标签:
1. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2. Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
3. Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive牛逼的地方就在于:
1. 是基于MapReduce的基础上,支持sql语法
2. 对上传到数据仓库的数据没有任何格式要求
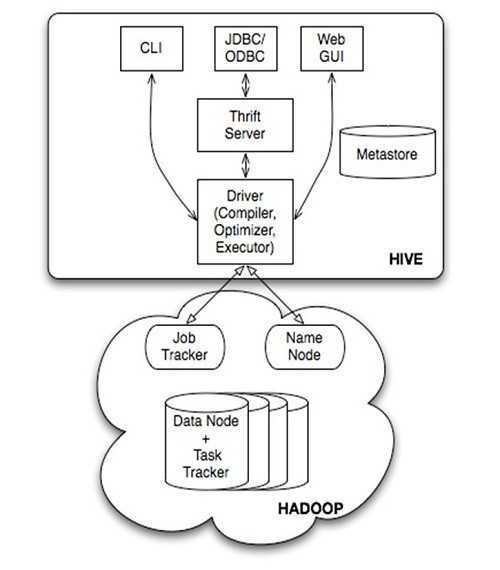
1) CLI,即Shell命令行
2) JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
3) WebGUI是通过浏览器访问 Hive
目前只支持mysql、derby。
Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在HDFS 中,并在随后有MapReduce 调用执行
在HDFS 中,大部分的查询由MapReduce 完成
(包含 * 的查询,特例:select * from table 不会生成 MapRedcue 任务)
标签:
原文地址:http://www.cnblogs.com/Jiangzl/p/4179223.html