(Michael Collins的自然语言处理课程讲义,哥伦比亚大学)
在这一节,我们将考虑一个问题,即如何为一个例句集建立语言模型。语言模型最初从语音识别发展起来;对现代的语言识别系统,语言模型依然起着中心作用。语言模型在其他自然语言处理应用中也被广泛应用。我们将在本章讨论参数估计技术。参数估计技术最初为语言模型而生,在很多场合都有用,譬如在接下来的章节中将会讨论到的标注问题和句法分析问题。
我们的任务如下。假设我们有一个语料库——某特定语言的句子集。譬如说,我们可能持有泰晤士报数年内的文档,又或者我们可能拥有非常大量的网络文档。基于这些语料,我们希望评估一个语言模型的参数。
语言模型定义如下。首先,我们将该门语言中的所有单词组成的集合定义为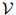 。例如,当我们为英语建立语言模型时,我们可能会有
。例如,当我们为英语建立语言模型时,我们可能会有
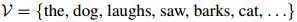
在实际应用中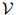 可以是很大的:它可能包含数千甚至数万个单词。我们假设
可以是很大的:它可能包含数千甚至数万个单词。我们假设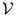 是一个有限集。该语言的一个句子就是一个单词序列
是一个有限集。该语言的一个句子就是一个单词序列
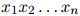
其中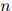 满足
满足 ,且
,且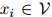 ,
,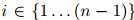 ,且假定
,且假定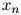 是一个特殊符号——STOP(我们假定STOP并非
是一个特殊符号——STOP(我们假定STOP并非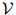 中的元素)。我们将会看到为什么让每个句子以STOP结束是方便的。以下是一些例句:
中的元素)。我们将会看到为什么让每个句子以STOP结束是方便的。以下是一些例句:

我们将定义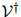 作为取词于
作为取词于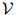 的句子的集合:这是一个无限集,因为句子可以是任意长度的。
的句子的集合:这是一个无限集,因为句子可以是任意长度的。
我们接着给出如下定义:
定义1 (语言模型) 一个语言模型由一个有限集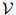 ,以及一个函数
,以及一个函数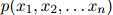 构成,其中
构成,其中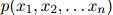 满足:
满足:
1. 对任意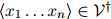 ,
,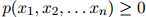
2. 此外,
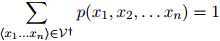
因此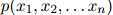 是
是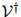 中句子的概率分布。
中句子的概率分布。
对从训练语料库中学习语言模型的一种(非常差劲的)方法,我们考虑如下。将句子 在训练语料库中出现的次数定义为
在训练语料库中出现的次数定义为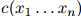 ,训练语料库的句子总数为
,训练语料库的句子总数为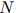 。于是我们可以将
。于是我们可以将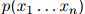 定义为
定义为
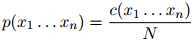
然而,这是一个非常差劲的模型:具体地说,它会将任何未在训练语料库中出现过的句子的概率赋为0。因此它无法遍及那些未在训练语料库中出现过的句子。本章的主要技术贡献就是介绍可以遍及未在训练语料库中出现过的句子的方法。
乍看起来语言模型问题是一个特别奇怪的任务,那么究竟我们为什么要考虑这个问题?有几个理由:
1.
语言模型在非常广泛的应用中都有着重要作用,最明显的或许是语音识别和机器翻译。在很多应用中,获得一个好的先验分布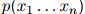 来描述句子在该种语言中是否可能,是非常有用的。例如,在语音识别中,语言模型与一个语音模型绑定,语音模型是为单词发音而建的模型:想象这种语言模型的一个方法是,语音模型生成大量候选句子,每个句子都附带着一个概率值;语言模型则基于每个句子在该种语言中有是否更有可能是一个句子,来重新分配概率。
来描述句子在该种语言中是否可能,是非常有用的。例如,在语音识别中,语言模型与一个语音模型绑定,语音模型是为单词发音而建的模型:想象这种语言模型的一个方法是,语音模型生成大量候选句子,每个句子都附带着一个概率值;语言模型则基于每个句子在该种语言中有是否更有可能是一个句子,来重新分配概率。
2.
我们所讨论的技术,即用于定义函数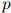 以及用于评估从训练用例中习得的语言模型的参数的技术,将会在课程中提到的其他几个场合下非常有用:例如在我们即将讲到的隐马尔可夫模型中,以及用于语法分析的语言模型中,都非常有用。
以及用于评估从训练用例中习得的语言模型的参数的技术,将会在课程中提到的其他几个场合下非常有用:例如在我们即将讲到的隐马尔可夫模型中,以及用于语法分析的语言模型中,都非常有用。
现在我们转到一个重要问题:给定一个训练语料库,我们怎样训练出函数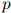 ?在这一节我们讨论概率论中的一个核心概念——马尔可夫模型;在下一节,我们讨论三元语言模型,三元模型是直接建立在马尔可夫模型之上的一类语义模型。
?在这一节我们讨论概率论中的一个核心概念——马尔可夫模型;在下一节,我们讨论三元语言模型,三元模型是直接建立在马尔可夫模型之上的一类语义模型。
考虑一个随机变量序列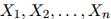 。每一个随机变量值可以取有限集
。每一个随机变量值可以取有限集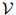 中的任意值。现在我们假设序列的长度
中的任意值。现在我们假设序列的长度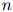 是一个固定的数(例如,
是一个固定的数(例如, )。在下一节我们将描述怎样将处理方法一般化到
)。在下一节我们将描述怎样将处理方法一般化到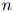 本身也是随机变量的情况,从而允许不同序列拥有不同的长度。
本身也是随机变量的情况,从而允许不同序列拥有不同的长度。
我们的目标如下:我们希望为任何序列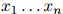 的概率建模,其中
的概率建模,其中 且
且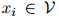 ,
,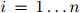 。换言之,就是为如下联合概率建模:
。换言之,就是为如下联合概率建模:
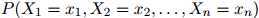
形如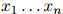 的可能序列有
的可能序列有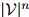 个:所以很明显,对合理的
个:所以很明显,对合理的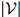 和
和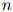 ,罗列所有
,罗列所有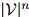 个概率值,并不是一个可行的方法。我们希望建立一个更为强大的模型。
个概率值,并不是一个可行的方法。我们希望建立一个更为强大的模型。
在一阶马尔科夫过程中,我们作如下假设,即将模型简化为:
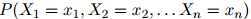
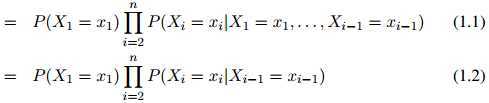
第一步,即公式1.1,是准确的计算方法:根据概率的链式法则,任意分布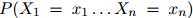 都可以写成这个形式。因此我们在这一步的推演中并没有做出任何假设。然而,第二步,即公式1.2,并不必然是准确的计算方法:我们作出了如下假设,即对任意
都可以写成这个形式。因此我们在这一步的推演中并没有做出任何假设。然而,第二步,即公式1.2,并不必然是准确的计算方法:我们作出了如下假设,即对任意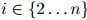 ,任意的
,任意的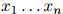 ,有
,有
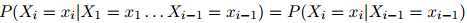
这是其中一个(一阶)马尔可夫假设。我们假设序列中第 个单词的特征仅依赖与它前一个单词,
个单词的特征仅依赖与它前一个单词,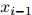 。更规范地说,给定
。更规范地说,给定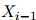 的值,我们假设
的值,我们假设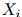 的值条件独立于
的值条件独立于 。
。
在一个二阶马尔可夫过程(二阶马尔可夫过程是建立三元语言模型的基础)中,我们作出一个略微弱一点的假设,即认为序列中的每个单词只依赖于其前两个单词:
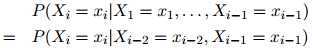
从而整个序列的概率写成
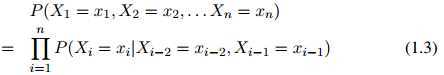
为了方便,在定义中,我们假设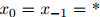 ,其中
,其中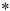 是句子中一个特殊的"星"号。
是句子中一个特殊的"星"号。
在上一节,我们假设句子的长度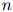 是固定的。然而在很多应用中,
是固定的。然而在很多应用中,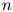 是可变的。因此
是可变的。因此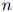 本身也是一个随机变量。为这个长度变量建模的方法有很多:在本节我们讨论一种最为普遍的语言建模方法。
本身也是一个随机变量。为这个长度变量建模的方法有很多:在本节我们讨论一种最为普遍的语言建模方法。
方法是简单的:我们假设序列中第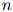 个单词
个单词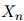 总是等于一个特殊符号——STOP。这个符号只可出现在序列的末尾。我们使用与前面提到的完全相同的假设:例如在二阶马儿可夫假设下,我们有
总是等于一个特殊符号——STOP。这个符号只可出现在序列的末尾。我们使用与前面提到的完全相同的假设:例如在二阶马儿可夫假设下,我们有
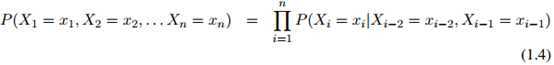
对任意的 和任意
和任意 都成立。其中
都成立。其中 满足
满足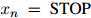 且
且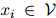 ,
, 。
。
我们已经假设了一个二阶马尔可夫过程,在这个二阶马尔可夫过程中,我们根据如下分布生成符号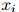 :
:
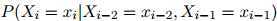
其中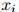 为
为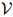 中元素,或者,如果它居于句末的话,是一个STOP符号。如果我们生成了STOP符号,那么我们就已经生成了整个序列。否则,我们接着生成序列中的下一个符号。
中元素,或者,如果它居于句末的话,是一个STOP符号。如果我们生成了STOP符号,那么我们就已经生成了整个序列。否则,我们接着生成序列中的下一个符号。
更规范一点来说,生成句子的过程如下:
1. 初始化 ,
,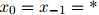
2. 根据如下分布生成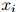 :
:
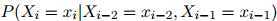
3. 如果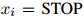 ,返回序列
,返回序列 。否则,令
。否则,令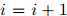 ,并转到第2步。
,并转到第2步。
至此,我们已经拥有了一个能够生成不定长序列的模型。
第一章1.2节完。
原文页面:http://www.cs.columbia.edu/~mcollins/lm-spring2013.pdf
课程主页:http://www.cs.columbia.edu/~cs4705/
Michael
Collins的个人主页:http://www.cs.columbia.edu/~mcollins/
Michael Collins自然语言处理课程讲义(翻译:Trey),布布扣,bubuko.com
Michael Collins自然语言处理课程讲义(翻译:Trey)
原文地址:http://www.cnblogs.com/treyscience/p/3740100.html