标签:
index: proc means | proc freq|proc univariate
/*******************proc means*********************/
PROC MEANS <option(s)> <statistic-keyword(s)>;
BY <DESCENDING> variable-1 <… <DESCENDING>variable-n><NOTSORTED>;
CLASS variable(s) </ option(s)>;
OUTPUT <OUT=SAS-data-set> <output-statistic-specification(s)>
<id-group-specification(s)> <maximum-id-specification(s)>
<minimum-id-specification(s)>
</ option(s)> ;
VAR
variable(s) < / WEIGHT=weight-variable>;
主要功能:The MEANS procedure provides data summarization tools to compute descriptive statistics for variables across all observations and within groups of observations(计算描述性统计量,比如均值方差等,还可以用来做置性区间的计算)
常用用法:
-
calculates descriptive statistics based on moments 计算基于矩的描述性统计量,如均值、方差、标准差、偏度、峰度
-
estimates quantiles, which includes the median 计算分位数
-
calculates confidence limits for the mean 计算均值的置性区间
-
identifies extreme values 极值
<option(s)>常用项:
data=<制定输入的数据集>
(field width)fw=<specifies the field width to display the statistics in printed or displayed output>
maxdec=<specifies the maximum number of decimal places to display the statistics in the printed or displayed output>
missing= <If you omit MISSING, then PROC MEANS excludes the observations with a missing class variable value from the analysis>
noobs noprint
NWAY:specifies that the output data set contain only statistics for the observations with the highest _TYPE_ and _WAY_ values,使输出数据集中包含_type_和_way_的最大值
<statistic-keyword(s)>
默认输出统计量: std标准差、n观测个数、means均值、min/max
cv 变异系数、 stderr标准误即样本均值的方差、 css偏差平方和、vardef自由度,clm双尾置性区间,LCLM左尾置性区间,UCLM右尾置性区间,
ALPHA=default0.05 (1-置信度)。
Types语句:规定输出结果的分组类型和顺序,其中的变量一定要在class语句中,和class语句中变量的顺序有关
例如class a b c;则 type () a b a*b c a*c b*c a*b*c的type值分别为0 1 2 3 4 5 6 7,type值决定其输出顺序,不同的type类型有些类似tabulate中的table语句,规定以何种变量为分组类型输出;
by语句:必须先排序才能用by语句,by语句进行的分组在输出时会输出两个表,而class不会
var语句:规定需要分析的变量
ID语句:取对应变量的最大值放入数据集;
output语句:规定输出数据集以及要输出的变量
proc means data=school maxdec=2 noprint nway;
/*specifies that the output data set contain only statistics for the observations with the highest _TYPE_ and _WAY_ values*/
class teacher;
class gender region; *两个变量都取0 1两个值,二进制。00 01 10 11;
id t_Age; *id取对应变量的最大值放入数据集;
var pretest posttest gain;
output out=teachersum1(drop= _type_ rename=(_freq_ = number)) *删除变量;
mean=m_pre m_post m_gain ; *单class 下output数据集的表示;
max =
min = /autoname; *autoname很重要,可以和自己起名的变量混用;
run;
| 二进制 |
|
_type_ |
解释 |
| 0 0 |
|
0 |
总平均数 |
| 0 1 |
|
1 |
不同region的平均数 |
| 1 0 |
|
2 |
不同gender的平均数 |
| 1 1 |
|
3 |
单元格平均数 |
class gender region; *两个变量都取0 1两个值,二进制。00 01 10 11;
/*********************proc freq**********************/
PROC FREQ <options>; (order=freq选项,按freq从高到低排序)
BY variables ;
EXACT statistic-options </ computation-options> ;
OUTPUT <OUT=SAS-data-set> options ;
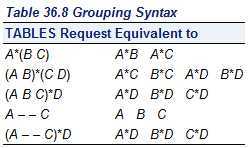
TABLES requests </ options> ; *列出不同变量间组合的频数,也可以做相关性分析;
TEST options ;
WEIGHT variable </ option> ;
tables选项:画出其中规定要输出的变量组合的表格
If you omit the TABLES statement, PROC FREQ generates one-way frequency tables for all data set variables that are not listed in the other statements.
例如含有变量num t1 t2的一张表格,如果限定tables t1;则只会对t1画出相应的频数表,
但是如果省略table,则会画出其他变量的频数表(有一个模糊的条件,这里不一定是画出全部的??????有待考证)
request中的组合方式
</options中常用选项>更多查看sashelp
1:Create an Output Data Set
1.1 out=Names an output data set to contain frequency counts,out只输出table中最后一个数据集,如果想输出多个数据集,则需要写过个table语句
1.2 outexpect= Includes expected frequencies in the output data set
2:Control Statistical Analysis
2.1 nocum 无累加
2.2 nopercent 无百分比 这两个对双向列联表特别有用
3:Control Additional Table Information
/******************proc univariate*******************/
CLASS variable-1 <(v-options)> <variable-2 <(v-options)>> </ KEYLEVEL= value1 | ( value1 value2 )> ;
INSET keyword-list </ options> ;
OUTPUT <OUT=SAS-data-set> <keyword1=names ...keywordk=names> <percentile-options> ;
PPPLOT <variables> < / options> ;
QQPLOT <variables> < / options> ;
主要功能:描述统计量,画图比如QQ PP,还有画分布函数图,频数图,箱线图,正态性检验等(红线部分是与means的区别)
/****************************************************
经验之谈(多个箱线图一起能很好的了解一个变量不同水平的数据分布的情况)
*****************************************************/
options的选项有
normal:进行正态性检验 <Shapiro-Wilk检验,W检验统计量,越接近1越好,拒绝与为w<Wa>;
mu=num1 num2:均值的假设检验,后面写两个分别对应两个相应的均值
Nextrobs=num;分别呈现的num个最小值和最大值
example!!!!!
proc univatiate data=test normal plot nextrobs=6;
进行正态性检验,画出箱线图,茎叶图,设置6个极端值
proc univariate data=reg.b_fitness;
var Runtime -- Performance;
histogram Runtime -- Performance / normal; /*主要从统计指标上面看*/
probplot Runtime -- Performance /normal (mu=est sigma=est color=red w=2);/*主要从图形来看*/
run;
PROBPLOT <variables> < / options> :The PROBPLOT statement creates a probability plot, which compares ordered variable values with the percentiles of a specified theoretical distribution(主要用来画概率图,也就是
PP图,option中加入你想要做的拟合分布检验的分布名,从概率上检验分布)
< / options>:specify the theoretical distribution for the plot or add features to the plot. If you specify more than one variable, the options apply equally to each variable(具象话理论分布,如果不只一个变量,则对每个变量都适用)You can specify only one option that names a distribution in each PROBPLOT statement(每个PROBPLOT语句只能有一个分布选项,但是可以有很多其他选项), but you can specify any number of other options
options中 EST表示极大似然估计得到的值。
example!!!!!!!!!!!
proc univariate;
probplot Length / normal(mu=10 sigma=0.3 color=red l= w=);*这三个选项对所有分布都适用,对特定分布适用的选项查看sas help!;
run;
l=specifies line type of distribution reference line
w=specifies width of distribution reference line
color=specifies color of distribution reference line
HISTOGRAM <variables> < / options> ;creates histograms and optionally superimposes estimated parametric and nonparametric probability density curves(
建立直方图并往上添加曲线,从图形上检验分布)
proc univariate data=Steel;
histogram Length / normal
midpoints = 5.6 5.8 6.0 6.2 6.4
ctext = blue;
run;
生成直方图,加上正太曲线并制定直方图的重点,然后设置文本的颜色
INSET keyword-list </ options> ;places a box or table of summary statistics, called an
inset, directly in a graph created with a CDFPLOT, HISTOGRAM, PPPLOT, PROBPLOT, or QQPLOT statement(
往图表中添加小的,数据描述表格,可以指定位置)
PROC UNIVARIATE DATA=HTWT;
TITLE "More Descriptive Statistics";
VAR HEIGHT WEIGHT;
HISTOGRAM HEIGHT / MIDPOINTS=60 TO 75 BY 5 NORMAL;
INSET MEAN (5.2) /*不输入别名会显示系统自定义的命名,5.2是wd*/
STD=‘Standard Deviation‘ (6.3)/ FONT=‘Arial‘
POS=NW /*插入小表格的位置*/
HEIGHT=3;
RUN;
sas定量数据描述常用过程-数据探索
标签:
原文地址:http://www.cnblogs.com/yican/p/4051899.html