标签:style blog http ar color sp strong on 文件
前言
从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情。
那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易" 地实现分布式运行?
Map/Reduce 任务执行总流程
经过之前的学习,我们已经知道一个 Map/Reduce 作业的总流程为:
代码编写 --> 作业配置 --> 作业提交 --> Map任务的分配和执行 --> 处理中间结果(Shuffle) --> Reduce任务的分配和执行 --> 作业完成
如下图所示:
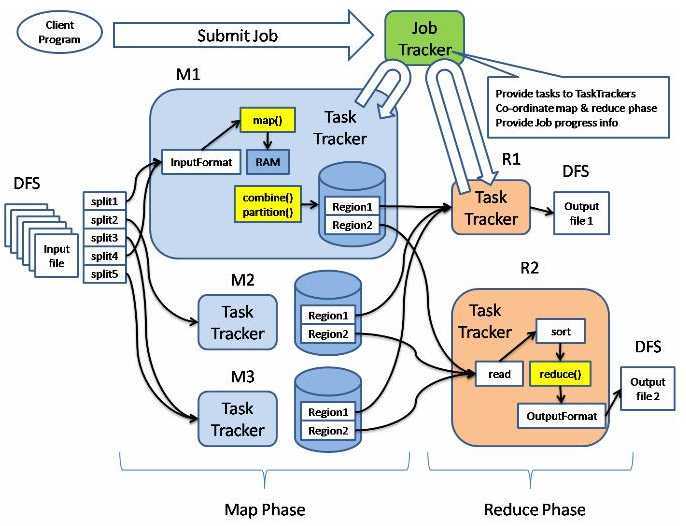
Map/Reduce 框架中的四大实体
1. 客户端
负责编写代码,配置作业,提交作业。任何节点都可以充当客户端。
2. JobTracker (1个)
作业中心控制节点,一般一个集群就一个JobTracker。
3. TaskTracker (很多个)
作业具体执行节点,可以分为Map节点和Reduce节点两大类。
4. HDFS
分布式文件系统,保存从作业提交到完成需要的各种信息。
阶段一:提交作业阶段
1. 首先,开发人员编写好程序代码,配置好输入输出路径,Key/Value 类型等等。(这部分是人为控制阶段,接下来的所有操作都是Hadoop完成的了)
2. 从JobTracker处获取当前的作业ID号
3. 检查配置合法性 (如输入目录是否存在等)
4. 计算作业的输入划分,并将划分信息写入到Job.split文件。
5. 将运行作业需要的所有资源都复制到HDFS上。
6. 通知JobTracker准备完毕,可以执行作业了。
阶段二:初始化作业阶段
这个阶段,JobTracker将为作业创建一个对象,专门监控它的运行。
并根据Job.split文件(上一步生成)来创建并初始化Map任务和Reduce任务。
阶段三:分配任务
JobTracker和TaskTracker之间通信和任务分配是通过心跳机制来完成的,每个TaskTracker作为一个单独的JVM执行一个简单的循环。
TaskTracker每隔一段时间都会向JobTracker汇报它的任务进展报告,JobTracker在收到进展报告以后如果发现任务完成了,就会给它再分配新的任务。
一般来说TaskTracker有个任务槽,它是有容量限制的 - 只能装载一定个数的Map/Reduce任务。
这一步和下一步,就形成一次心跳。
阶段四:执行任务
这一步的主体是TaskTracker,主要任务是实现任务的本地化。
具体步骤如下:
1. 将job.split复制到本地
2. 将job.jar复制到本地
3. 将job的配置信息写入到job.xml
4. 创建本地任务目录,解压job.jar
5. 发布任务并在新的JVM里执行此任务。
6. 最后将计算结果保存到本地缓存
小结
本文细致分析了Map/Reduce的作业执行流程。
但在流程的执行过程当中,数据的具体流动途径也是需要仔细分析的 - 是存放在本地磁盘,还是HDFS?
另外,还需要做好错误处理 - 比如说某个节点坏了怎么办?
这些将在后面的两篇文章中做出分析和介绍。
标签:style blog http ar color sp strong on 文件
原文地址:http://www.cnblogs.com/scut-fm/p/4160080.html