标签:des style blog http io ar color os sp
继续学习http://www.cnblogs.com/tornadomeet/archive/2013/03/15/2961660.html
题目是:50个数据样本点,其中x为这50个小朋友到的年龄,年龄为2岁到8岁,年龄可有小数形式呈现。Y为这50个小朋友对应的身高,当然也是小数形式表示的。现在的问题是要根据这50个训练样本,估计出3.5岁和7岁时小孩子的身高。
作者已经给出了代码:
采用normal equations方法求解:
1 %%方法一 2 x = load(‘ex2x.dat‘); 3 y = load(‘ex2y.dat‘); 4 plot(x,y,‘*‘) 5 xlabel(‘height‘) 6 ylabel(‘age‘) 7 x = [ones(size(x,2),1),x];%注意这里作者手误了,作者打成了size(x),这是不对的,因为size(x)会出来的x这个向量的两个维 8 %度,我们只需要第一个维度,我们还要再加一列1是因为这里把wx+b变成了w’x这样我们化成齐次的线性方程,所以我们要把x扩成一列1。 9 w=inv(x‘*x)*x‘*y 10 hold on 12 plot(x(:,2),0.0639*x(:,2)+0.7502)%这里的0.7502就是求得的w向量的第一个值,也就是wx+b的那个b,w第二个值就是wx+b的w
方法二:
1 clear all; close all; clc 2 x = load(‘ex2x.dat‘); y = load(‘ex2y.dat‘); 3 m = length(y); % number of training examples 4 % Plot the training data 5 figure; % open a new figure window 这个figure也可以不写,没什么影响 6 plot(x, y, ‘o‘);%用圆圈表示数据点 7 ylabel(‘Height in meters‘)%给y值写上代表什么意思 8 xlabel(‘Age in years‘) 9 10 % Gradient descent 11 x = [ones(m, 1) x]; % Add a column of ones to x x最开始增加一列1,也就是每一个数据点增加一维,并且这一维都是1, 12 %相当于要求得线性方程是齐次的w‘x=Y,x是变成的二维的,Y代表根据训练的w‘x预测的Y值 13 theta = zeros(size(x(1,:)))‘; % initialize fitting parameters w‘初始化为[0;0] 14 MAX_ITR = 1500; 15 alpha = 0.07;%学习速率 16 17 for num_iterations = 1:MAX_ITR 18 grad = (1/m).* x‘ * ((x * theta) - y);%grd具体是怎么算的可以看下下面的推导,只是这里的1/m不知道是怎么得出来的, 19 %我的是2m,注意grad是一个2*1的向量。并且公式里面的形式 20 %跟这里有点不同,是因为在公式中xi代表一个向量,这里x是一个矩阵,并且每一行代表一个样本,所以这里代码中前面是x‘后面是x, 21 %在公式中正好相反 .* 是点乘,不是内积,向量的内积结果是个数,这还是一个向量 22 theta = theta - alpha .* grad; %这里如果令grad=0求极值得到参数的方法就是前面的那个方法,这里不是grad=0,而是一次次的迭代,求最值。 23 end 24 hold on; % keep previous plot visible 25 plot(x(:,2), x*theta, ‘-‘)%这个就是回归曲线的那个图 26 legend(‘Training data‘, ‘Linear regression‘)%标出图像中各曲线标志所代表的意义,就是每个数据点表示成的圆圈或线段所代表的意义 27 hold off % don‘t overlay any more plots on this figure,指关掉前面的那幅图 28 % Closed form solution for reference 29 % You will learn about this method in future videos 30 exact_theta = (x‘ * x)\x‘ * y%不知道这是啥意思 31 % Predict values for age 3.5 and 7 32 predict1 = [1, 3.5] *theta 33 predict2 = [1, 7] * theta 34 % Grid over which we will calculate J 35 theta0_vals = linspace(-3, 3, 100);%生成一个从-3到3之间有均匀的100个元素的向量 36 theta1_vals = linspace(-1, 1, 100); 37 % initialize J_vals to a matrix of 0‘s 38 J_vals = zeros(length(theta0_vals), length(theta1_vals)); 39 for i = 1:length(theta0_vals) 40 for j = 1:length(theta1_vals) 41 t = [theta0_vals(i); theta1_vals(j)]; 42 J_vals(i,j) = (0.5/m) .* (x * t - y)‘ * (x * t - y);%当参数的取值是从(-3,1)到(3,1) 43 %的矩形内均匀采样取值时(取了100*100个参数),所有样本xi与每个参数对应 44 %的回归方程的误差就是 J_vals(i,j)的一个值 45 end 46 end 47 J_vals = J_vals‘; 48 % Surface plot 49 figure; 50 surf(theta0_vals, theta1_vals, J_vals)%画出参数与损失函数的图像。注意用这个surf比较蛋疼,surf(X,Y,Z)是这样的, 51 %X,Y是向量,Z是矩阵,用X,Y铺成的网格(100*100个点)与Z的每个点 52 %形成一个图形,但是是怎么对应的哪,蛋疼之处就是,你的X的第二个元素与Y的第一个元素形成的那一个点不是和Z(2,1)的值对应!! 53 %而是和Z(1,2)对应!!因为前面形成Z(2,1)时,是X的第二个元素与Y的第一个元素 54 %所以J_vals前面才要转置。 55 xlabel(‘\theta_0‘); ylabel(‘\theta_1‘); 56 % Contour plot 57 figure; 58 % Plot J_vals as 15 contours spaced logarithmically between 0.01 and 100 59 contour(theta0_vals, theta1_vals, J_vals, logspace(-2, 2, 15))%画出等高线 60 xlabel(‘\theta_0‘); ylabel(‘\theta_1‘);%类似于转义字符,但是最多只能是到参数0~9
第18行公式:就是就是cost function w是这个方程的参数,这个方程对w求导就是代码里的grad。
求的结果是
实验结果:训练样本散点和回归曲线预测图:
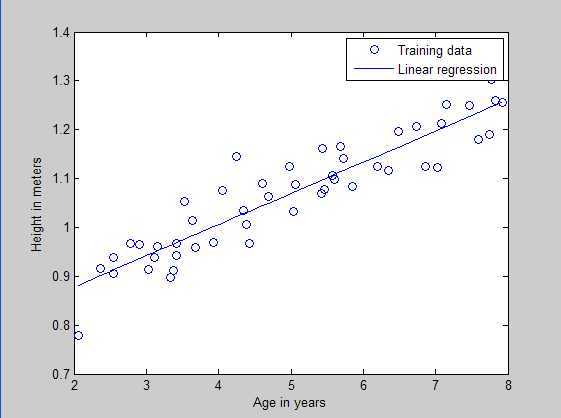
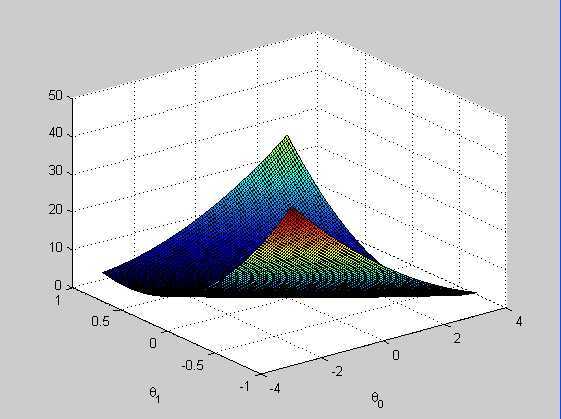
损失函数与参数之间的曲面图:
deep learning 学习(二)线性回归的matalab操作
标签:des style blog http io ar color os sp
原文地址:http://www.cnblogs.com/happylion/p/4163103.html
