我们先看下 HBase 的写流程:
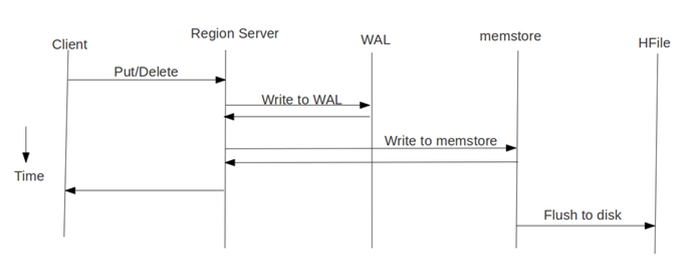
通常 MapReduce
在写HBase时使用的是TableOutputFormat方式,在map/reduce中直接生成put对象写入HBase,该方式在大量数据写入时效率低下,因为HBase会block写入,频繁进行flush、split、compact等大量IO操作,这样对HBase节点的稳定性也会造成一定的影响,例如GC时间过长,响应变慢,导致节点超时退出,并引起一系列连锁反应,而HBase支持BulkLoad的写入方式,它是利用HBase数据按照特定格式存储在HDFS内这一原理,直接利用MapReduce生成持久化的HFile数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载,在大数据量写入时能极大的提高写入效率,并降低对HBase节点的写入压力。
通过使用先生成HFile,然后再BulkLoad到HBase的方式来替代之前直接调用HTableOutputFormat的方法有如下的好处:
(1)消除了对HBase集群的插入压力
(2)提高了Job的运行速度,降低了Job的执行时间
BulkLoad原理已在上面介绍,其具体实现流程是先用MapReduce生成HFile文件输出并且存储在HDFS上,然后利用loader.doBulkLoad(HFIle,HBaseTable);写入HBase中。具体代码如下:
public class BulkLoad {
private static final String JOBNAME = "BulkLoad";
private static final String TABLENAME = "bulkLoad";
private static final String PATH_IN = "/xx/xx"; //输入路径
private static final String PATH_OUT = "/xx/xx"; //输入路径
private static final String SEPARATOR = "\\|";
private static final byte[] ColumnFamily = "f".getBytes(); // 列簇
private static final byte[] QUALIFIER_TAG1 = "tag1".getBytes(); // 列名
private static final byte[] QUALIFIER_TAG2 = "tag2".getBytes();
private static final byte[] QUALIFIER_TAG3 = "tag3".getBytes();
private static final byte[] QUALIFIER_TAG4 = "tag4".getBytes();
private static final byte[] QUALIFIER_TAG5 = "tag5".getBytes();
private static final byte[] QUALIFIER_TAG6 = "tag6".getBytes();
private static final byte[] QUALIFIER_TAG7 = "tag7".getBytes();
private static final byte[] QUALIFIER_TAG8 = "tag8".getBytes();
private static final byte[] QUALIFIER_TAG9 = "tag9".getBytes();
private static final byte[] QUALIFIER_TAG10 = "tag10".getBytes();
public static class Map extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] strArr = value.toString().split(SEPARATOR);
String row = strArr[0];
Put put = new Put(Bytes.toBytes(row.toString())); // rowkey
put.add(ColumnFamily, QUALIFIER_TAG1, Bytes.toBytes(strArr[2]));
put.add(ColumnFamily, QUALIFIER_TAG2, Bytes.toBytes(strArr[3]));
put.add(ColumnFamily, QUALIFIER_TAG3, Bytes.toBytes(strArr[4]));
put.add(ColumnFamily, QUALIFIER_TAG4, Bytes.toBytes(strArr[5]));
put.add(ColumnFamily, QUALIFIER_TAG5, Bytes.toBytes(strArr[6]));
put.add(ColumnFamily, QUALIFIER_TAG6, Bytes.toBytes(strArr[7]));
put.add(ColumnFamily, QUALIFIER_TAG7, Bytes.toBytes(strArr[8]));
put.add(ColumnFamily, QUALIFIER_TAG8, Bytes.toBytes(strArr[9]));
put.add(ColumnFamily, QUALIFIER_TAG9, Bytes.toBytes(strArr[10]));
put.add(ColumnFamily, QUALIFIER_TAG10, Bytes.toBytes(strArr[11]));
context.write(new ImmutableBytesWritable(value.getBytes()), put);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "xx,xx,xx");
Job job = new Job(conf, JOBNAME);
job.setJarByClass(CreditScoreBulkLoad.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setMapperClass(Map.class);
//这个 SorterReducer(KeyValueSortReducer或PutSortReducer) 可以不指定,
//因为源码中已经做了判断
job.setReducerClass(PutSortReducer.class);
job.setOutputFormatClass(HFileOutputFormat.class);
FileSystem fs = FileSystem.get(URI.create("/"),conf);
Path outPath = new Path(PATH_OUT);
if (fs.exists(outPath))fs.delete(outPath, true);
FileInputFormat.setInputPaths(job, new Path(PATH_IN));
FileOutputFormat.setOutputPath(job, outPath);
HTable table = new HTable(conf, TABLENAME);
HFileOutputFormat.configureIncrementalLoad(job, table);
if(job.waitForCompletion(true)){
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(conf);
loader.doBulkLoad(outPath, table);
}
System.exit(0);
}
}3、说明与注意事项:
(0)上文提到会将生成的HFile文件插入HBase中,在此过程中由MapReduce生成的存储在HDFS上的文件会消失,其实插入HBase就是将HFile文件移到HBase中,但是HFile文件在HDFS上的存储路径还在,只是里面的文件消失了。
(1)利用BulkLoad导入HBase时,定记得在建表时做region的预切分(随后会对HBase的Region进行总结),HFileOutputFormat.configureIncrementalLoad方法会根据region的数量来觉得reduce的数量以及每个reduce覆盖的rowkey范围。否则当个reduce过大,任务处理不均衡,导致任务运行时间过长。
(2)单个rowkey下的子列不要过多,否则在reduce阶段排序的时候会造成oom,有一种办法是通过二次排序来避免reduce阶段的排序,看应用而定。
(3)该代码执行完后需要将hdfs中生成好的hfile写入到hbase表中。采用hadoop jar hbase-version.jar completebulkload /hfilepath tablename 命令实现。
(4)HFile方式在所有的加载方案里面是最快的,不过有个前提——数据是第一次导入,表是空的。如果表中已经有了数据。HFile再导入到hbase的表中会触发split操作。
(5)最终输出结果,无论是map还是reduce,输出部分key和value的类型必须是: < ImmutableBytesWritable, KeyValue>或者< ImmutableBytesWritable, Put>。
否则报这样的错误:
java.lang.IllegalArgumentException: Can‘t read partitions file ... Caused by: java.io.IOException: wrong key class: org.apache.hadoop.io.*** is not class org.apache.hadoop.hbase.io.ImmutableBytesWritable
(6)最终输出部分,Value类型是KeyValue 或Put,对应的Sorter分别是KeyValueSortReducer或PutSortReducer,这个 SorterReducer 可以不指定,因为源码中已经做了判断:
if (KeyValue.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(KeyValueSortReducer.class);
} else if (Put.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(PutSortReducer.class);
} else {
LOG.warn("Unknown map output value type:" + job.getMapOutputValueClass());
}(7)
MR例子中job.setOutputFormatClass(HFileOutputFormat.class);
HFileOutputFormat只适合一次对单列族组织成HFile文件,多列簇需要起多个job,不过新版本的 Hbase
已经解决了这个限制。
(8) MR例子中最后生成HFile存储在HDFS上,输出路径下的子目录是各个列族。如果对HFile进行入库HBase,相当于move HFile到HBase的Region中,HFile子目录的列族内容没有了。
(9)最后一个 Reduce 没有 setNumReduceTasks 是因为,该设置由框架根据region个数自动配置的。
(10)下边配置部分,注释掉的其实写不写都无所谓,因为看源码就知道configureIncrementalLoad方法已经把固定的配置全配置完了,不固定的部分才需要手动配置。
1、http://blog.csdn.net/kirayuan/article/details/6371635
2、http://blog.pureisle.net/archives/1950.html
3、http://shitouer.cn/2013/02/hbase-hfile-bulk-load
4、http://my.oschina.net/leejun2005/blog/187309
本文出自 “混混” 博客,请务必保留此出处http://yimaoqian.blog.51cto.com/1328422/1595649
原文地址:http://yimaoqian.blog.51cto.com/1328422/1595649