标签:
一:课程简介:
Hadoop是当下云计算大数据的王者。
Hadoop不仅是一个大数据的计算框架,同时也是大数据的存储平台。
使用Hadoop,用户可以在不了解分布式底层细节的情况下开发出分布式程序,从而可以使用众多廉价的计算设备的集群的威力来高速的运算和存储,而且Hadoop的运算和存储是可靠的、高效的、可伸缩的,能够使用普通的社区服务器出来PB级别的数据,是分布式大数据处理的存储的理想选择
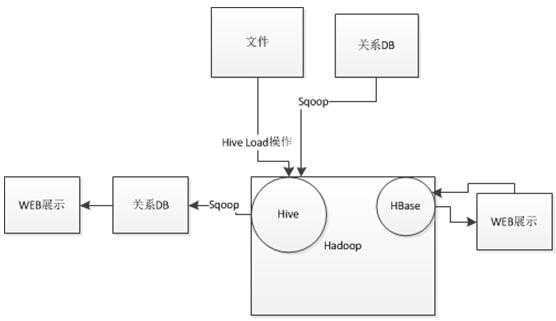
使用Hadoop可以主要完成:
1,构建离线处理平台,完成海量离线数据的存储分析,相对于传统的关系型数据库而言,Hadoop可以处理规模更大,处理逻辑更加复杂的内容,现在企业内部多使用以Hive为中心的处理模式;
2,基于Hadoop的子项目HBase可以完成准实时的数据处理;
“云计算分布式大数据Hadoop最佳实践”基于实务经验萃取而成,从Hadoop开发环境的搭建到到图片服务器、WordCount实现、HBase微博系统、话单查询与统计、Hive数据统计案例、电商业日志流量分析项目理论结合实际案例,祝你轻松驾驭Hadoop以满足大数据的分布式处理与存储。
课程以MapReduce、HBase、Hive为主轴,想理解和使用Hadoop,就必须掌握这三大核心。
尤其值得注意的是,在该课程的最新版本中加入了很多Hadoop框架本身的源码内核解析,这直接为成为Hadoop奠定坚实的基础。
二:课程特色
Hadoop领域4个开创先河
1,全程覆盖Hadoop的所有核心内容
2,全程注重动手实作,循序渐进中掌握Hadoop企业级实战技术
3,在授课的过程中会对Hadoop的核心源码进行深度剖析,使得学员具有改造Hadoop框架的能力
4,具备掌握Hadoop完整项目的分析、开发、部署的全过程的能力
三:适合对象:
1, 云计算大数据从业者;
2, 软件工程师;
3, 数据库开发人员;
4, 数据库开发人员;
5, 运维人员;
6, 系统架构师、系统分析师、高级程序员、资深开发人员;
7, 牵涉到大数据处理的数据中心运行、规划、设计负责人;
8, 政府机关,金融保险、移动和互联网等大数据来源单位的负责人;
9, 高校、科研院所涉及到大数据与分布式数据处理的项目负责人;
10, 数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员;
四:基础要求
了解Linux系统;
了解网络;
了解Java;
五:讲师简介
中国目前唯一的移动互联网和云计算大数据集大成者;
云计算大数据Spark亚太研究院院长和首席专家;
Spark亚太研究院院长和首席专家,Spark源码级专家,对Spark潜心研究(2012年1月起)2年多后,在完成了对Spark的13不同版本的源码的彻底研究的同时不断在实际环境中使用Spark的各种特性的基础之上,编写了世界上第一本系统性的Spark书籍并开设了世界上第一个系统性的Spark课程并开设了世界上第一个Spark高端课程(涵盖Spark内核剖析、源码解读、性能优化和商业案例剖析)。Spark源码研究狂热爱好者,醉心于Spark的新型大数据处理模式改造和应用。
Hadoop源码级专家,曾负责某知名公司的类Hadoop框架开发工作,专注于Hadoop一站式解决方案的提供,同时也是云计算分布式大数据处理的最早实践者之一,Hadoop的狂热爱好者,不断的在实践中用Hadoop解决不同领域的大数据的高效处理和存储,现在正负责Hadoop在搜索引擎中的研发等,著有《云计算分布式大数据Hadoop实战高手之路---从零开始》《云计算分布式大数据Hadoop实战高手之路---高手崛起》《云计算分布式大数据Hadoop。实战高手之路---高手之巅》等;
Android架构师、高级工程师、咨询顾问、培训专家;
通晓Android、HTML5、Hadoop,迷恋英语播音和健美;
致力于Android、HTML5、Hadoop的软、硬、云整合的一站式解决方案;
国内最早(2007年)从事于Android系统移植、软硬整合、框架修改、应用程序软件开发以及Android系统测试和应用软件测试的技术专家和技术创业人员之一。
HTML5技术领域的最早实践者(2009年)之一,成功为多个机构实现多款自定义HTML5浏览器,参与某知名的HTML5浏览器研发;
超过10本的IT畅销书作者;
六:培训内容
|
时间 |
内容 |
备注 |
|
第一天 |
第1个主题:Hadoop思考 1.Hadoop的设计目标和适用场景 2.Hadoop架构解析 3.MapReduce工作原理和案例说明
第2个主题:Hadoop集群与管理 1、 Hadoop集群的搭建 2、 Hadoop集群的监控 3、 Hadoop集群的管理 4、 集群下运行MapReduce程序
第3主题:彻底掌握HDFS (具备修改HDFS具体源码实现的能力) 1、HDFS体系架构剖析 2、NameNode、DataNode、SecondaryNameNode架构 3、保证NodeName高可靠性最佳实践 4、DataNode中Block划分的原理和具体存储方式 5、修改Namenode、DataNode数据存储位置 6、使用CLI操作HDFS 7、使用Java操作HDFS
第4主题:彻底掌握HDFS (具备修改HDFS具体源码实现的能力) 1、RPC架构剖析 2、源码剖析Hadoop构建于RPC之上 3、源码剖析HDFS的RPC实现 4、源码剖析客户端与与NameNode的RPC通信
第5个主题:彻底掌握MapReduce(从代码的角度剖析MapReduce执行的具体过程并具备开发MapReduce代码的能力) 1、MapReduce执行的经典步骤 2、wordcount运行过程解析 3、Mapper和Reducer剖析 4、自定义Writable 5、新旧API的区别以及如何使用就API 6、把MapReduce程序打包成Jar包并在命令行运行
第6个主题:彻底掌握MapReduce(具备掌握Hadoop如何把HDFS文件转化为Key-Value让供Map调用的能力) 1、 Hadoop是如何把HDFS文件转化为键值对的? 2、 源码剖析Hadoop读取HDFS文件并转化为键值对的过程实现 3、 源码剖析转化为键值对后供Map调用的过程实现
第7个主题:彻底掌握MapReduce(具备掌握MapReduce内部运行和实现细节并改造MapReduce的能力) 1、 Hadoop内置计数器及如何自定义计数器 2、 Combiner具体的作用和使用以及其使用的限制条件 3、 Partitioner的使用最佳实践 4、 Hadoop内置的排序算法剖析 5、 自定义排序算法 6、 Hadoop内置的分组算法 7、 自定义分组算法 8、 MapReduce常见场景和算法实现
|
|
|
时间 |
内容 |
备注 |
|
第二天 |
第1个主题:HBase架构设计和实现剖析 1、 HBase定义 2、 HBase与RDBMS的对比 3、 数据模型 4、 系统架构 5、 HBase上的MapReduce 6、 表的设计
第2个主题:HBase集群及其管理 1、 集群的搭建过程讲解 2、 集群的监控 3、 集群的管理
第3个主题:HBase客户端 1、 HBase Shell以及演示 2、 Java客户端以及代码演示
第4个主题:HBase案例实战1---使用HBase实现微博系统 1. 项目架构和设计 2. 开发环境搭建 3. 实现用户登录和注销 4.“关注”功能的设计和实现 5.“发微博”功能的设计和实现 6.发布和运行整个基于HBase的微博系统
第5个主题:HBase与MapReduce 1. HBase与MapReduce的关系 2. HBase如何使用MapReduce
第6个主题:HBase案例实战2---话单查询与统计 1. 项目架构设计 2. 开发环境搭建 3. 话单入库和查询的设计与实现 4.统计功能的设计与实现
第7个主题:安装和使用Hive 1. Hive剖析 2. 安装Hive 3.Hive的基本使用
第8个主题:Hive与HDFS、MapReduce 1. Hive向HDFS存入结构化数据 2. 使用MySQL作为Hive的元数据库 3.Hive与MapReduce
|
|
|
时间 |
内容 |
备注 |
|
第三天 |
第1个主题:Hive 1. Hive的Java扩展开发 2. Hive UDF和UDAF开发 3. Hive常见场景,实战练习
第2个主题:Hive案例实战---数据统计 1. 项目架构设计 2. 表结构设计 3.数据的插入与统计实现
第3个主题:Sqoop 1. Sqoop原理 2. Sqoop使用详解 3. 用Sqoop实现HDFS/Hive与关系数据库的数据交互 4. 用Sqoop实现HBase与关系数据库的数据交互
第4个主题:电商业日志流量分析项目 电商业日志流量分析项目,互联网企业对海量日志的分析是Hadoop应用的一个重要用途,也是对网站流量、客户行为分析的重要途径。该项目整合Hive、Hbase、Sqoop等常用组件,涉及从后台处理到前台呈现的每一个技术环节。包括: 1·业务需求介绍 2·数据建模 3·后台算法设计 4·后台业务处理 5·前台WEB展示等
第5个主题:Hadoop开发者之路 1. Hadoop技能模型 2. Hadoop开发者最佳学习路线和方式 3.Hadoop开发者最佳成长路线
|
|
标签:
原文地址:http://www.cnblogs.com/wangyanjun/p/4174976.html