标签:style blog http io ar color 使用 sp strong
Hadoop数据管理介绍及原理分析
最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个他解释为个人习惯问题,也是,外国人左手写字的为数不少,在中国,左撇子在小时候的父母眼中就是“异类”,早早的被矫正过来。废话不多说了,接下来介绍Hadoop的数据管理。
Hadoop的数据管理,主要包括Hadoop的分布式文件系统HDFS、分布式数据库HBase和数据仓库工具Hive。
HDFS的数据管理
HDFS是分布式计算的存储基石,它以流式数据访问模式来存储超大文件,运行于商用硬件集群上。下面介绍一下它的设计:
1.超大文件:此指具有几百MB、几百GB甚至几百TB大小的文件,目前已经具有存储PB级数据的Hadoop集群了。
2.流式数据访问:HDFS的构建思路是这样的,一次写入,多次读取时最高效的访问模式,数据集通常由数据源生成或从数据源复制而来,接着长时间在此数据集上进行各种分析。
3.商用硬件:Hadoop并不需要运行在昂贵且高可靠的硬件上。它是设计运行在商用硬件的集群上的,因此节点故障率还是很高的,当遇到故障被设计成能继续运行且不让用户感到明显的中断。
4.低时间延迟的数据访问。
5.大量的小文件。
6.多用户写入,任意修改文件。
下面看下HDFS体系结构图:
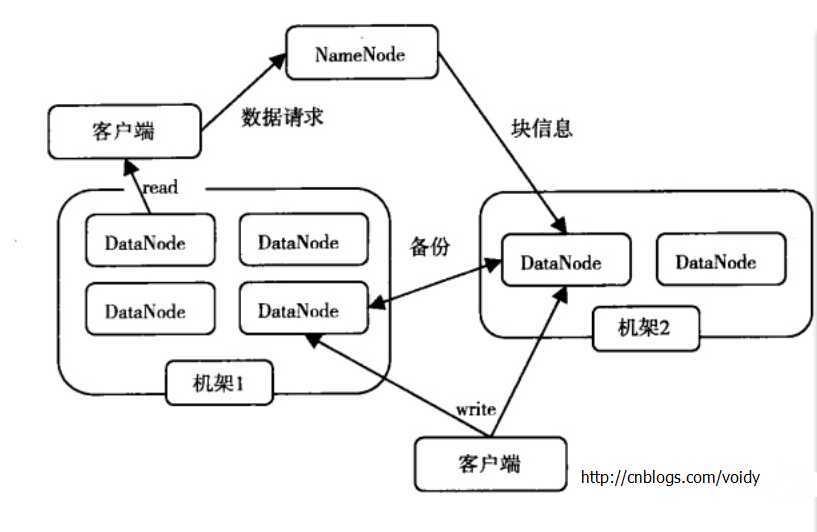
图中涉及三个角色:NameNode、DataNode、Client。
NameNode是管理者:主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。
DataNode是文件存储者:是文件存储的基本单元,它将文件块(Block)存储在本地文件系统中,保存了所有的Block的Metadata,同时周期性的把所有存在的Block信息发送给NameNode。
Client:是需要获取分布式文件系统的应用程序。
文件写入:
1. Client向NameNode发起文件写入的请求。
2. NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息。
3. Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
文件读取:
1. Client向NameNode发起读取文件的请求。
2. NameNode返回文件存储的DataNode信息。
3. Client读取文件信息。
HDFS作为分布式文件系统在数据管理方面可借鉴点:
1.文件块的放置:一个Block会有三份备份,一份在NameNode指定的DateNode上,一份放在与指定的DataNode不在同一台机器的DataNode上,一根在于指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题。
2.心跳检测:用于检测DataNode健康状况,如有问题就进行数据备份。
3.数据复制。
4.数据校验。
5.单个NameNode:若单个失败,任务处理信息会记录在本地文件系统和远端的文件系统中。
6.数据管道性的写入。
7.安全模式:文件系统启动即进入安全模式。此模式主要是为了在系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略进行必要的复制或删除部分数据块。
HBase的数据管理
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。列名字的格式是:"<family>:<label>”。
HBase在分布式集群主要依靠HRegion、HMaster、Hclient组成的体系结构从整体上管理数据。
HBaseMaster:HBase的主服务器,与Bigtable的主服务器类似。一个HBase只部署一台主服务器,它通过领导选举算法(Leader Election Algorithm)确保只有一台主服务器是活跃的,如果主服务器瘫痪,可以通过LEA算法从备选的服务器再选择一台。主要承担初始化集群的任务。
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HRegionServer:HBase域服务器,与Bigtable的Tablet服务器类似。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HBase Client:HBase客户端是由org.apache.hadooop.HBase.client.HTable定义的。用于查找用户域所在的服务器地址,HBase客户端会与HBase主机交换消息以查找根域的位置,这是两者之间唯一的交流。
HBase工作原理:
首先HBase Client端会连接Zookeeper Qurom。通过Zookeeper组件Client能获知哪个Server管理-ROOT-Region。那么Client就去访问管理-ROOT-的Server,在META中记录了HBase中所有表信息,(你可以使用 scan ‘.META.‘ 命令列出你创建的所有表的详细信息),从而获取Region分布的信息。一旦Client获取了这一行的位置信息,比如这一行属于哪个Region,Client将会缓存这个信息并直接访问HRegionServer。久而久之Client缓存的信息渐渐增多,即使不访问.META.表也能知道去访问哪个HRegionServer。HBase中包含两种基本类型的文件,一种用于存储WAL的log,另一种用于存储具体的数据,这些数据都通过DFS Client和分布式的文件系统HDFS进行交互实现存储。
Hive数据管理
Hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,用来进行数据提取、转换、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据机制。可以把Hadoop下结构化数据文件映射为一张成Hive中的表,并提供类sql查询功能,除了不支持更新、索引和事务,sql其它功能都支持。可以将sql语句转换为MapReduce任务进行运行,作为sql到MapReduce的映射器。提供shell、JDBC/ODBC、Thrift、Web等接口。优点:成本低可以通过类sql语句快速实现简单的MapReduce统计。
下图为Hive数据交换图:
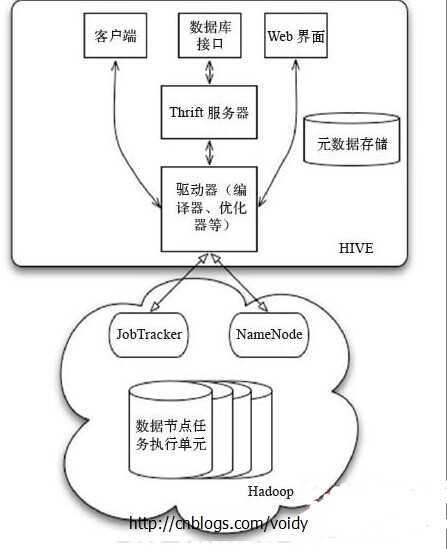
作为一个数据仓库,Hive的数据管理按照使用层次可以从元数据存储、数据存储和数据交换三个方面介绍。
1.元数据存储
Hive将元数据存储在RDBMS中,有三种方式可以连接到数据库:
内嵌模式:元数据保持在内嵌数据库的Derby,一般用于单元测试,只允许一个会话连接
多用户模式:在本地安装Mysql,把元数据放到Mysql内
远程模式:元数据放置在远程的Mysql数据库
2.数据存储
首先,Hive没有专门的数据存储格式,也没有为数据建立索引,用于可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,这就可以解析数据了。
其次,Hive中所有的数据都存储在HDFS中,Hive中包含4中数据模型:Tabel、ExternalTable、Partition、Bucket。
Table:类似与传统数据库中的Table,每一个Table在Hive中都有一个相应的目录来存储数据。例如:一个表zz,它在HDFS中的路径为:/wh/zz,其中wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的Table数据(不含External Table)都保存在这个目录中。
Partition:类似于传统数据库中划分列的索引。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition数据都存储在对应的目录中。
Buckets:对指定列计算的hash,根据hash值切分数据,目的是为了便于并行,每一个Buckets对应一个文件。
ExternalTable指向已存在HDFS中的数据,可创建Partition。和Table在元数据组织结构相同,在实际存储上有较大差异。Table创建和数据加载过程,可以用统一语句实现,实际数据被转移到数据仓库目录中,之后对数据的访问将会直接在数据仓库的目录中完成。删除表时,表中的数据和元数据都会删除。ExternalTable只有一个过程,因为加载数据和创建表是同时完成。世界数据是存储在Location后面指定的HDFS路径中的,并不会移动到数据仓库中。
3.数据交换
用户接口:包括客户端、Web界面和数据库接口。
元数据存储:通常是存储在关系数据库中的,如Mysql,Derby等。
解释器、编译器、优化器、执行器。
Hadoop:用HDFS进行存储,利用MapReduce进行计算。
关键点:Hive将元数据存储在数据库中,如Mysql、Derby中。Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表)、表数据所在的目录等。
Hive的数据存储在HDFS中,大部分的查询由MapReduce完成。
PS:本博客欢迎转发,但请注明博客地址及作者~
博客地址:http://www.cnblogs.com/voidy/
<。)#)))≦
标签:style blog http io ar color 使用 sp strong
原文地址:http://www.cnblogs.com/voidy/p/4162395.html