标签:style blog http io ar os 使用 sp strong
在互联网(尤其是移动互联网)、物联网、云计算、大数据等高速发展的大背景下,数据呈现爆炸式地增长。根据IDC的预测,到2020年产生的数据量 将达到40ZB,而之前2011年6月的预测是35ZB。然而,社会化网络、移动通信、网络视频音频、电子商务、传感器网络、科学实验等各种应用产生的数 据,不仅存储容量巨大,而且还具有数据类型繁多、数据大小变化大、流动快等显著特点,往往能够产生千万级、亿级甚至十亿、百亿级的海量小文件,而且更多地 是海量大小文件混合存储。由于在元数据管理、访问性能、存储效率等方面面临巨大的挑战性,因此海量小文件(LOSF,lots of small files)问题成为了工业界和学术界公认的难题。
通常我们认为大小在1MB以内的文件称为小文件,百万级数量及以上称为海量,由此量化定义海量小文件问题,以下简称LOSF。LOSF应用在目前实 际中越来越常见,如社交网站、电子商务、广电、网络视频、高性能计算,这里举几个典型应用场景。著名的社交网站Facebook存储了600亿张以上的图 片,推出了专门针对海量小图片定制优化的Haystack进行存储。淘宝目前应该是最大C2C电子商务网站,存储超过200亿张图片,平均大小仅为 15KB,也推出了针对小文件优化的TFS文件系统存储这些图片,并且进行了开源。歌华有线可以进行图书和视频的在线点播,图书每页会扫描成一个几十KB 大小的图片,总图片数量能够超过20亿;视频会由切片服务器根据视频码流切割成1MB左右的分片文件,100个频道一个星期的点播量,分片文件数量可达到 1000万量级。动漫渲染和影视后期制作应用,会使用大量的视频、音频、图像、纹理等原理素材,一部普通的动画电影可能包含超过500万的小文件,平均大 小在10-20KB之间。金融票据影像,需要对大量原始票据进行扫描形成图片和描述信息文件,单个文件大小为几KB至几百KB的不等,文件数量达到数千万 乃至数亿,并且逐年增长。
目前的文件系统,包括本地文件系统、分布式文件系统和对象存储系统,都是主要针对大文件设计的,比如XFS/EXT4、Lustre、 GlusterFS、GPFS、ISLION、GFS、HDFS,在元数据管理、数据布局、条带设计、缓存管理等实现策略上都侧重大文件,而海量小文件应 用在性能和存储效率方面要大幅降低,甚至无法工作。针对LOSF问题,出现一些勇敢的挑战者。EXT4主要对EXT3进行了两方面的优化,一是inode 预分配,这使得inode具有很好的局部性特征,同一目录文件inode尽量放在一起,加速了目录寻址与操作性能。因此在小文件应用方面也具有很好的性能 表现。二是extent/delay/multi的数据块分配策略,这些策略使得大文件的数据块保持连续存储在磁盘上,数据寻址次数大大减少,显著提高I /O吞吐量。因此,EXT4对于大小文件综合性能表现比较均衡。Reiserfs对小文件作了优化,并使用B* tree组织数据,加速了数据寻址,大大降低了open/create/delete/close等系统调用开销。Reiserfs的tail package功能可以对一些小文件不分配inode,而是将这些文件打包,存放在同一个磁盘分块中。对于小于1KB的小文件,Rerserfs可以将数 据直接存储在inode中。因此, Reiserfs在小文件存储的性能和效率上表现非常出色。Facebook 推出了专门针对海量小文件的文件系统Haystack,通过多个逻辑文件共享同一个物理文件、增加缓存层、部分元数据加载到内存等方式有效的解决了 Facebook海量图片存储问题。淘宝推出了类似的文件系统TFS(Tao File System),通过将小文件合并成大文件、文件名隐含部分元数据等方式实现了海量小文件的高效存储。FastDFS针对小文件的优化类似于TFS。国防 科学技术大学对Lustre进行了小文件优化工作,在OST组件中设计并实现了一种分布独立式的小文件Cache结构:Filter Cache,通过扩展Lustre的OST端的数据通路,在原有数据通路的基础上,增加对小对象I/O的缓存措施,以此来改善Lustre性能。
对于LOSF而言,IOPS/OPS是关键性能衡量指标,造成性能和存储效率低下的主要原因包括元数据管理、数据布局和I/O管理、Cache管 理、网络开销等方面。从理论分析以及上面LOSF优化实践来看,优化应该从元数据管理、缓存机制、合并小文件等方面展开,而且优化是一个系统工程,结合硬 件、软件,从多个层面同时着手,优化效果会更显著。
衡量存储系统性能主要有两个关键指标,即IOPS和数据吞吐量。IOPS (Input/Output Per Second) 即每秒的输入输出量 ( 或读写次数 ) ,是衡量存储系统性能的主要指标之一。 IOPS 是指单位时间内系统能处理的 I/O 请求数量,一般以每秒处理的 I/O 请求数量为单位, I/O 请求通常为读或写数据操作请求。随机读写频繁的应用,如 OLTP(OnlineTransaction Processing) ,IOPS 是关键衡量指标。另一个重要指标是数据吞吐量(Throughput),指单位时间内可以成功传输的数据数量。对于大量顺序读写的应用,如 VOD(VideoOn Demand),则更关注吞吐量指标。
传统磁盘本质上一种机械装置,如FC,SAS, SATA磁盘,转速通常为5400/7200/10K/15K rpm不等。影响磁盘的关键因素是磁盘I/O服务时间,即磁盘完成一个I/O请求所花费的时间,它由寻道时间、旋转延迟和数据传输时间三部分构成。因此可 以计算磁盘的IOPS= 1000 ms/ (Tseek + Troatation + Ttransfer),如果忽略数据传输时间,理论上可以计算出磁盘的最大IOPS。当I/O访问模式为随机读写时,寻道时间和旋转延迟相对于顺序读写要明显增加,磁盘IOPS远小于理论上最大值。定义有效工作时间Pt= 磁盘传输时间/磁盘I/O服务时间,由此可知随机读写单个文件效率要低于连续读写多个文件。对于磁盘文件系统来说,无论读写都存在元数据操作。以EXTx 文件系统写数据为例,向磁盘写入数据进行大量的元数据操作,包括更新inode目录、目录、inode和数据块位图等。定义有效数据读写率Pd=所需数据/实际磁盘读写数据,其中实际磁盘读写数据为磁盘元数据与所需数据之和。当操作连续大文件时,对元数据的操作开销可被庞大的数据操作开销分摊,但小文件的有效读写率小于大文件的,当小文件数量急剧增加时,对大量元数据的操作会严重影响系统的性能。
从上面对磁盘介质的分析可以看出,磁盘最适合顺序的大文件I/O读写模式,但非常不适合随机的小文件I/O读写模式,这是磁盘文件系统在海量小文件 应用下性能表现不佳的根本原因。前面已经提到,磁盘文件系统的设计大多都侧重于大文件,包括元数据管理、数据布局和I/O访问流程,另外VFS系统调用机 制也非常不利于LOSF,这些软件层面的机制和实现加剧了LOSF的性能问题。
(1) 元数据管理低效
由于小文件数据内容较少,因此元数据的访问性能对小文件访问性能影响巨大。当前主流的磁盘文件系统基本都是面向大文件高聚合带宽设计的,而不是小文 件的低延迟访问。磁盘文件系统中,目录项(dentry)、索引节点(inode)和数据(data)保存在存储介质的不同位置上。因此,访问一个文件需 要经历至少3次独立的访问。这样,并发的小文件访问就转变成了大量的随机访问,而这种访问对于广泛使用的磁盘来说是非常低效的。同时,文件系统通常采用 Hash树、 B+树或B*树来组织和索引目录,这种方法不能在数以亿计的大目录中很好的扩展,海量目录下检索效率会明显下降。正是由于单个目录元数据组织能力的低效, 文件系统使用者通常被鼓励把文件分散在多层次的目录中以提高性能。然而,这种方法会进一步加大路径查询的开销。
(2) 数据布局低效
磁盘文件系统使用块来组织磁盘数据,并在inode中使用多级指针或hash树来索引文件数据块。数据块通常比较小,一般为1KB、2KB或 4KB。当文件需要存储数据时,文件系统根据预定的策略分配数据块,分配策略会综合考虑数据局部性、存储空间利用效率等因素,通常会优先考虑大文件I/O 带宽。对于大文件,数据块会尽量进行连续分配,具有比较好的空间局部性。对于小文件,尤其是大文件和小文件混合存储或者经过大量删除和修改后,数据块分配 的随机性会进一步加剧,数据块可能零散分布在磁盘上的不同位置,并且会造成大量的磁盘碎片(包括内部碎片和外部碎片),不仅造成访问性能下降,还导致大量 磁盘空间浪费。对于特别小的小文件,比如小于4KB,inode与数据分开存储,这种数据布局也没有充分利用空间局部性,导致随机I/O访问,目前已经有 文件系统实现了data in inode。
(3) I/O访问流程复杂
Linux等操作系统采用VFS或类似机制来抽象文件系统的实现,提供标准统一访问接口和流程,它提供通用的Cache机制,处理文件系统相关的所 有系统调用,与具体文件系统和其他内核组件(如内存管理)交互。VFS可以屏蔽底层文件系统实现细节,简化文件系统设计,实现对不同文件系统支持的扩展。 VFS通用模型中有涉及四种数据类型:超级块对象(superblock object)、索引结点对象(inode object)、文件对象(file object)和目录项对象(dentry object),进程在进行I/O访问过程中需要频繁与它们交互(如下图所示)。
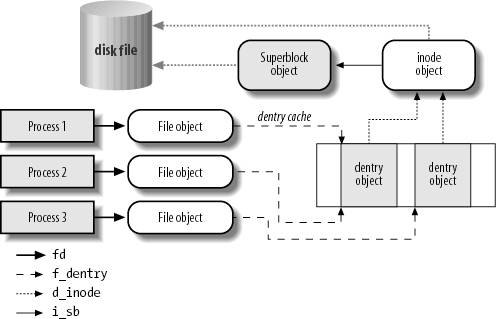
进程与VFS对象交互
典型的I/O读写流程是这样:open()àseek()àread()/write()àclose()。其中,文件的open()操作是一项复 杂的工作, 文件的打开操作流程大致是这样的: 首先在当前进程的文件描述表fdtale中分配一个空的文件描述符fd , 然后在filp_cachep中创建一个file struct , 调用do_path_lookup()找到文件的inode ,取出inode的文件操作方法file_operations赋给file struct ,并调用f->f_op->open()执行打开的操作;最后根据文件描述符fd将file安装在当前进程文件描述表fdtable对应的位 置。这样在之后的read()/write()文件操作时, 只需要根据文件描述符fd,就可以在当前进程的描述表中找到该文件的file对象,然后调用f->f_op操作方法对文件进行操作。用户空间使用路 径名来表示文件,而内核中对文件的操作是依据上述四种数据类型对象,因此在open()过程中需要进行路径查找do_path_lookup,将路径名进 行分量解析,转换成对应文件在内核中内部表示。这个工作相当重要,并且非常占用系统开销,尤其是大量频繁open比较深目录下的文件。
对于小文件的I/O访问过程,读写数据量比较小,这些流程太过复杂,系统调用开销太大,尤其是其中的open()操作占用了大部分的操作时间。当面对海量小文件并发访问,读写之前的准备工作占用了绝大部分系统时间,有效磁盘服务时间非常低,从而导致小I/O性能极度低下。
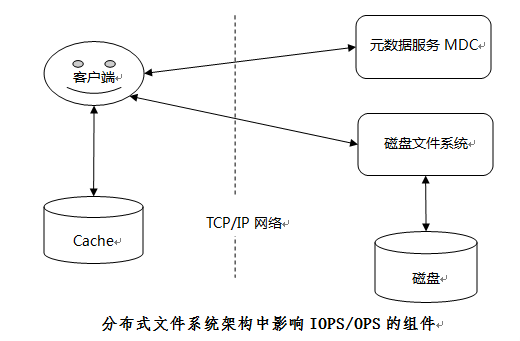
对于大多数分布式文件系统而言,通常将元数据与数据两者独立开来,即控制流与数据流进行分离,从而获得更高的系统扩展性和I/O并发性。数据和I /O访问负载被分散到多个物理独立的存储节点,从而实现系统的高扩展性和高性能,每个节点使用磁盘文件系统管理数据,比如XFS、EXT4、XFS等。因 此,相对于磁盘文件系统而言,每个节点的小文件问题是相同的。由于分布式的架构,分布式文件系统中的网络通信、元数据服务MDC、Cache管理、数据布 局和I/O访问模式等都会对IOPS/OPS性能产生影响,进一步加剧LOSF问题。
(1) 网络通信开销
相对于磁盘文件系统,分布式文件系统客户端与MDC和I/O服务器之间增加了网络连接,通常为延迟较大的TCP/IP网络。元数据和数据访问都经过网络传输,增加了RPC网络通信开销,扩大了小文件访问延时。
(2) MDC管理
由于分布式文件系统将元数据和数据分开存储,在读写小文件之前,需要通过与MDC进行通信获取位置信息。和磁盘文件系统相比,这一过程相当于额外增加一次网络传输开销和元数据服务访问开销。这对小文件I/O来说,开销影响非常大。
(3) 数据布局和I/O访问模式
对于大文件,分布式文件系统往往采用条带化技术对文件进行切片,并发发在多个数据服务器上进行存储,以此来提高用户对文件访问的并发性,从而提高对 大文件的访问性能。而对于小文件,由于其不利于条带化,一般采用将单个文件存储在单个数据服务器上的策略。但当小文件数量达到一定程度后,对小文件的大量 地重复访问将会给数据服务器带来性能上的负担和I/O瓶颈问题。
分布式文件系统客户端在访问小文件I/O时,采用大文件请求相同的方式,为每个文件访问请求分别建立连接或者RPC请求。TCP/IP网络在延迟和传输效率方面比较低,这种I/O访问模式非常不利于小文件,I/O效率低下。
(4) Cache管理
分布式文件系统的Cache设计对小文件I/O性能作用不明显,用户访问小文件时需要额外的I/O带宽。客户端Cache通常只对本机有效,不同客 户端访问同一个文件数据时,每个用户都需要把数据复制到本地Cache中。对于小文件I/O操作来说,访问的文件内容只占页内很少一部分,但也需要整个物 理页从I/O服务端的磁盘读入操作系统的文件缓存再访问。从服务端读取数据并缓存至Client端的Cache中这一过程需要额外的流量,小文件I/O越 频繁,需要的额外总流量就越多,系统的总体I/O性能就越低。
总结一下,通过以上的分析我们可以看出,不管是磁盘文件系统还是分布式文件系统,LOSF问题主要源自元数据管理、数据布局、Cache管理、 I/O访问流程、网络开销等几个方面。因此,针对问题的根源可以施行特定的优化措施,优化思路大体分为两种:一是减少数据访问次数,二是减少数据访问时 间。具体来讲,可以从合并小文件、增大Cache命中率、优化元数据管理等方面提高访问效率,从而达到优化海量小文件存储的效果。同时,可以结合硬件和应 用优化,进一步增强优化效果。
海量小文件由于数量巨大,而且通常需要进行共享和并发访问,目前通常采用分布式系统进行存储,包括分布式文件系统和分布式对象存储系统,每个存储节 点底层采用磁盘文件系统进行管理。因此这里重点介绍分布式存储系统的LOSF优化策略。前面我们已经提到,Haystack, TFS, FastDFS, Lustre等分布式存储系统在LOSF方面的优化工作实践,结合上面对LOSF问题根源的剖析,我们认为硬件优化、Cache管理优化、小文件合并存 储、元数据管理优化等是几种行之有效的优化方法。当然,性能优化没有黄金法则,必须是在对现有系统充分的测试和分析的基础上,有针对性地选择合适的优化策 略,方能有实质性优化效果。
如果不考虑成本问题,硬件优化是最为直接有效的优化方法,按照减少数据访问时间的优化思路,采用更高性能的硬件来提高LOSF性能。比如,使用速度 更快的SSD作为全部或部分存储介质,部分部署时作为分层存储或者Cache加速,可以显著提高随机读写场景下的IOPS/OPS性能;采用处理能力更强 或更多的CPU,可以提高系统的I/O处理速度和并发性;配置更大空容量的内存,以空间换时间,有效提高数据缓存命中率;采用延迟更小、带宽更高的网络设 备优化网络传输效率,比如万兆网络或InfiniBand网络;部署多路径I/O通道提高数据吞吐量和并发访问,如LAN网络和SAN网络。硬件优化的目 标是消除I/O物理通道上的瓶颈,保证理论上的性能最大化,为软件层面的优化工作做铺垫。值得一提的是,硬件设备在性能上要做到匹配,尤其是磁盘和网络, 否则容易导致性能瓶颈或者成本浪费。
Cache技术广泛应用于存储系统的各个领域,比如CPU L1/L2 Cache、文件系统、分布式存储系统等。Cache技术主要通过空间换时间的策略,利用数据访问的时间和空间局部性,尽量提高数据访问的缓存命中率,从 而提高系统的性能。存储系统中的Cache位于最低层存储介质之上,其中缓存了应用程序需要的数据子集。对子集中的数据的读写先在Cache中异步进行, 然后异步存储到低层稳定的介质上。Cache技术通过这种异步的数据I/O模式来解决程序中的计算速度和数据存储速度不匹配的鸿沟,减少了访问底层存储介 质的次数,使存储系统的性能大大提高。增大Cache容量可以缓存更多的数据,减小cache的容量失效,从而显著提高Cache命中率。但cache的 命中率并不随着容量呈线性增长,当cache容量达到一定阈值时,再增大容量命中率并不会显著提高,因此要根据成本和实际需要来选择cache容量。
分布式存储系统中,多个存储节点、元数据服务以及客户端都通过物理网络互联,客户端和服务器端都会进行数据缓存。根据节点上Cache资源工作方式 的不同,分布式存储系统中的Cache分为分布独立式 Cache和协作式Cache。分布独立式Cache中,每个存储节点上的文件系统Cache只负责缓存本节点上的I/O数据,Cache中数据的一致性 和Cache资源分配等工作由本节点上的Cache管理器负责。这种Cache管理简单,不影响系统的整体结构,系统增删存储节点后,也不需要做额外的 Cache配置和管理工作。协作式Cache中,每个存储节点上的Cache不仅负责缓存本节点上的I/O数据,还负责缓存其他节点上的Cache数据。 协作式Cache需要各节点之间能够快速的通信,因此存储节点之间的网络带宽必须足够大。协作式Cache能够充分利用Cache资源,构造容量更大的全 局Cache,可以实现Cache资源的负载均衡。两种Cache方式相比较,分布独立式Cache简单、扩展性高,协作式Cache管理复杂、对网络要 求高,但是Cache命中率能够大幅提高,对分布式存储系统整体性能提高更加明显。另外,分布式存储系统中客户端缓存会减弱服务器端缓存的局部性,导致基 于局部性的LRU缓存替换算法效果不佳,或者多级cache系统部重复缓存。因此,在缓存替换算法方面需要进行特别的优化设计,综合考虑访问最近性、时间 局部性、空间局部性、文件关联等因素。
Cache技术利用了数据访问的时间局部性,对访问过的数据进行暂时的保留。但由于缓冲空间大小以及更新算法的制约,当数据频繁更新时。缓存带来的 性能改善不再显著。对于小文件,可以根据局部性原理和I/O访问行为,预测最近可能访问的文件集合,提前预读到Cache系统中,通过减少文件读取时间提 高存储系统性能。许多系统把数据访问请求当作是独立的事件,实际上数据请求并非完全随机,而是由用户或程序的行为驱动的,存在特定的访问模式。而这种模式 常常被缓存系统所忽略。预取是主动缓存技术,它利用了数据的空间局部性,对将来可能发生的数据请求进行预测,在访问之前取出并缓存,以备用户访问,从而减 少访问延迟。预测技术主要通过对数据本体或历史访问记录的分析,构造合适的预测模型,据此对未来的访问进行预测。用户执行应用程序去访问数据,连续访问的 不同文件之间必然存在一定的关联。当用户以先前大致相同的顺序去请求数据时,或多或少会访问相同的文件集合,尤其对同一个用户来说。正确的预测可以提高系 统的性能,而错误的预测不仅会造成缓存空间和I/O带宽的浪费,而且会增加正常访问的延时。
小文件合并存储是目前优化LOSF问题最为成功的策略,已经被包括Facebook Haystack和淘宝TFS在内多个分布式存储系统采用。它通过多个逻辑文件共享同一个物理文件,将多个小文件合并存储到一个大文件中,实现高效的小文 件存储。为什么这种策略对LOSF效果显著呢?
首先,减少了大量元数据。通过将大量的小文件存储到一个大文件中,从而把大量的小文件数据变成大文件数据,减少了文件数量,从而减少了元数据服务中 的元数据数量,提高了元数据的检索和查询效率,降低了文件读写的I /O操作延时,节省了大量的数据传输时间。LOSF元数据开销所占比重大,大幅减少元数据,将直接导致性能的显著提升。合并后的大文件存储在磁盘文件系统 之上,同时也大大降低了磁盘文件系统在元数据和I/O方面的压力,这点可以改善每个节点的存储性能。小文件的元数据和数据会一并存储在大文件中,并形成索 引文件,访问时通过索引进行定位。索引文件采用预加载到Cache的策略,可以实现随机读写小文件只需要一次I/O。
其次,增加了数据局部性,提高了存储效率。磁盘文件系统或者分布式文件系统中,文件的元数据和数据存储在不同位置。采用合并存储机制后,小文件的元 数据和数据可以一并连续存储大文件中,这大大增强了单个小文件内部的数据局部性。小文件合并过程中,可以利用文件之间的空间局部性、时间局部性以及关联, 尽量将可能连续访问的小文件在大文件中进行连续存储,增强了小文件之间的数据局部性。这直接降低了磁盘上随机I/O比率,转换成了顺序I/O,能够有效提 高I/O读写性能。另外,小文件单独存储会形成外部和内部碎片,而合并存储后存储碎片将大大降低,这极大提高了LOSF存储效率。
再次,简化了I/O访问流程。采用小文件合并存储后,I/O访问流程发生了极大变化,主要体现在存储节点磁盘文件系统上。根据之前的阐述,磁盘文件 系统读写一个小文件,最大的系统消耗在open系统调用,需要进行路径查找do_path_lookup,将路径名进行分量解析,转换成对应文件在内核中 内部表示。这个过程非常占用系统开销,尤其是深目录下的文件。而经过合并,很多小文件共享一个大文件,open操作转换成了开销小很多的seek操作,根 据索引定位到大文件内部相应位置即可,也不需要在内核中创建相关VFS数据对象,这节省了原先绝大部分的系统开销。
大文件加上索引文件,小文件合并存储实际上相当于一个微型文件系统。这种机制对于WORM(Write Once Read Many)模式的分布式存储系统非常适合,而不适合允许改写和删除的存储系统。因为文件改写和删除操作,会造成大文件内部的碎片空洞,如果进行空间管理并 在合适时候执行碎片整理,实现比较复杂而且产生额外开销。如果不对碎片进行处理,采用追加写的方式,一方面会浪费存储容量,另一方面又会破坏数据局部性, 增加数据分布的随机性,导致读性能下降。此外,如果支持随机读写,大小文件如何统一处理,小文件增长成大文件,大文件退化为小文件,这些问题都是在实际处 理时面临的挑战。
分布式存储系统架构大致分两种,即有中心架构和无中心架构。在有中心架构的分布式存储系统中,通常有一个元数据服务器MDC来统一管理元数据。而在 无中心的架构中,元数据会分散存储于各个存储节点上,通过一致性Hash等算法进行管理和定位。客户端在读写小文件数据之前,需要通过与MDC或存储节点 进行通信获取位置信息,这一过程相当于额外增加一次网络传输开销和元数据服务访问开销。这对小文件I/O来说,开销影响非常大,尤其是对于延迟较大的网络 而言。因此,元数据管理优化主要从减少元数据量、减少元数据访问次数、提高元数据检索效率等几个方面着手。
对于单个小文件,元数据包括位置信息、名称、guid、属主、大小、创建日期、访问日期、访问权限等信息。在分布式存储系统中,根据访问接口和语义 需要,可以对元数据进行精简,保留足够的元数据即可,从而达到减少元数据的目的。比如,TFS/FastDFS通过在文件命名中隐含位置信息等部分元数 据,对象存储系统可以不需要访问日期、访问权限等元信息,从而节省了元数据量。这带来的好处是,可以减少元数据通信延迟,相同容量的Cache可以缓存更 多的元数据,从而提高元数据的访问效率。
前面刚刚提到TFS/FastDFS在文件名中隐含了位置信息,无需与MDC或存储节点交互就能够对文件进行定位,减少了一次元数据访问。元数据操 作在小文件整个I/O过程占了大部分时间,对于大量并发元数据操作,可以对多个RPC请求进行合并,从而大幅减少元数据访问次数。最为重要的,可以在客户 端对元数据进行缓存,利用Cache中元数据访问的时间局部性,结合预读策略, 显著减少元数据访问次数。每一次元数据访问都会产生可观的网络开销,因此降低元数据访问次数,能够有效提高元数据操作效率。
在MDC上或者存储节点上,元数据最终持久化存储在数据库、KV存储系统、磁盘文件系统目录上,甚至是单个文件中。同时,为了提高访问性能,会将部 分或者全部元数据缓存在Cache中。为了达到高效的元数据检索,需要考虑大容量内存和快速磁盘(比如SAS磁盘或SSD),Cache系统采用可扩展性 Hash等高效数据结构组织缓存的元数据。同时,还可以通过多级索引、BloomFilter等减少元数据操作过程的I/O访问次数,进一步加快元数据访 问速度。
随着互联网、物联网、云计算、大数据等技术的发展,海量小文件LOSF问题成为了学术界和工业界研究的热点。Facebook和Taobao等紧密 结合各自的业务应用特点,在海量小图片存储系统优化方面取得了非常不错的成绩,成功支撑了数百亿级别的线上图片存储。由于LOSF优化需要深入结合业务数 据特点,优化效果才能显著,因此优化策略和方法难以普遍适用,不可推而广之。本文从LOSF问题的源起谈起,重点分析LOSF问题根源,然后给出优化策略 和方法,提出硬件优化、Cache管理优化、小文件合并存储、元数据管理优化等是几种行之有效的优化方法,期望对LOSF问题的研究和优化实践提供一定的 理论和方法指导,而非具体的实践技术。值得一提的是,性能优化没有黄金法则,必须是在对现有系统充分的测试和分析的基础上,有针对性地选择合适的优化策 略,方能有实质性优化效果。
[1] Findinga needle in Haystack: Facebook’s photo storage
[4] 海量小文件存储文件系统研究综述
刘爱贵,中科院毕业,博士,专注于存储技术的研究与开发,目前在存储行业从事云存储相关研发工作,分布式文件系统资深理论研究与实践者。
CSDN博客:http://blog.csdn.net/liuaigui
Email:aigui.liu@gmail.com
QQ:9187434
标签:style blog http io ar os 使用 sp strong
原文地址:http://my.oschina.net/javaeye/blog/356033