标签:
背景
上一篇文章总结了linear hard SVM,解法很直观,直接从SVM的定义出发,经过等价变换,转成QP问题求解。这一讲,从另一个角度描述hard SVM的解法,不那么直观,但是可以避免feature转换时的数据计算,这样就可以利用一些很高纬度(甚至是无限维度)的feature转换,得到一些更精细的解。
?
拉格朗日乘子式
首先,回顾一下SVM问题的定义,如下:
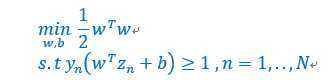
线性约束很烦,不方便优化,是否有一种方法可以将线性约束放到优化问题本身,这样就可以无拘无束的优化,而不用考虑线性约束了。拉格朗日大神提供了一种方法,可以达到这个目的,称之为拉格朗日乘子式(更通用的方法参考文章"简易解说拉格朗日对偶"),形式如下,
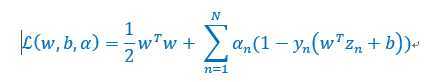
这个公式是不是很奇怪,无端的多处了N个变量,但是再看下面的变化,就知道这个拉格朗日乘子式的厉害了。
?
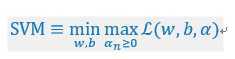
什么,SVM问题等于右边那个min max?没错,虽然初看感觉不科学,但是仔细分析,的确如此。首先,由于,令f(w,b) = ,
?
当f(w,b) > 0,在w,b固定的情况下,,max会将放大到;
当f(w,b)0,那么,那么。
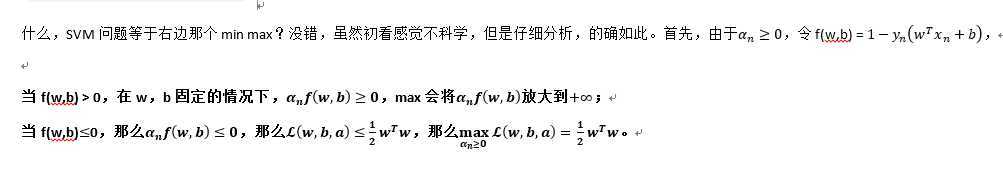
所以,综合两种情况,SVM问题与min max变换公式等价。是不是很奇妙,不得不佩服拉格朗日大神。
?
?
对偶变换
上面的问题中min max的形式不方便求解,不过可以通过一番变化,导出max min的形式,这样就可以从内到外,先计算里面的min,然后计算外面的max。这种变化叫对偶变化。
首先选任意一个固定的,并且,那么有
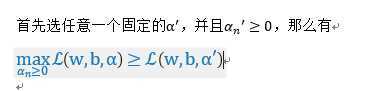
两边通过w,b取min,等式仍然成立,即
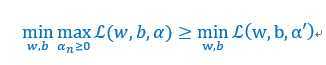
有多重选择,但是上面的不等式一致成立,所以在众多的选择一个最大,上面的等式变形为,

?
这样,min max就和max min建立了一定的联系,但是由于是"",称之为弱对偶(week duality)。""强对偶(strong duality)如何才能成立呢?需要满足下面的条件,

太桥了,SVM问题完全符合上述约束,所以是对偶,这样可以通过解右边max min的问题来得到最终解!
?
问题化简
经过上面的对偶变化,下面来一步一步的简化我们的原始问题,
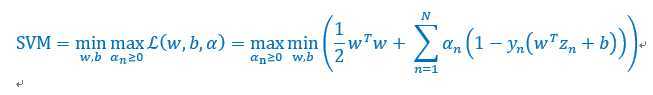
首先对b求偏导数,并且为0,有如下结果
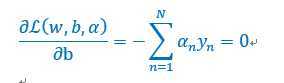
带入这个结果到上面的公司,化简
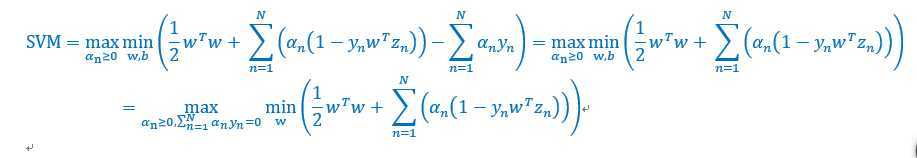
?
接下啦,对w求偏导数,
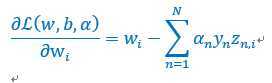
?
?
所以,向量w为
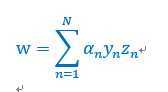
将w带入,并且去掉min,得到如下
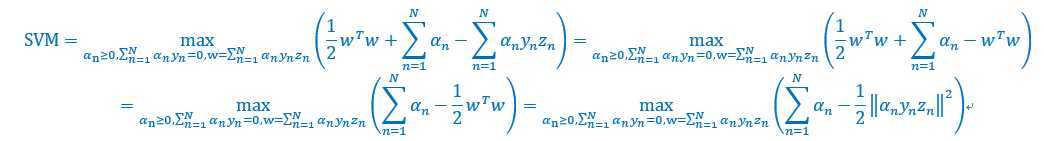
执行到这里,现在目标函数只与有关,形式满足QP,可以轻易得到,也就是得到w。但是在计算过程中,需要计算一个中间矩阵Q,维度为N*N,这个是主要计算开销。上一讲无需计算这个Q,因为Q的形式十分简单。
?
问题来了,如何求解b,上面的目标函数中,在之前的简化过程中消去了b,已经与b无关。
?
计算b
现在只剩下最后一个问题,如何计算b? 在之前的简化过程中消去了b,上面的QP解与无关。
?
KKT条件帮助我们解决这个问题。如果原始问题和对偶问题都有最优解,且解相同,那么会满足KKT条件。这也是一个充分必要条件,其中很重要的一点是complementary slackness(互补松弛性),该条件有下面等式成立,
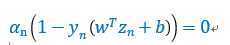
由于(对偶条件),且(原始条件),那么两者有一个不为0时,另外一个必然为0。所以,只要找到一个,就可以利用这个性质计算出b,计算方法如下:
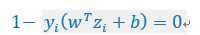
两边乘以,
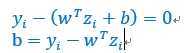
理论来说,只需要一个点就可以,但是实际上由于计算有误差,可能会计算所有的b,然后求平均。并且这些可以计算出b的点,就是支持向量,因为他们满足了原始问题中支撑向量的定义。但是,并不是所有的支撑向量,都有对应的。一般的,我们只用的向量称为支撑向量,而那些满足支撑向量定义的向量称之为候选支撑向量,有如下关系

并且,为了简化计算,在计算w的时候,的计算均可以省去,如下
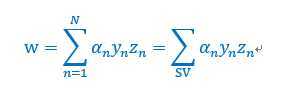
w的哲学
通过上面的计算,其实最后w是()的线性组合。同样的,PLA中w也是()的线性组合。只是SVM利用支撑向量求解这个线性组合,PLA使用错误的向量。同理,逻辑回归,线性回归也有类似规律,称这种现象为"w represented by data"。

总结
本节使用对偶问题,从另外一个侧面求解了SVM,并且数据学推导相对复杂,计算量也增加了许多,因为需要求解一个N*N维度的矩阵Q。但是,为什么要做这些事情呢,hard linear SVM要简单许多复?其实换成对偶问题是为了利用kernel做铺垫,改kernel可以将维度转化的计算省略,从而可以计算很复杂的转化,这一点下一节讨论。
?
?
PS:划线部分段落是由于包含公式,无法正常显示,所以采用图片方式在下方显示。
标签:
原文地址:http://www.cnblogs.com/bourneli/p/4199990.html