标签:style http ar io color os 使用 sp for
三、你为什么需要Spark;
你需要Spark的十大理由:
1,Spark是可以革命Hadoop的目前唯一替代者,能够做Hadoop做的一切事情,同时速度比Hadoop快了100倍以上:
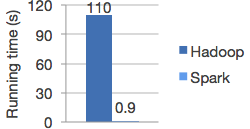
Logistic regression in Hadoop and Spark
可以看出在Spark特别擅长的领域其速度比Hadoop快120倍以上!
2,原先支持Hadoop的四大商业机构纷纷宣布支持Spark,包含知名Hadoop解决方案供应商Cloudera和知名的Hadoop供应商MapR;
3,Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术,目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、NoSQL查询等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。
4,国外一些大型互联网公司已经部署了Spark。甚至连Hadoop的早期主要贡献者Yahoo现在也在多个项目中部署使用Spark;国内的淘宝、优酷土豆、网易、Baidu、腾讯等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。
5,不得不提的是Spark的“One stack to rule them all”的特性,Spark的特点之一就是用一个技术堆栈解决云计算大数据中流处理、图技术、机器学习、交互式查询、误差查询等所有的问题,此时我们只需要一个技术团队通过Spark就可以搞定一切问题,而如果基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就不存在这个问题;
6,Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark;
7,如果你已经使用了Hadoop,就更加需要Spark。Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark,同时,这几年来,Hadoop的改进基本停留在代码层次,也就是修修补补的事情,这就导致了Hadoop现在具有深度的“技术债务”,负载累累;
8,伴随Spark技术的普及推广,对专业人才的需求日益增加。Spark专业人才在未来也是炙手可热,轻而易举可以拿到百万的薪酬;
9,百亿美元市场,教授为之辞职,学生为止辍学,大势所趋!
10,Life is short.
四、如何成为云计算大数据Spark高手(含思维导图和每个阶段的课程推荐);
Spark采用一个统一的技术堆栈解决了云计算大数据的如流处理、图技术、机器学习、NoSQL查询等方面的所有核心问题,具有完善的生态系统,这直接奠定了其一统云计算大数据领域的霸主地位;
要想成为Spark高手,需要经历六大阶段:
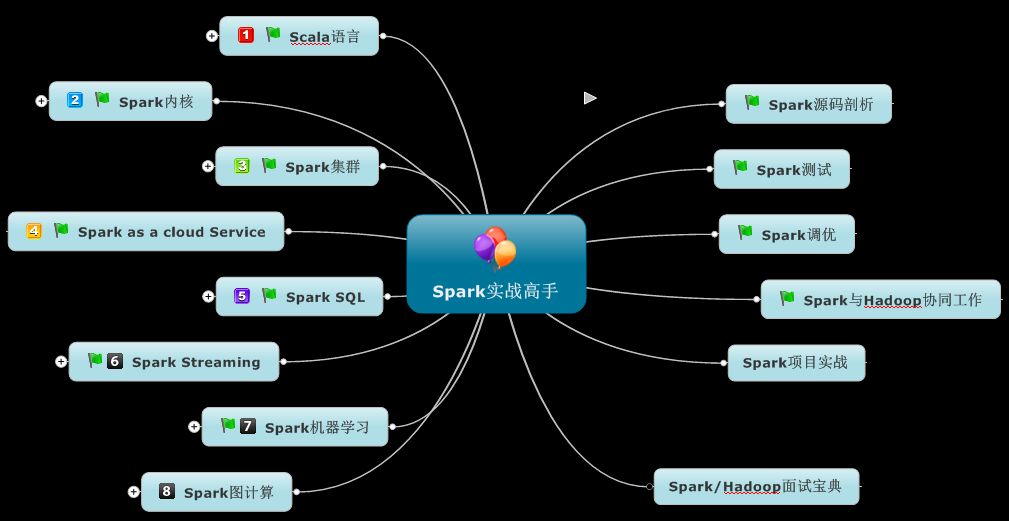
第一阶段:熟练的掌握Scala语言
1, Spark框架是采用Scala语言编写的,精致而优雅。要想成为Spark高手,你就必须阅读Spark的源代码,就必须掌握Scala,;
2, 虽然说现在的Spark可以采用多语言Java、Python等进行应用程序开发,但是最快速的和支持最好的开发API依然并将永远是Scala方式的API,所以你必须掌握Scala来编写复杂的和高性能的Spark分布式程序;
3, 尤其要熟练掌握Scala的trait、apply、函数式编程、泛型、逆变与协变等;
推荐课程:”精通Spark的开发语言:Scala最佳实践”
第二阶段:精通Spark平台本身提供给开发者API
1, 掌握Spark中面向RDD的开发模式,掌握各种transformation和action函数的使用;
2, 掌握Spark中的宽依赖和窄依赖以及lineage机制;
3, 掌握RDD的计算流程,例如Stage的划分、Spark应用程序提交给集群的基本过程和Worker节点基础的工作原理等
推荐课程:“18小时内掌握Spark:把云计算大数据速度提高100倍以上!”
第三阶段:深入Spark内核
此阶段主要是通过Spark框架的源码研读来深入Spark内核部分:
1, 通过源码掌握Spark的任务提交过程;
2, 通过源码掌握Spark集群的任务调度;
3, 尤其要精通DAGScheduler、TaskScheduler和Worker节点内部的工作的每一步的细节;
推荐课程:“Spark 1.0.0企业级开发动手:实战世界上第一个Spark 1.0.0课程,涵盖Spark 1.0.0所有的企业级开发技术”
第四阶级:掌握基于Spark上的核心框架的使用
Spark作为云计算大数据时代的集大成者,在实时流处理、图技术、机器学习、NoSQL查询等方面具有显著的优势,我们使用Spark的时候大部分时间都是在使用其上的框架例如Shark、Spark Streaming等:
1, Spark Streaming是非常出色的实时流处理框架,要掌握其DStream、transformation和checkpoint等;
2, Spark的离线统计分析功能,Spark 1.0.0版本在Shark的基础上推出了Spark SQL,离线统计分析的功能的效率有显著的提升,需要重点掌握;
3, 对于Spark的机器学习和GraphX等要掌握其原理和用法;
推荐课程:“Spark企业级开发最佳实践”
第五阶级:做商业级别的Spark项目
通过一个完整的具有代表性的Spark项目来贯穿Spark的方方面面,包括项目的架构设计、用到的技术的剖析、开发实现、运维等,完整掌握其中的每一个阶段和细节,这样就可以让您以后可以从容面对绝大多数Spark项目。
推荐课程:“Spark架构案例鉴赏:Conviva、Yahoo!、优酷土豆、网易、腾讯、淘宝等公司的实际Spark案例”
第六阶级:提供Spark解决方案
1, 彻底掌握Spark框架源码的每一个细节;
2, 根据不同的业务场景的需要提供Spark在不同场景的下的解决方案;
3, 根据实际需要,在Spark框架基础上进行二次开发,打造自己的Spark框架;
推荐课程:“精通Spark:Spark内核剖析、源码解读、性能优化和商业案例实战”
前面所述的成为Spark高手的六个阶段中的第一和第二个阶段可以通过自学逐步完成,随后的三个阶段最好是由高手或者专家的指引下一步步完成,最后一个阶段,基本上就是到”无招胜有招”的时期,很多东西要用心领悟才能完成。
【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第1节②
标签:style http ar io color os 使用 sp for
原文地址:http://my.oschina.net/u/1791057/blog/356845