标签:
开篇:在某些场景下,我们想要对百度图片搜出来的东东进行保存,但是一个一个得下载保存不仅耗时而且费劲,有木有一种方法能够简化我们的工作量呢,让我们在离线模式下也能爽爽地浏览大量的美图呢?于是,我们想到了使用网络抓取去帮我们去下载图片,并且保存到我们设定的文件夹中,现在我们就来看看如何来设计开发一个这样的图片批量下载器。
网络蜘蛛的主要作用是从Internet上不停地下载网络资源。它的基本实现思想就是通过一个或多个入口网址来获取更多的URL,然后通过对这些URL所指向的网络资源下载并分析后,再获得这些网络资源中包含的URL,以此类推,直到再没有可下的URL为止。
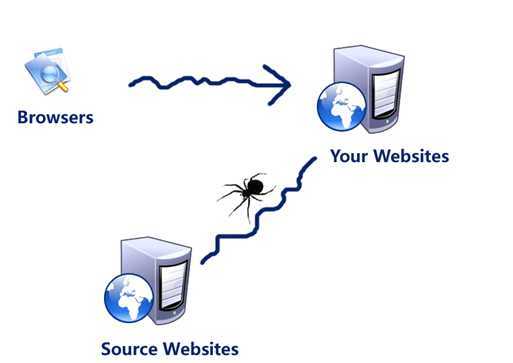
网络蜘蛛的实现的一般步凑可以分为以下几步:
(1) 指定一个(或多个)入口网址{ 如http://www.xx.com),并将这个网址加入到下载队列中(这时下载队列中只有一个或多个入口网址)}。
(2) 负责下载网络资源的线程从下载队列中取得一个或多个URL,并将这些URL所指向的网络资源下载到本地{ 在下载之前,一般应该判断一下这个URL是否已经被下载过,如果被下载过,则忽略这个URL }。如果下载队列中没有URL,并且所有的下载线程都处于休眠状态,说明已经下载完了由入口网址所引出的所有网络资源。这时网络蜘蛛会提示下载完成,并停止下载。
(3)分析这些下载到本地的未分析过的网络资源{ 一般为html代码 },并获得其中的URL{ 如标签<a>中href属性的值 }。
(4)将第3步获得的URL加入到下载队列中,然后重新执行第2步。
在平常的使用中,我们经常会去百度图片搜索图片,然后保存到本地进行浏览或二次使用。但是,如果我们需要使用很多个同一题材的图片的时候,单个地手工去一张一张的下载保存效率就会显得很低下。这时候,我们不由得想找一个方法,让计算机帮我们去做这件事儿!
但是,想破头颅都没想到办法。于是,我们打开F12开发者工具,发现了这么一个AJAX请求,有点意思:
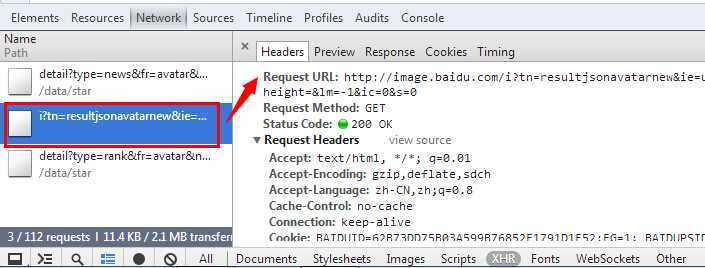
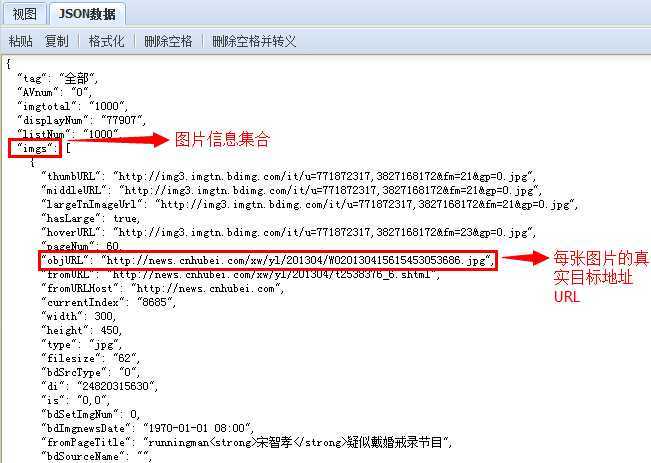
查看这个AJAX请求的HTTP报文信息,发现它返回了一大串的JSON数据,将其复制到JSON在线查看器(http://www.bejson.com/jsonview2/)中查看,原来所有的图片列表信息都在这个JSON中被返回到浏览器端。
(1)看到了上面的那个请求,我们的心中大概就有谱了。在此,我们先来对刚刚那个AJAX请求的地址来分析一下:
Request URL:http://image.baidu.com/i?tn=resultjsonavatarnew&ie=utf-8&word=%E5%AE%8B%E6%99%BA%E5%AD%9D&cg=star&pn=60&rn=60&z=&itg=0&fr=&width=&height=&lm=-1&ic=0&s=0 Request Method:GET Status Code:200 OK
①这个AJAX请求首先是通过GET方式传递的,所有的参数都是通过QueryString的方式跟在URL地址后,也就是所有的参数都在后边跟着,包括我们输入的搜索词,每页的页容量(大小),当前是第几页等参数;
②再来看看这个请求地址后面的参数,找出我们所需要的几个重要参数。其中,word是搜索的关键词,只是后边经过了URL编码,rn是页容量(或者说是页大小,即一页有多少张图片,可以看出默认是60张图片),而pn则代表了是一共请求的图片数量,可以通过pn/rn得到当前是第几页,例如这里pn=60,rn=60,那么请求的是第一页。
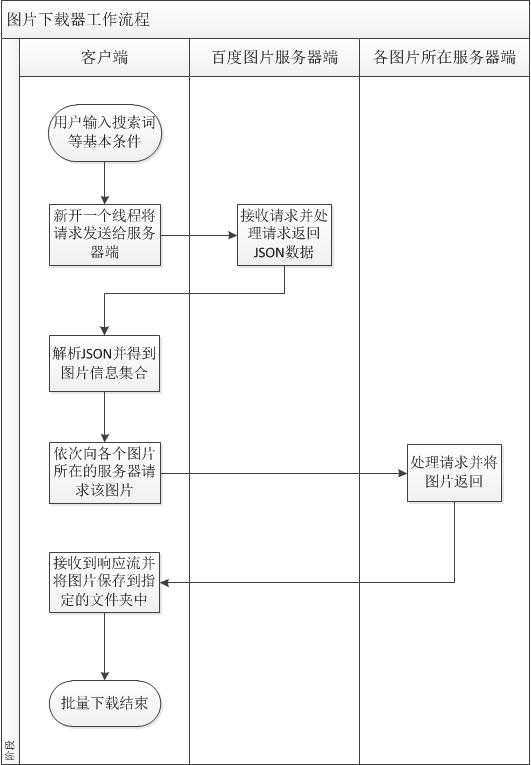
(2)现在我们来梳理一下我们这个下载器的工作流程:
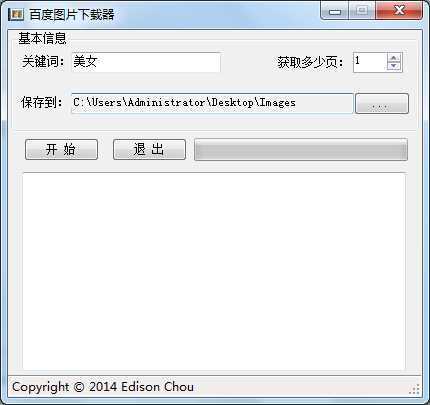
(3)下面我们来看看我们的实现后的图片下载器的样子如何:
// 声明一个异步委托去处理图片下载操作 Action downloadAction = new Action(() => { ProcessDownload(keyword); }); // 声明一个下载完成后的回调函数 AsyncCallback callBack = new AsyncCallback(asyncResult => { downloadAction.EndInvoke(asyncResult); progressBar.BeginInvoke(new Action(() => { progressBar.Value = progressBar.Maximum; })); txtLogs.BeginInvoke(new Action(() => { txtLogs.AppendText("下载图片操作结束!" + Environment.NewLine); })); btnStart.BeginInvoke(new Action(() => { btnStart.Enabled = true; })); }); // 执行该异步委托 IAsyncResult result = downloadAction.BeginInvoke(callBack, null); // 主线程继续干自己的事儿 txtLogs.AppendText("正在下载图片中..." + Environment.NewLine);
使用异步委托,关键在于设置其回调函数,这里在回调函数中结束线程操作,并通过UI控件的BeginInvoke实现安全地跨线程调用(类似于使用委托来操作)。
private void ProcessDownload(string keyword) { int pageCount = (int)numPageCount.Value; sumCount = pageCount * 60; for (int i = 0; i < pageCount; i++) { HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://image.baidu.com/i?tn=resultjsonavatarnew&ie=utf-8&word=" + Uri.EscapeDataString(keyword) + "&pn=" + pageCount * 60 + "&cg=girl&rn=60&itg=0&lm=-1&ic=0&s=0"); using (HttpWebResponse response = (HttpWebResponse)request.GetResponse()) { if (response.StatusCode == HttpStatusCode.OK) { using (Stream stream = response.GetResponseStream()) { try { // 下载指定页的所有图片 DownloadPage(stream); } catch (Exception ex) { // 跨线程访问UI线程的txtLogs txtLogs.BeginInvoke(new Action(() => { txtLogs.AppendText(ex.Message + Environment.NewLine); })); } } } else { MessageBox.Show("获取第" + pageCount + "页失败:" + response.StatusCode); } } } }
这里使用了try..catch将下载时碰到的异常信息填充到了TextBox文本框中。
private void DownloadPage(Stream stream) { using (StreamReader reader = new StreamReader(stream)) { string jsonData = reader.ReadToEnd(); // 解析JSON,分析JSON JObject objectRoot = JsonConvert.DeserializeObject(jsonData) as JObject; JArray imgsArray = objectRoot["imgs"] as JArray; for (int i = 0; i < imgsArray.Count; i++) { JObject img = imgsArray[i] as JObject; string objUrl = (string)img["objURL"]; //txtLogs.AppendText(objUrl + Environment.NewLine); // 测试获取图片路径 try { // 下载具体的某一张图片 DownloadImage(objUrl); // 更新进度条 progressBar.BeginInvoke(new Action(() => { progressBar.Value = i * 100 / sumCount; })); // 更新文本框 txtLogs.BeginInvoke(new Action(() => { txtLogs.AppendText("已下载:" + objUrl + Environment.NewLine); })); } catch (Exception ex) { // 跨线程访问UI线程的txtLogs控件 txtLogs.BeginInvoke(new Action(() => { txtLogs.AppendText("【异常:" + ex.Message + "】" + Environment.NewLine); })); } } } }
这里使用的是Newtonsoft.Json组件,在返回的JSON数据中,找到imgs集合,对其进行遍历,找出其中的objURL并一一地进行下载到本地。
private void DownloadImage(string objUrl) { string destFileName = Path.Combine(destDir, Path.GetFileName(objUrl)); HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(objUrl); // 欺骗服务器判断URLReferer request.Referer = "http://image.baidu.com"; using (HttpWebResponse response = (HttpWebResponse)request.GetResponse()) { if (response.StatusCode == HttpStatusCode.OK) { using (Stream stream = response.GetResponseStream()) { using (FileStream fileStream = new FileStream(destFileName, FileMode.Create)) { stream.CopyTo(fileStream); } } } else { throw new Exception("下载" + objUrl + "失败,错误码:" + response.StatusCode); } } }
这里通过在客户端伪造URLRerfer让服务器端误以为是自己的站内请求(伪造我们的请求不是骗它流量的),然后通过FileStream将返回的图片响应流保存到指定的文件夹中。
这里我们批量下载一页(60张)的美女图片到指定的文件夹中,看看下载器是否真的帮助我们下载了图片:
(1)程序的运行过程:
(2)下载后的图片文件夹:
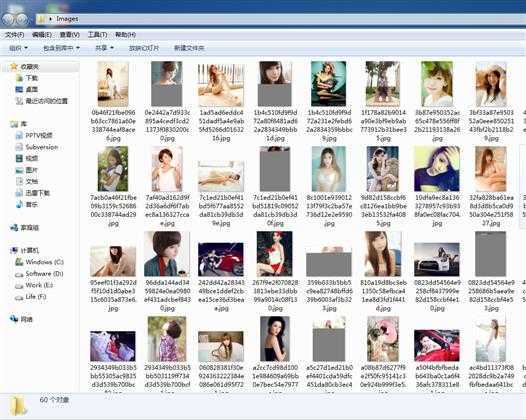
这里我们将“美女”改为了“宋智孝”后,发现下载器未能成功下载图片。经过分析,原来百度图片搜索中,每个搜索词所生成的AJAX请求都不同,因此本下载器目前不具有通用性,也就是说每次更换搜索词都需要改代码,主要是改HttpWebRequest那的URL地址。
(1)更改URL处的代码: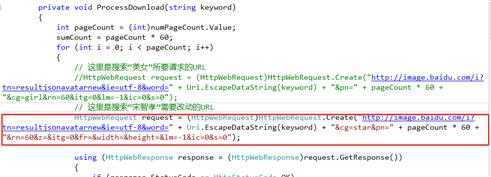
(2)程序的运行过程: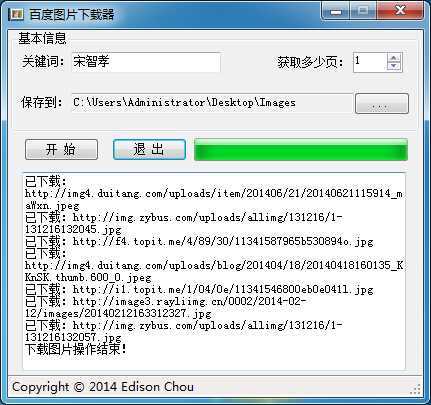
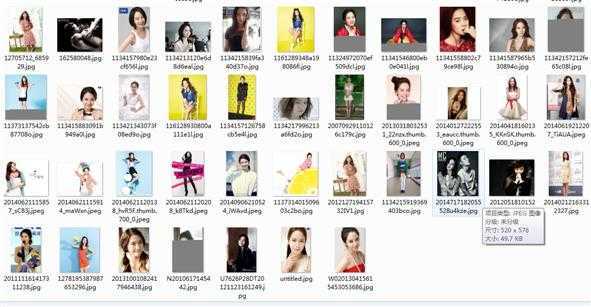
(3)下载的图片文件:
本次我们实现了一个小工具,它可以帮我们下载我们想要搜索的图片到执行的图片文件夹中,让我们可以离线爽爽地看美图。设计开发这样一个工具,最重要的莫过于:分析Http报文、解析返回数据、线程创建与同步、异步操作、文件流、进度条的更新(跨线程的调用)等等,本次开发中都多多少少涉及到了其中的一些东东。当然,不足之处还有很多,例如工具的通用性不足,每次更换搜索词都需要更改代码,可配置型不高等等。这里提供一个我的代码实现DEMO,有兴趣的朋友也可以自行修改并进行扩展。
(1)杨中科,《自己动手写美女图片下载器》:http://www.rupeng.com/Courses/Index/14
(2)冰封的心,《C#2.0实现抓取网络资源的网络蜘蛛》:http://www.cnblogs.com/yibinboy/articles/1236356.html
MyPictureDownloader v1.0:http://pan.baidu.com/s/1kTvFlJp
标签:
原文地址:http://www.cnblogs.com/edisonchou/p/4175190.html