标签:
开发环境: ubuntu14.04 + jdk1.7 + eclispe +nutch1.7
1:解压下好nutch1.7 src 源码(wget http://archive.apache.org/dist/nutch/1.7/apache-nutch-1.7-src.tar.gz)
2:新建一个java project 后 导入(我将nutch1.7 源码解压在/home/hadoop/nutch1.7-src)
2:编辑 conf/nutch-site.xml 文件添加如下
<property> <name>http.agent.name</name> <value>mynutch spider</value> </property>
3:在conf文件下的regex-urlfilter.txt 文件将+. 注释掉新增"+^http://(\.*)*" 如下
#+.
"+^http://(\.*)*"
4:运行抓取数据测试:org.apache.nutch.crawl.Crawl
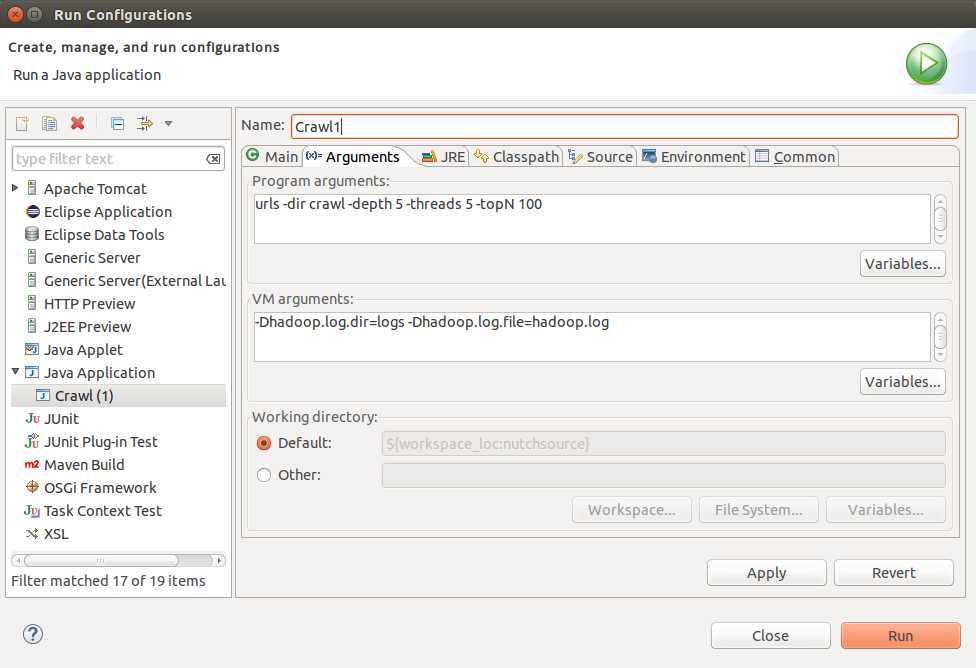
运行结果:
rootUrlDir = urls
threads = 5
depth = 5
solrUrl=null
topN = 100
Injector: starting at 2014-12-31 15:33:09
Injector: crawlDb: crawl/crawldb
Injector: urlDir: urls
Injector: Converting injected urls to crawl db entries
如果是在win7 下搭建环境可以参考这篇文章:http://www.cnblogs.com/xia520pi/p/3695617.html
标签:
原文地址:http://www.cnblogs.com/zhanggl/p/4167665.html