标签:

今天内容
1.xml介绍
2.xml约束
3.xml解析
以上内容可以看懂,理解
4.贪吃蛇(补充)
------------------------------------------------
1.xml
xml:可扩展的标记语言.
xml作用:用于存储与传输数据.
xml与html区别
? XML 不是 HTML 的替代。-----xml对应xlst 相当于css于html
? XML 和 HTML 为不同的目的而设计:
? XML 被设计为传输和存储数据,其焦点是数据的内容。
? HTML 被设计用来显示数据,其焦点是数据的外观。
? HTML 旨在显示信息,而 XML 旨在传输信息。
xml它的标记没有预定义
2.关于xml书写规范.它的组成部分
对于一个标准的xml它由以下几部分组成
文档声明
元素
属性
注释
CDATA区 、特殊字符
处理指令(processing instruction)
1.文档声明
作用:用于声明当前是一个xml文档.
写法:<?xml version="1.0" encoding="utf-8"?>
以上就是一个文档声明,它的作用是用来通知当前是一个xml文档.
version是一个属性 注意:在xml中它的语法要求比较严格 所有的属性必须使用引号引起。
对于version的值 它只能取1.0
encoding:它代表的是当前xml文档中的信息的编码. 常用的值有 gbk iso8859-1 gb18030 bg2312 utf-8
standalone:它的作用是描述当前文档是否是一个独立文档。 这个属性我们一般很少使用.
xml文档也可以被浏览器直接解析.
关于文档声明的注意事项:
1.文档本身编码要与encoding的编码一样.
2.所有的属性要使用引号引起.
3.关于全角空格问题.
2.元素--就是指我们的xml中的标签.
1.xml中的元素(也就是标签)必须有结束.(可以自关闭)
2.xml中的标签可以嵌套,但是不能交叉嵌套。
3.一个标准的xml,有且只有一个根元素.*********************************
4.在xml中回车换行都做为元素存在.
关于元素的命名规范
区分大小写,例如,<P>和<p>是两个不同的标记。
不能以数字或"_" (下划线)开头。
不能以xml(或XML、或Xml 等)开头。
不能包含空格。
名称中间不能包含冒号(:)。 --- Schema 它的名称中使用:进行特殊定义.
-----------------------------
3.属性
1.属性值必须使用单引呈或双引号引起。
2.尽量使用子元素来描述信息,不使用属性.
4.注释
<!--
-->
与html一样.
5.CDATA 区域.
CDATA区域中的内容会按原样显示,也就是说,不会被浏览器解析.
写法:<![CDATA[
内容
]]>
在什么时候使用:我们在文档中一些信息不需要浏览器解析,直接输出就可以将信息放置在CDATA区域。
如果在文档中,只是有一些比较少的内容需要原样输出也可以使用专义字符。
6.指令(PI)
<?xml-stylesheet type="text/css" href="1.css"?>
xml总结:
所有 XML 元素都须有关闭标签
XML 标签对大小写敏感
XML 必须正确地嵌套顺序
XML 文档必须有根元素
XML 的属性值须加引号
特殊字符必须转义
XML 中的空格会被保留
-----------------------------------------------------------------
xml约束
约束:xml文档中可以写不可以写什么.
xml约束有两种
DTD------struts2框架,它就使用DTD做为约束.
SCHEMA-----后面 hibernate,spring中使用schema做为约束.
DTD简单--比较老.
SCHEMA---比较复杂 现在开发中一般都使用SCHEMA来对xml进行约束.
DTD
快速入门:
1.dtd约束的文件,后缀名是dtd。
2.使用DOCTYPE导入DTD
问题:怎样可以判断当前的dtd对xml文件进行约束,并且约束成功.
1.在开发,我们可以直接使用IDE进行约束检测。
2.可以直接使用js对xml文档它是否遵循dtd约束进行检查。
------------------------------------------
1.dtd与xml关联的三种方式.
1.内部dtd
就是在xml文件中直接写入了dtd约束.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!DOCTYPE 书架 [
<!ELEMENT 书架 (书+)>
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
]>
<书架>
<书>
<书名>Java就业培训教程</书名>
<作者>张孝祥</作者>
<售价>39.00元</售价>
</书>
...
</书架>
2.外部dtd
dtd文件是一个单独文件。
1.本地dtd
<!DOCTYPE 文档根结点 SYSTEM "DTD文件的URL">
2.网络上的dtd
<!DOCTYPE 文档根结点 PUBLIC "DTD名称" "DTD文件的URL">
2.学习dtd语法
1.元素
怎样声明元素:
<!ELEMENT 元素的名称 元素的内容类型>
<!ELEMENT books (book+)> 说明books下的book可以出现一次或多次。
元素的内容类型
1.PCDATA: 文本信息
2.EMPTY:空
3.ANY: 可以是文本也可以是子元素.
关于元素书写注意的地方.
1.<!ELEMENT books (book+)> 在books与(book+)之间一定要有空格.
2.对于(#PCDATA) 必须加括号 如果是EMPTY ANY不用加
2.属性
属性定义格式
<!ATTLIST 元素名称 属性名称 类型 约束>
属性类型:CDATA 枚举 ID
CDATA 代表是一个字符串。
枚举 (en1|en2|en3...) 代表属性值必须从其中选择一个.
ID 属性值是唯一的.
属性约束:
#REQUIRED 必须的.
#FIXED 绑定某个值.
#默认值
例子
<ATTLIST book lang CDATA #REQUIRED> lang属性必有.
<ATTLIST book lang (en|zh) #REQUIRED> lang属性必有,只能在zh与en之间取值.
<ATTLIST book lang CDATA #FIXED "en"> lang属性已经绑定值,值只能是en。
<ATTLIST book lang ID #REQUIRED> lang属性必须有,并且唯一.
<ATTLIST book lang CDATA "zh"> lang属性如果没有写,默认值为zh,写了就取写入的属性值.
3.实体
什么是实体:
就是在我们xml或dtd文件中有一些重复的信息,我们可以将其声明成实例,使用时,直接使用实体就可以。
实体分为两种
1.引用实体---在xml文档中使用
2.参数实体---在dtd文档中使用.
1.引用实体:
语法格式:
<!ENTITY 实体名称 “实体内容” >:直接转变成实体内容
引用方式:
&实体名称;
参数实体必须用于外部DTD文件中,不能用于内部DTD
2.参数实体
语法格式化:
<!ENTITY % 实体名称 “实体内容” >:直接转变成实体内容
引用方式
%实体名称;
----------------------------------------------------------------------------------
SCHEMA
它也是xml文件一种约束方式.
DTD与SCHEMA 区别?
1.dtd文档本身具有自己的语法规则。
SCHEMA本质就是一个xml文件,它遵行xml语法.
2.DTD文档对xml进行约束时,不能明确数据类型.
SCHEMA它可以精确的描述数据类型.
3.DTD文件的后缀是dtd。
SCHEMA文件的后缀是 XSD。
模型文档---xsd
实例文档---xml
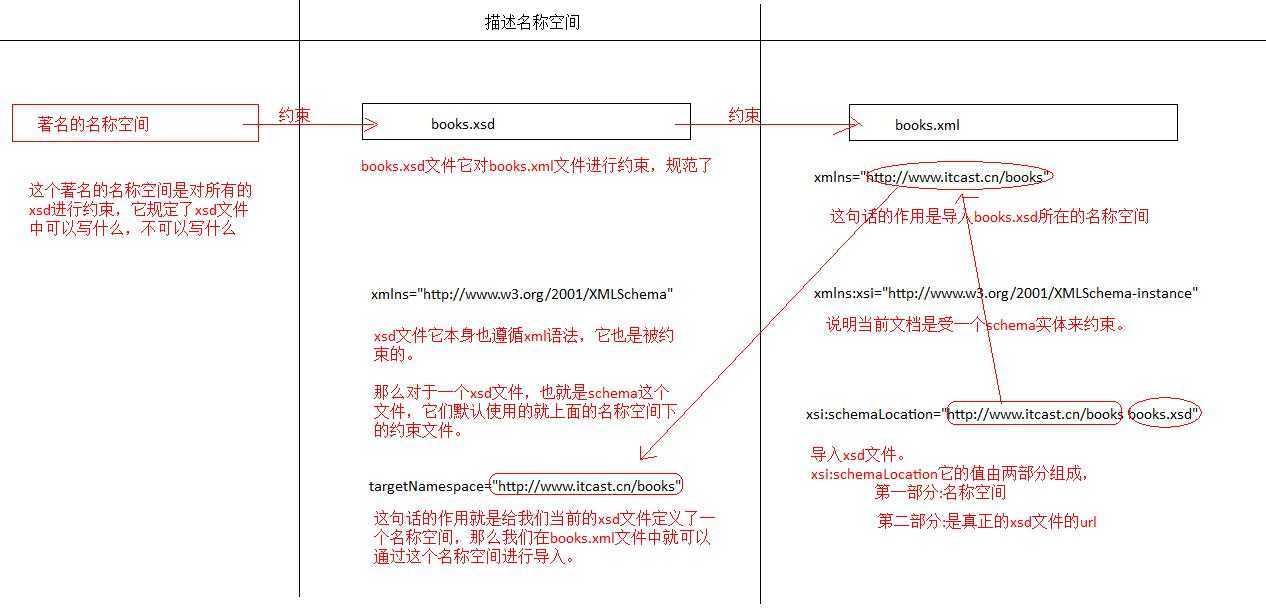
重要概念:名称空间
快速入门---目的:了解名称空间
1.做一个xml文件. books.xml
<books>
<book>
<name>java编程思想</name>
<price>99</price>
<author>tom</author>
</book>
</books>
2.定义一个schema约束文件.(后缀是xsd)
在ide中让其自动创建schema.
3.了解关于schema中定义元素与元素之间的关系问题;
对于一个可以包含元素的元素-----复杂类型
<element name="books">
<complexType><!-- 用于定义一个复杂元素 -->
<sequence> <!-- 规定顺序 -->
<element name="book">
<complexType>
<sequence>
<element name="name" type="string"/>
<element name="price" type="double"/>
<element name="author" type="string"/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
4.将我们的schema约束文件关联到xml文件中.
----------------------------------------------------------------------------
复习:
1.xml
组成部分:1.文档声明 2.元素 3.属性 4.注释 5.CDATA 6.指令。
2.约束
1.DTD
导入方式三种
1.内部
2.外部
1.本地 SYSTEM
2.网络 PUBLIC
2.DTD----元素 属性 实体
3.SCHEMA----名称空间
它是用于定义一个名字,给我们xsd文件起一个可以挂起的位置。这是一个虚拟的名称,
一般情况下,我们使用域名 (http;//www.itcast.cn),在xml文件中可以导入我们的名称空间,
并在主个空间下查找到我们的xsd文件。这样就可以对xml进行约束。
schema与dtd区别。
----------------------------------------------------------------
关于schema语法
1.所有的schema文档(xsd文件),它们的根元素全是schema
2.targetNamespace---用于定义名称空间
3.xmlns---用于引入一个名称空间
在xmlns:名称
这个名称是前缀,它可以帮助在一个xml文件中导入多个schema时,进行区分.
4.elementFormDefault 用于控制前缀在什么时候可以写.
unqualified: 根元素加前缀,子元素可以不加
qualified:根元素加前缀,子元素必须加。
关于在schema文件中定义属性.
定义元素element
maxOccurs属性可以定义子元素的个数.
--------------------------------------------------------
定义两个xsd文件,在一个xml文件中导入.
books.xml
books.xsd---将这个xsd中的price元素在price.xsd中声明.
price.xsd ---它里面声明一个price元素,要求 值必须在50-100之间。
-------------------------------------------------------------------------------------
关于解析xml文件.
javascript时,通过js对xml进行解析,生成document对象。
通过js解析是客户端操作。
在服务器端通过java代码对xml进行解析.
解析xml----就是对xml文件进行读写操作.(我们不是使用io)
关于java中怎样解析xml文件(方式)
解析xml有两种方式
1.dom
2.sax
3.pull
关于dom与sax解析的区别?
什么是dom解析:将整个xml文档加载到jvm内存中,生成一个dom树。我们可以很方便的对xml进行读写操作.
什么是sax解析:这种方式是基于事件驱动。读取一行,解析一行。所以sax解析只能进行读操作,不能进行写操作。
xml解析具体实现
Jaxp(sun)---sum标准 解析方式 dom sax解析 不需要导入任何jar包 jdk中就包含API
以下两种方式,如果要使用,需要导入第三方jar包
Jdom、
dom4j(重点)---在框架中应用比较多 struts2 hibernate spring
hibernate4以后,关于xml解析采用 xstream。(后面会讲)
----------------------------------------------------------------------------------------------
jaxp的解析:
JAXP 开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成
对于dom树,所有节点 Node Element Text Attr Document
1.dom解析.
对books.xml文件进行dom解析
步骤:
1.DocumentBuilderFactory---关于dom解析工厂,得到这个工厂就可以获取解析器.
2.DocumentBuilder ---解析器类,通过解析器类可以获取xml文件的Document对象.
3.Document代表整个文档,其实就是dom树,我们得到这个树就可以操作树中的任意一个节点.
得到Document对象后使用的API
1.getElementsByTagName(String name); 根据名称获取标签.
2.getTextContent(); 获取标签中的文本信息.
NodeList
1.getLength() 得到长度
2.Node item(int index) 得到第几项.
3.getChildNodes() 获取所有子节点.
4.getNodeName() getNodeType() getNodeValue();
问题:将整个文档中的所有内容都遍历出来,怎样做?
需要使用递归方式,怎样判断是否结束。 hasChildNodes()这个方法可以判断是否具有子元素。
如果有子元素,使用getChildNodes()去获取,
作用扩展题:完成对一个xml文件的遍历。
--------------------------------------------------------------------------------------
5.getAttribute() 获取属性
6.关于jaxp的create操作
创建Element-----document.createElement("name")
创建Attribute---
创建Text -------element.setTextContent("textvalue");
7.修改
8.删除
getParentNode() 获取父节点.
removeChild() 删除子节点. 注意要通过父节点来操作。
removeAttribute();---删除属性操作.
---------------------------------------------------------------------------------
2.sax解析(了解)
它只能读不能写。
它是基于事件驱动方式。
标签:
原文地址:http://www.cnblogs.com/spadd/p/4192617.html