标签:
决策书既可以用于分类也可以用于回归分析,本文的决策书仅针对与分类
一、基本知识
1、什么是分类决策树?
分类决策树模型是一种描述对实例进行分类的树形结构。由结点和有向边组成,结点分为内部结点和叶结点,内部结点表示特征,叶节点表示类,有向边则表示某一个特征的取值
2、分类决策树学习算法的过程?
(1)特征选择-即选择哪个特征用于划分空间
特征选择的原则是什么?按照这一特征将数据集分成若干个子集,各个子集在当前条件下具有最好的分类
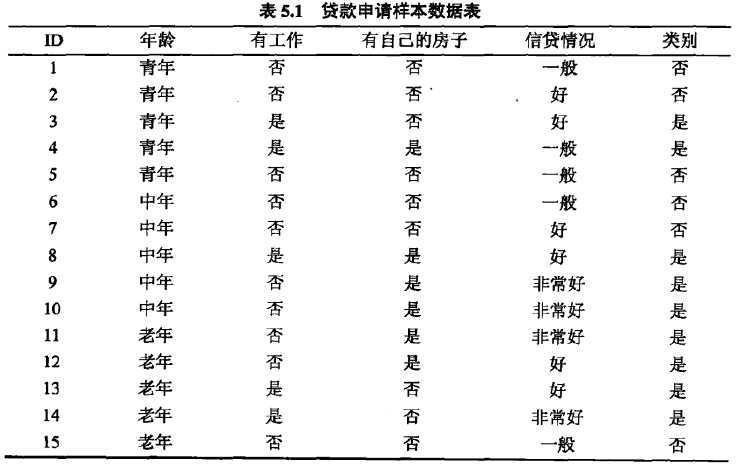
例如文章最开头的那个例子,如果选择年龄这个特征,可以分为“青年”“中年”“老年”三个数据集,青年:3是2否,中年3是2否,老年4是2否;如果选择有工作这个特征,可以分为“是”和“否”两个自己,有工作:5是0否,无工作:*是*否,可以看出来,当有工作这个特征取“是”这个特征值时,类全为“是”,直观上,按照“有工作”这个特征比“年龄”这个特征划分的结果要好。
下文将具体讲解三种特征选择准则,信息增益,信息增益率,基尼指数,三种特征选择对应三种决策树算法,分别是ID3、C4.5和CART
(2)决策树生成
利用(1)中的准则选择分类特征,从根节点开始递归的产生决策树。即首先选取一个特征作为树的根节点,该特征将数据集划分为若干个子集,再为子集选择另一个特征继续划分,直到所有的结点都只有一个类型,即成为叶结点;如若这个过程中所有特征都用尽,有些数据集还未能够正确分类,那么选择该数据集中最多的类型作为其类型(多数表决)。
(3)树剪枝
由于生成的决策树可能存在过拟合的问题,比如数据集中存在噪声,在生成决策树过程中也将这些数据考虑在内,使得决策树泛化能力减弱。
决策树的剪枝往往从已生成的树上剪掉一些叶节点或叶节点以上的字数,并将其父节点或者根节点作为新的叶节点
二、特征选择
1、熵(entropy)
(1)什么是熵?
熵,是信息论中的一个概念,反映了随机变量的不确定性,熵越大,不确定性越大
理论上来讲: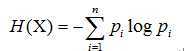 ,对数通常取以2为底或者以e为底,对应的熵的单位分别为比特、纳特
,对数通常取以2为底或者以e为底,对应的熵的单位分别为比特、纳特
举例来说,三个事件,A=“一个箱子,有一个白球和一个黑球,取一个球” B=“一个箱子,全是白球,取一个球” C="一个箱子,全是黑球,取一个球"
p(A=取到白球)=0.5,p(A=取到黑球)=0.5; p(B=取到白球)=1;p(c="取到黑球")=1,可以分别算出
取2为底,H(A)=-0.5log0.5-0.5log0.5=1 H(B)=H(C)=0,所以A的不确定性更大
抛开理论,什么叫不确定性?就是说这件事件你不确定是不是会发生,如果p=1,就代表了这件事肯定会发生,p=0即这件事肯定不会发生,没有其他情况,那么不确定性就自然为0;再比如这件事发生的概率为0.9,不发生的概率为0.1,那便可以预测这件事更有可能发生,即不确定性还是比较低的;如果说这件事发生的概率为0.5,发生与不发生的概率是一样的,你便根本无法去预测是否会发生,即不确定性非常大
(2)什么是条件熵?
条件熵,已知随机变量X的条件下,随机变量Y的不确定性
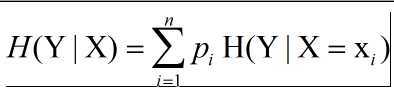
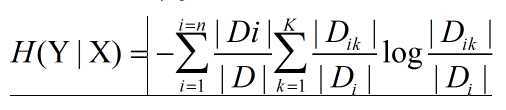
最开始的例子,X代表年龄,x1=青年,x2=中年,x3=老年,Y代表分类,D代表数据集,Di代表子数据集
以X=x1为例,p(X=x1)=|D1|/|D|=5/15=1/3; H(Y|X=x1)=(-3/5*log3/5-2/5*log2/5)
由此可以求出H(Y|X)
(3)什么是经验熵和经验条件熵?
如果熵和条件熵中的概率是由数据估计(特别是极大似然估计)得到时,所对应的熵和条件熵分别成为经验熵和经验条件熵
标签:
原文地址:http://www.cnblogs.com/naonaoling/p/4173631.html