标签:
在彻底了解mean shift之前,我们需要解决三个问题:
第一个问题:无参数密度估计
无参数密度估计,它对数据分布规律没有附加任何假设,而是直接从数据样本本身出发研究数据分布特征,对先验知识要求少,完全依靠训练数据进行估计,而且能够处理任意的概率分布。
eg. 直方图法,最近邻域法,核密度估计法。
而有参数密度估计有:高斯统计模型
举个例子:
有N个数据点,它们的坐标分布如下图所示,如何求出这个区域中,哪个位置的样本分布密度最大,换言之,如果来了第N+1个样本点,它最大的可能出现位置在哪里。

第二个问题:Kernel density estimation
给定![]() 维空间
维空间![]() 中的样本集合
中的样本集合![]() ,则点
,则点![]() 关于核函数
关于核函数![]() 和带宽矩阵
和带宽矩阵![]() 的核函数密度估计表示为:
的核函数密度估计表示为:
![]()
其中
![]()
由于![]() ,可将密度估计写成关于核函数的轮廓函数形式:
,可将密度估计写成关于核函数的轮廓函数形式:
![]()
由上面的公式可以看出,其实核函数密度估计最后可以看做成为一种权值函数,其作用是将每个样本点按与点x的距离远近进行加权,距离x点近的样本点概率密度估计影响大,赋予权值也越大;反之权值越小。
第三个问题:Mean shift 向量
从上轮可以得出对数据的核函数密度估计,现在我们要对这个概率密度分布来分析数据集合中密度最大的数据分布位置,首先对Kernel密度函数求导,
![]()

令导数=0,可以得到

则该x的位置就是概率密度最大的点位置。
我们令![]() 表示为Mean shift 向量,则有
表示为Mean shift 向量,则有

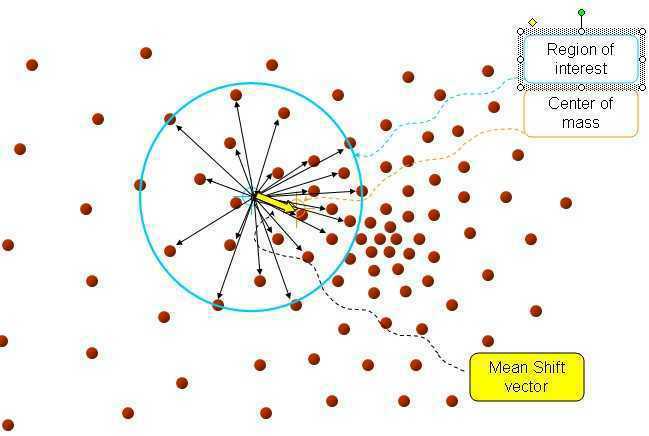
因此,Mean shift 向量的平均偏移量(即梯度方向)会指向样本点最密的方向。Mean shift会转移到样本点相对变化最多的地方。而且离x越近的样本点对估计x周围的统计特性越重要,核函数的概念引入,可以理解为其实质就是每个样本点对x的权值贡献。可以打个比喻,想象一下几十匹马同时拉一辆车的恢弘场面(当然这辆车得够稳定,不会烂~),每匹马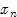 都往自己的方向
都往自己的方向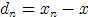 拉,不过,距离x越近的马,其力量
拉,不过,距离x越近的马,其力量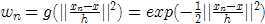 越大,最后的结果方向当然是朝着合力的方向移动,即如下图的黄色箭头方向。
越大,最后的结果方向当然是朝着合力的方向移动,即如下图的黄色箭头方向。
Application I. Image Segmentation:
本质上,mean shift解决问题都是基于转化为密度估计问题。对于图像应用,spatial信息有2维,range空间有p维。
图像分割中使用的多元核:
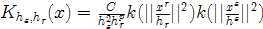
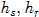 分别为坐标空间核和颜色空间核的带宽(bandwidth)。Discontinuity Preserving Smoothing滤波后的结果如下:
分别为坐标空间核和颜色空间核的带宽(bandwidth)。Discontinuity Preserving Smoothing滤波后的结果如下:



图像分割就是在滤波后对相同像素值的点进行聚类,分成M个区域。
Application II. Tracking
基于Mean shift的目标跟踪算法通过分别计算目标区域和候选区域内像素的特征值概率,得到关于目标模型和候选模型的描述,然后利用相似函数度量初始帧目标模型和当前帧候选区域的相似性,选择相似函数最大的候选模型并得到关于目标模型的Mean shift向量,这个向量正是目标区域由初始位置向正确位置移动的位移向量。由于Mean shift算法的快速收敛性,通过不断迭代计算Mean shift向量,算法最后将可以收敛到目标的真实位置,从而达到Tracking目的。


Mean shift 跟踪结果
标签:
原文地址:http://www.cnblogs.com/hcicoder/p/4200873.html