标签:
如何把云计算大数据处理速度提高100倍以上?Spark给出了答案。
Spark是可以革命Hadoop的目前唯一替代者,能够做Hadoop做的一切事情,同时速度比Hadoop快了100倍以上,下图来自Spark的官方网站:
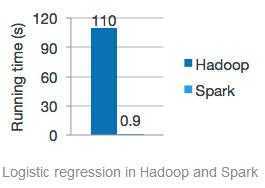
Logistic regression in Hadoop and Spark
可以看出在Spark特别擅长的领域其速度比Hadoop快120倍以上!
Spark是基于内存,是云计算领域的继Hadoop之后的下一代的最热门的通用的并行计算框架开源项目,尤其出色的支持Interactive Query、流计算、图计算等。
Spark在机器学习方面有着无与伦比的优势,特别适合需要多次迭代计算的算法。同时Spark的拥有非常出色的容错和调度机制,确保系统的稳定运行,Spark目前的发展理念是通过一个计算框架集合SQL、Machine Learning、Graph Computing、Streaming Computing等多种功能于一个项目中,具有非常好的易用性。
目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、NoSQL查询等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年在社区和商业应用上会有爆发式的增长。
国内的淘宝、优酷土豆等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛,国外一些大型互联网公司已经部署了Spark。甚至连Yahoo是Hadoop的早期主要贡献者,现在也在多个项目中部署使用Spark,国内我们已经在运营商、电商等传统行业部署了Spark。
课程介绍
鉴于Spark的巨大价值和潜力,同时由于国内极度缺乏Spark人才,家林在对Spark潜心研究(2012年1月起)2年多后,在完成了对Spark源码的彻底研究的同时不断在实际环境中使用Spark的各种特性的基础之上,编写了世界上第一本系统性的Spark书籍并开设了世界上第一个系统性的Spark课程,课程包含Spark的集群系统运作原理、Spark的编程模型和语言、Spark框架源码剖析、Spark的流处理框架Spark Streaming、Shark、Machine Learning on Spark以及Spark多语言编程,同时对Spark的测试,最后涵盖了使用Spark的一些最佳实践(如何调优、并发的限制、日志的查看、序列化和反序列化等),从零基础入门到达商业级实战,祝你和公司轻松驾驭Spark,从此自由翱翔于云计算大数据的天空!
培训对象
1, 云计算大数据从业者;
2, Hadoop使用者;
3, 系统架构师、系统分析师、高级程序员、资深开发人员;
4, 牵涉到大数据处理的数据中心运行、规划、设计负责人;
5, 政府机关,金融保险、移动和互联网等大数据来源单位的负责人;
6, 高校、科研院所涉及到大数据与分布式数据处理的项目负责人;
7, 数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员;
学员基础
了解面向对象编程;
了解Linux的基本使用;
王家林老师
中国目前唯一的移动互联网和云计算大数据集大成者;
云计算大数据Spark亚太研究院院长和首席专家;
王家林老师(联系邮箱18610086859@126.com 电话:18610086859 QQ:1740415547 微信号:18610086859)
Spark亚太研究院院长和首席专家,Spark源码级专家,对Spark潜心研究(2012年1月起)2年多后,在完成了对Spark的14不同版本的源码的彻底研究的同时不断在实际环境中使用Spark的各种特性的基础之上,编写了世界上第一本系统性的Spark书籍并开设了世界上第一个系统性的Spark课程并开设了世界上第一个Spark高端课程(涵盖Spark内核剖析、源码解读、性能优化和商业案例剖析)。Spark源码研究狂热爱好者,醉心于Spark的新型大数据处理模式改造和应用。
Hadoop源码级专家,曾负责某知名公司的类Hadoop框架开发工作,专注于Hadoop一站式解决方案的提供,同时也是云计算分布式大数据处理的最早实践者之一,Hadoop的狂热爱好者,不断的在实践中用Hadoop解决不同领域的大数据的高效处理和存储,现在正负责Hadoop在搜索引擎中的研发等,著有《云计算分布式大数据Hadoop实战高手之路---从零开始》《云计算分布式大数据Hadoop实战高手之路---高手崛起》《云计算分布式大数据Hadoop。实战高手之路---高手之巅》等;
Android架构师、高级工程师、咨询顾问、培训专家;
通晓Android、HTML5、Hadoop,迷恋英语播音和健美;
致力于Android、HTML5、Hadoop的软、硬、云整合的一站式解决方案;
国内最早(2007年)从事于Android系统移植、软硬整合、框架修改、应用程序软件开发以及Android系统测试和应用软件测试的技术专家和技术创业人员之一。
HTML5技术领域的最早实践者(2009年)之一,成功为多个机构实现多款自定义HTML5浏览器,参与某知名的HTML5浏览器研发;
超过10本的IT畅销书作者;
培训内容
|
第一天 |
第1堂课:Spark的架构设计 1.1 Spark的速度为什么如此的快? 1.2 Spark的架构设计剖析 1.3 RDD计算流程解析 1.4 Spark的出色容错机制
第2堂课:实战使用三种语言开发Spark 2.1 Scala简介、为什么Spark会使用Scala作为开发语言? 2.2 在Spark中使用Scala 2.3 使用Java开发Spark程序 2.4 使用Python开发Spark程序 2.5 深入使用Spark Shell
第3堂课:快速掌握Scala 3.1 Scala变量声明、操作符、函数的使用实战 3.2 apply方法 3.3 Scal的控制结构和函数 3.4 Scala数组的操作、Map的操作 3.5 Scala中的类 3.6 Scala中对象的使用; 3.7 Scala中的继承 3.8 Scala中的特质 3.9 Scala中集合操作
第4堂课:Spark集群的安装和设置 4.1 在一台机器上运行Spark 4.2 在EC2上运行Spark 4.3 在Mesos上部署Spark 4.4 在YARN上部署Spark 4.5 通过SSH在众多机器上部署Spark 4.6 Spark集群设置
第5堂课:编写Spark程序 5.1 程序数据的来源:File、HDFS、HBase、S3等 5.2 IDE环境构建 5.3 Maven 5.4 sbt. 5.5 编写并部署Spark程序的实例 |
|
|
时间 |
內 容 |
备注 |
|
第二天 |
第6堂课:SparkContext解析和数据加载以及存储 6.1 源码剖析SparkContext 6.2 Scala、Java、Python使用SparkContext 6.4 加载数据成为RDD 6.5 把数据物化
第7堂课:深入实战RDD 7.1 DAG 7.2 深入实战各种Scala RDD Function 7.3 Spark Java RDD Function 7.4 RDD的优化问题
第8堂课:Shark的原理和使用 8.1 Shark与Hive 8.2 安装和配置Shark 8.3 使用Shark处理数据 8.4 在Spark程序中使用Shark Queries 8.5 SharkServer 8.6 思考Shark架构
第9堂课:Spark程序的测试 9.1 编写可测试的Spark程序 9.2 Spark测试框架解析 9.3 Spark测试代码实战
第10堂课:Spark的优化 10.1 Logs 10.2 并发 10.3 内存 10.4 垃圾回收 10.5 序列化 10.6 安全
|
|
|
时间 |
內 容 |
备注 |
|
第三天 |
第11堂课:Spark的机器学习 11.1 LinearRegression 11.2 K-Means 11.3 Collaborative Filtering
第12堂课:Spark的图计算GraphX 12.1 Table Operators 12.2 Graph Operators 12.3 GraphX
第13堂课:Spark SQL 13.1 Parquet支持 13.2 DSL 13.3 SQL on RDD
第14堂课:Spark实时流处理 14.1 DStream 14.2 transformation 14.3 checkpoint 14.4 性能优化
|
|
18小时内掌握Spark:把云计算大数据速度提高100倍以上
标签:
原文地址:http://www.cnblogs.com/wangyanjun/p/4174953.html