptionsParser; 15 16 // 主类 17 public class Dedup { 18 19 // Mapper类 20 public static class Map extends Mapper<Object, Text, Text, Text>{ 21 22 // new一个值为空的Text对象 23 private static Text line = new Text(); 24 25 // 实现map函数 26 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 27 28 // 将切分后的value作为中间输出的key 29 line = value; 30 context.write(line, new Text("")); 31 } 32 } 33 34 // Reducer类 35 public static class Reduce extends Reducer<Text,Text,Text,Text> { 36 37 // 实现reduce函数 38 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 39 40 // 仅仅输出第一个Key 41 context.write(key, new Text("")); 42 } 43 } 44 45 // 主函数 46 public static void main(String[] args) throws Exception { 47 48 // 获取配置参数 49 Configuration conf = new Configuration(); 50 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 51 52 // 检查命令语法 53 if (otherArgs.length != 2) { 54 System.err.println("Usage: Dedup <in> <out>"); 55 System.exit(2); 56 } 57 58 // 定义作业对象 59 Job job = new Job(conf, "Dedup"); 60 // 注册分布式类 61 job.setJarByClass(Dedup.class); 62 // 注册Mapper类 63 job.setMapperClass(Map.class); 64 // 注册合并类 65 job.setCombinerClass(Reduce.class); 66 // 注册Reducer类 67 job.setReducerClass(Reduce.class); 68 // 注册输出格式类 69 job.setOutputKeyClass(Text.class); 70 job.setOutputValueClass(Text.class); 71 // 设置输入输出路径 72 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); 73 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); 74 75 // 运行程序 76 System.exit(job.waitForCompletion(true) ? 0 : 1); 77 } 78 }
运行结果
小结
去重在日志分析中有非常广泛的应用,本例也是MapReduce程序的一个经典范例。
标签:style blog http io ar color sp for java
原文地址:http://www.cnblogs.com/scut-fm/p/4158062.html