标签:
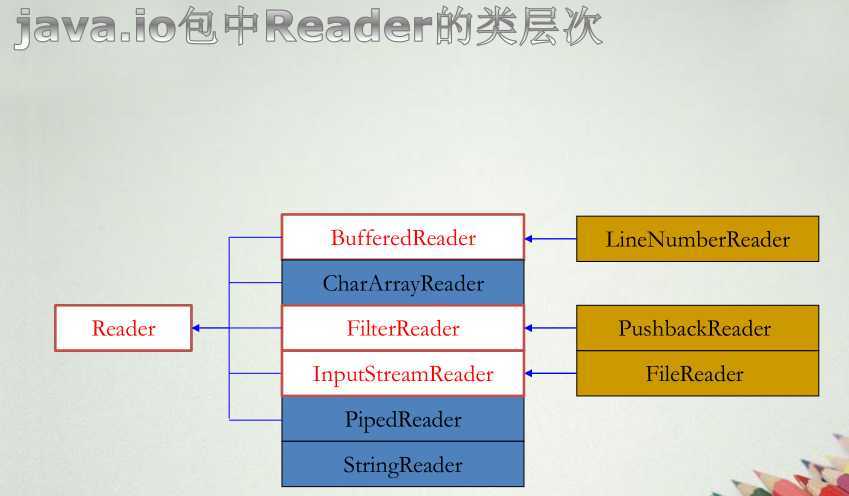
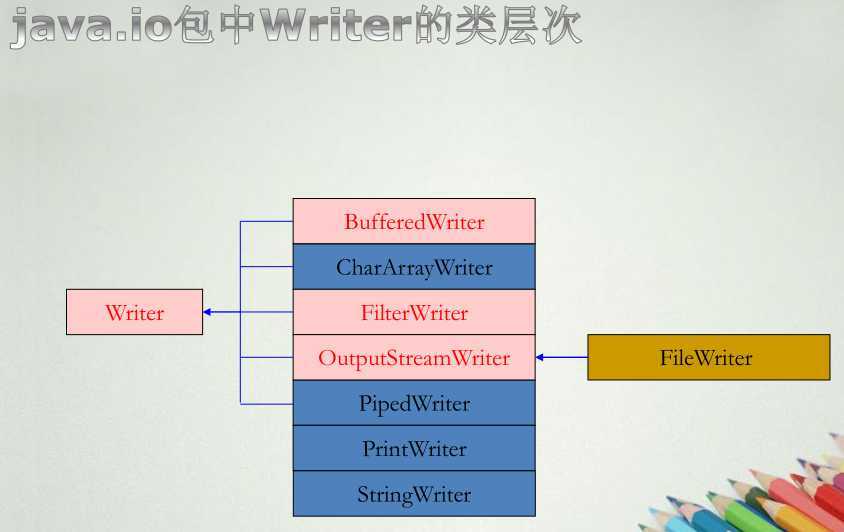
1. 由于Java采用16位的Unicode字符,因此需要基于字符的输入/输出操作。从Java1.1版开始,加入了专门处理字符流的抽象类Reader和Writer,前者用于处理输入,
后者用于处理输出。
2. Java程序语言使用Unicode来表示字符串和字符,Unicode使用两个字节来表示一个字符,即一个字符占16位
3. 字节流的编码规范与具体的平台有关,可以在构造流对象时指定规范,也可以使用当前平台的缺省规范
InputStreamReader和OutputStreamWriter
1. InputStreamReader和OutputStreamWriter是java.io包中用于处理字符流的基本类,用来在字节流和字符流之间搭一座“桥”。
2. InputStreamReader的构造方法:
public InputSteamReader(InputSteam in)
public InputSteamReader(InputSteam in,String enc)
3. OutputStreamWriter的构造方法:
public OutputStreamWriter(OutputStream out)
public OutputStreamWriter(OutputStream out,String enc)
4. enc为指定的编码规范(若无此参数,表示使用当前平台的缺省规范,可用getEncoding()方法得到当前字符流所用的编码方式)
5. 读写字符的方法read()、write(),关闭流的方法close()等与Reader和Writer类的同名方法用法都是类似的。
FileReader和FileWriter:
1. FileReader类创建了一个可以读取文件内容的Reader类。FileReader继承于InputStreamReader。它最常用的构造方法显示如下:
FileReader(String filePath)
FileReader(File fileObj)
每一个都能引发一个FileNotFoundException异常。这里,filePath是一个文件的完整路径,fileObj是描述该文件的File 对象
2. FileWriter 创建一个可以写文件的Writer类。 FileWriter继承于OutputStreamWriter.它最常用的构造方法如下:
FileWriter(String filePath)
FileWriter(String filePath, boolean append)
FileWriter(File fileObj)
append :如果为 true,则将字节写入文件末尾处,而不是写入文件开始处
3. FileWriter类的创建不依赖于文件存在与否。在创建文件之前,FileWriter将在创建对象时打开它来作为输出。如果你试图打开一个只读文件,将引发一个IOException异常
CharArrayReader和CharArrayWriter:
1. CharArrayReader 是一个把字符数组作为源的输入流的实现。该类有两个构造方法,每一个都需要一个字符数组提供数据源:
CharArrayReader(char array[ ])
CharArrayReader(char array[ ], int start,int numChars)
这里,array是输入源。第二个构造方法从你的字符数组的子集创建了一个Reader,该子集以start指定的索引开始,长度为numChars
2. CharArrayWriter 实现了以数组作为目标的输出流。CharArrayWriter 有两个构造方法:
CharArrayWriter( )
CharArrayWriter(int numChars)
第一种形式,创建了一个默认长度的缓冲区。第二种形式,缓冲区长度由numChars指定。缓冲区保存在CharArrayWriter的buf 成员中。缓冲区大小在需要的情况下可以
自动增长。 缓冲区保持的字符数包含在CharArrayWriter的count 成员中。buf 和count 都是受保护的域(protected)
BufferedReader和BufferedWriter:
1. BufferedReader 通过缓冲输入提高性能。它有两个构造方法:
BufferedReader(Reader inputStream)
BufferedReader(Reader inputStream, int bufSize)
第一种形式创建一个默认缓冲区长度的缓冲字符流。第二种形式,缓冲区长度由bufSize传入
2. 和字节流的情况相同,缓冲一个输入字符流同样提供支持可用缓冲区中流内反向移动的基础。为支持这点,BufferedReader 实现了mark()和reset()方法,
并且BufferedReader.markSupported( ) 返回true
3. BufferedWriter是一个增加了flush( )方法的Writer。flush( )方法可以用来确保数据缓冲区确实被写到实际的输出流。用BufferedWriter可以通过减小数据被实际的写到
输出流的次数而提高程序的性能。
4. BufferedWriter有两个构造方法:
BufferedWriter(Writer outputStream)
BufferedWriter(Writer outputStream, int bufSize)
第一种形式创建了使用默认大小缓冲区的缓冲流。第二种形式中,缓冲区大小是由bufSize参数传入的
PushbackReader:
1. PushbackReader类允许一个或多个字符被送回输入流。这使你可以对输入流进行预测。下面是它的两个构造方法:
PushbackReader(Reader inputStream)
PushbackReader(Reader inputStream,int bufSize)
第一种形式创建了一个允许单个字节被推回的缓冲流。第二种形式,推回缓冲区的大小由bufSize参数传入
2. PushbackReader 提供了unread( )方法。该方法返回一个或多个字符到调用的输入流。它有下面的三种形式:
void unread(int ch)
void unread(char buffer[ ])
void unread(char buffer[ ], int offset, int numChars)
第一种形式推回ch传入的字符。它是被并发调用的read( )返回的下一个字符。第二种形式返回buffer中的字符。第三种形式推回buffer中从offset
开始的numChars个字符。如果在推回缓冲区为满的条件下试图返回一个字符,一个IOException异常将被引发
ObjectOutputStream和ObjectInputStream:
1. ObjectOutput接口:ObjectOutput 继承DataOutput接口并且支持对象序列化。特别注意writeObject( )方法,它被称为序列化一个对象。所有这些方法在出错情况下引发
IOException 异常。
2. ObjectOutputStream类继承OutputStream 类和实现ObjectOutput 接口。它负责向流写入对象。该类的构造方法如下:
ObjectOutputStream(OutputStream outStream) throws IOException 参数outStream 是序列化的对象将要写入的输出流
3. ObjectInput 接口继承DataInput接口。它支持对象序列化。特别注意 readObject( )方法,它叫反序列化对象。所有这些方法在出错情况下引发IOException 异常
4. ObjectInputStream 继承InputStream 类并实现ObjectInput 接口。ObjectInputStream 负责从流中读取对象。该类的构造方法如下:
ObjectInputStream(InputStream inStream) throws IOException,StreamCorruptedException 参数inStream 是序列化对象将被读取的输入流。
RandomAccessFile
1. RandomAccessFile包装了一个随机访问的文件,即可以作为输入流,也可以作为输出流。它不是派生于InputStream和OutputStream,而是实现定义了基本输入/输出方法
的DataInput和DataOutput接口。它支持定位请求——也就是说,可以在文件内部放置文件指针。它有两个构造方法:
RandomAccessFile(File fileObj, String access) throws FileNotFoundException
RandomAccessFile(String filename, String access) throws FileNotFoundException
第一种形式,fileObj指定了作为File 对象打开的文件的名称。第二种形式,文件名是由filename参数传入的。两种情况下,access 都决定允许访问何种文件类型。如果是“r”,
那么文件可读不可写,如果是“rw”,文件以读写模式打开
2. RandomAccessFile类同时实现了DataInput和DataOutput接口,提供了对文件随机存取的功能,利用这个类可以在文件的任何位置读取或写入数据
3. 常用方法:
public long getFilePointer():回到此文件开头的偏移量(以字节为单位),在该位置发生下一个读取或写入操作
public void seek(long pos):设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。偏移量的设置可能会超出文件末尾。偏移量的设置超出
文件末尾不会改变文件的长度。 只有在偏移量的设置超出文件末尾的情况下对文件进行写入才会更改其长度
public long length():返回此文件的长度
public int skipBytes(int n):尝试跳过输入的 n 个字节以丢弃跳过的字节
标签:
原文地址:http://www.cnblogs.com/Jtianlin/p/4188976.html