标签:
在学到相关性度量的时候,有一个系数用来度量相似性(距离),这个系数叫做皮尔逊系数,事实上在统计学的时候就已经学过了,仅仅是当时不知道还能用到机器学习中来,这更加让我认为机器学习离不开统计学了。
皮尔逊相关系数——Pearson correlation coefficient,用于度量两个变量之间的相关性,其值介于-1与1之间,值越大则说明相关性越强。
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:

因为μX = E(X), σX2 = E[(X ? E(X))2] = E(X2) ? E2(X),Y也类似, 而且

故相关系数也能够表示成
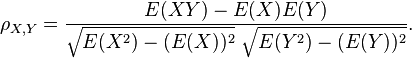
对于样本皮尔逊相关系数:
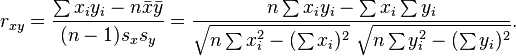
当中E是数学期望,cov表示协方差。
(公式摘自:http://zh.wikipedia.org/wiki/%E7%9A%AE%E5%B0%94%E9%80%8A%E7%A7%AF%E7%9F%A9%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0)
比方,依据上面的公式计算两个用户的Pearson 相关性:
/**
* 皮尔逊Pearson Correlation
* 对用户X,Y sum^2X:X的全部评分项之平方和sum^2Y:Y的全部评分项之平方和
* sumXY:sumX 、sumY的交集之和,即X、Y都评价了的项之和
* 相关性:sumXY / sqrt(sumX^2 * sumY^2)
* 两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
* p(X,Y) = (xi - avg(x))(yi - avg(y)) / sqrt((xi - avg(x))^2) * sqrt((yi - avg(y))^2)
*皮尔逊距离度量的是两个变量X和Y之间的距离:
* d(X,Y) =1 -p(X,Y)/(n -1) * sum((Xi - avg(X))/p(X) * (Yi-avg(Y)))/p(Y)
*
*
*/
public double userSimilarity(int userid1, int userid2) throws MyException {
// if(userid1 == userid2)
// throw new MyException("同一用户不能比較类似度。");
List<Rating> list1 = null;
List<Rating> list2 = null;
double avgX = 0.0;
double avgY = 0.0;
try {
list1 = st.getRatings(userid1);
list2 = st.getRatings(userid2);
avgX = st.getAvgRatings(userid1);
avgY = st.getAvgRatings(userid2);
} catch (SQLException e) {
e.printStackTrace();
}
double sumXY = 0, sumX = 0, sumY = 0;
for (int i = 0; i < list1.size(); i++) {
double rating1 = list1.get(i).getRating();
sumX += (rating1 - avgX) * (rating1 - avgX);
}
for (int j = 0; j < list2.size(); j++) {
double rating2 = list2.get(j).getRating();
sumY += (rating2 - avgY) * (rating2 - avgY);
}
for (int i = 0; i < list1.size(); i++) {
double rating1 = list1.get(i).getRating();
for (int j = 0; j < list2.size(); j++) {
double rating2 = list2.get(j).getRating();
if (list1.get(i).getItemid() == list2.get(j).getItemid()) {
sumXY += (rating1 - avgX) * (rating2 - avgY);
}
}
}
return sumXY / (Math.sqrt(sumX * sumY));
}
标签:
原文地址:http://www.cnblogs.com/gcczhongduan/p/4173676.html