标签:
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法
RabbitMQ是流行的开源消息队列系统,用erlang语言开发
----------------------------------------------------------------------------------------------------
RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡。
Rabbit模式大概分为以下三种:单一模式、普通模式、镜像模式
单一模式:最简单的情况,非集群模式。
没什么好说的。
普通模式:默认的集群模式。
对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。
所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。
如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,然后就没有然后了……
镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
所以在对可靠性要求较高的场合中适用(后面会详细介绍这种模式,目前我们搭建的环境属于该模式)
了解集群中的基本概念:
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如前文所述,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
一个rabbitmq集 群中可以共享 user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的,一个例外是,那些当前只属于创建它的节点的消息队列,尽管它们可见且可被所有节点读取。rabbitmq节点可以动态的加入到集群中,一个节点它可以加入到集群中,也可以从集群环集群会进行一个基本的负载均衡。
集群中有两种节点:
1 内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk)
2 磁盘节点:保存状态到内存和磁盘。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。集群中,只需要一个磁盘节点来保存状态 就足够了
如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
思路:
那么具体如何实现RabbitMQ高可用,我们先搭建一个普通集群模式,在这个模式基础上再配置镜像模式实现高可用,Rabbit集群前增加一个反向代理,生产者、消费者通过反向代理访问RabbitMQ集群。
架构图如下:图片来自http://www.nsbeta.info
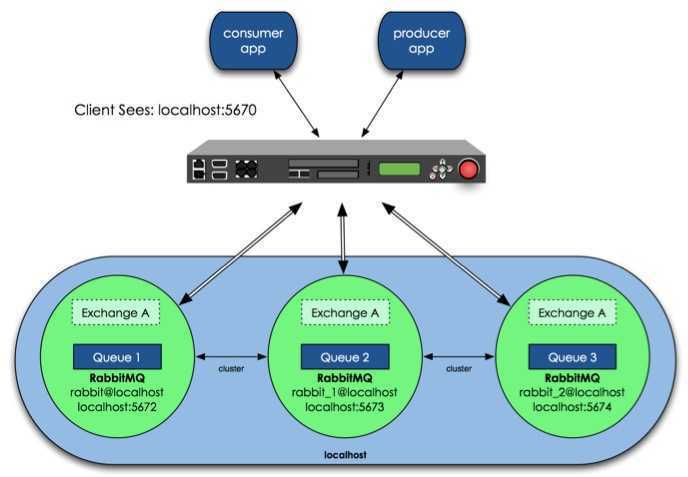
设计架构可以如下:在一个集群里,有4台机器,其中1台使用磁盘模式,另2台使用内存模式。2台内存模式的节点,无疑速度更快,因此客户端(consumer、producer)连接访问它们。而磁盘模式的节点,由于磁盘IO相对较慢,因此仅作数据备份使用,另外一台作为反向代理。
四台服务器hostname分别为:queue 、panyuntao1、panyuntao2、panyuntao3(ip:172.16.3.110)
配置RabbitMQ集群非常简单,只需要几个命令,配置步骤如下:
step1:queue、panyuntao1、panyuntao2做为RabbitMQ集群节点,分别安装RabbitMq-Server ,安装后分别启动RabbitMq-server
启动命令 # Rabbit-Server start ,安装过程及启动命令参见:http://www.cnblogs.com/wjoyxt/p/4196001.html
step2:在安装好的三台节点服务器中,分别修改/etc/hosts文件,指定queue、panyuntao1、panyuntao2的hosts,如:
172.16.3.32 queue
172.16.3.107 panyuntao1
172.16.3.108 panyuntao2
还有hostname文件也要正确,分别是queue、panyuntao1、panyuntao2,如果修改hostname建议安装rabbitmq前修改。
请注意RabbitMQ集群节点必须在同一个网段里,如果是跨广域网效果就差。
step3:设置每个节点Cookie
Rabbitmq的集群是依赖于erlang的集群来工作的,所以必须先构建起erlang的集群环境。Erlang的集群中各节点是通过一个magic cookie来实现的,这个cookie存放在 /var/lib/rabbitmq/.erlang.cookie 中,文件是400的权限。所以必须保证各节点cookie保持一致,否则节点之间就无法通信。-r--------. 1 rabbitmq rabbitmq 20 3月 5 00:00 /var/lib/rabbitmq/.erlang.cookie将其中一台节点上的.erlang.cookie值复制下来保存到其他节点上。或者使用scp的方法也可,但是要注意文件的权限和属主属组。我们这里将queue中的cookie 复制到 panyuntao1、panyuntao2中,先修改下panyuntao1、panyuntao2中的.erlang.cookie权限#chmod 777 /var/lib/rabbitmq/.erlang.cookie将queue的/var/lib/rabbitmq/.erlang.cookie这个文件,拷贝到panyuntao1、panyuntao2的同一位置(反过来亦可),该文件是集群节点进行通信的验证密钥,所有节点必须一致。拷完后重启下RabbitMQ。复制好后别忘记还原.erlang.cookie的权限,否则可能会遇到错误#chmod 400 /var/lib/rabbitmq/.erlang.cookie设置好cookie后先将三个节点的rabbitmq重启# rabbitmqctl stop# rabbitmq-server start
[{nodes,[{disc,[rabbit@queue]}]}, {running_nodes,[rabbit@queue]}, {partitions,[]}] ...done.
[{nodes,[{disc,[rabbit@panyuntao1]}]},
{running_nodes,[rabbit@panyuntao1]},
{partitions,[]}] ...done.
[{nodes,[{disc,[rabbit@panyuntao2]}]},
{running_nodes,[rabbit@panyuntao2]},
{partitions,[]}] ...done.
panyuntao1# rabbitmqctl join_cluster --ram rabbit@queue
panyuntao1# rabbitmqctl start_app
panyuntao2# rabbitmqctl stop_apppanyuntao2# rabbitmqctl join_cluster --ram rabbit@queue (上方已经将panyuntao1与queue连接,也可以直接将panyuntao2与panyuntao1连接,同样而已加入集群中)panyuntao2# rabbitmqctl start_app
只要在节点列表里包含了自己,它就成为一个磁盘节点。在RabbitMQ集群里,必须至少有一个磁盘节点存在。
step5:在queue、panyuntao1、panyuntao2上,运行cluster_status命令查看集群状态:
[root@queue ~]# rabbitmqctl cluster_statusCluster status of node rabbit@queue ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@panyuntao2,rabbit@panyuntao1]}]},{running_nodes,[rabbit@panyuntao2,rabbit@panyuntao1,rabbit@queue]},{partitions,[]}]...done.[root@panyuntao1 rabbitmq]# rabbitmqctl cluster_statusCluster status of node rabbit@panyuntao1 ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@panyuntao2,rabbit@panyuntao1]}]},{running_nodes,[rabbit@panyuntao2,rabbit@queue,rabbit@panyuntao1]},{partitions,[]}]...done.[root@panyuntao2 rabbitmq]# rabbitmqctl cluster_statusCluster status of node rabbit@panyuntao2 ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@panyuntao2,rabbit@panyuntao1]}]},{running_nodes,[rabbit@panyuntao1,rabbit@queue,rabbit@panyuntao2]},{partitions,[]}]...done.这时我们可以看到每个节点的集群信息,分别有两个内存节点一个磁盘节点
root@panyuntao2 :~# rabbitmqctl list_queues -p hrsystem
Listing queues …
test_queue 10000
…done.root@panyuntao1 :~# rabbitmqctl list_queues -p hrsystemListing queues …
test_queue 10000
…done.root@queue:~# rabbitmqctl list_queues -p hrsystemListing queues …
test_queue 10000
…done.-p参数为vhost名称
1. storage space: If every cluster node had a full copy of every queue, adding nodes wouldn’t give you more storage capacity. For example, if one node could store 1GB of messages, adding two more nodes would simply give you two more copies of the same 1GB of messages.
2. performance: Publishing messages would require replicating those messages to every cluster node. For durable messages that would require triggering disk activity on all nodes for every message. Your network and disk load would increase every time you added a node, keeping the performance of the cluster the same (or possibly worse).
当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡。
上面配置RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制,虽然该模式解决一部分节点压力,但队列节点宕机直接导致该队列无法使用,只能等待重启,所以要想在队列节点宕机或故障也能正常使用,就要复制队列内容到集群里的每个节点,需要创建镜像队列。我们看看如何镜像模式来解决复制的问题,从而提高可用性。镜像队模式是基于普通的集群模式的,所以你还是得先配置普通集群,然后才能设置镜像队列
关于负载均衡器,商业的比如F5的BIG-IP,Radware的AppDirector,是硬件架构的产品,可以实现很高的处理能力。但这些产品昂贵的价格会让人止步,所以我们还有软件负载均衡方案。互联网公司常用的软件LB一般有LVS、HAProxy、Nginx等。LVS是一个内核层的产品,主要在第四层负责数据包转发,使用较复杂。HAProxy和Nginx是应用层的产品,但Nginx主要用于处理HTTP,所以这里选择HAProxy作为RabbitMQ前端的LB。
HAProxy的安装使用非常简单,在Centos下直接yum install haproxy,然后更改/etc/haproxy/haproxy.cfg 文件即可,文件内容大概如下:
#---------------------------------------------------------------------defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000listen rabbitmq_cluster 0.0.0.0:5672mode tcpbalance roundrobinserver rqslave1 172.16.3.107:5672 check inter 2000 rise 2 fall 3server rqslave2 172.16.3.108:5672 check inter 2000 rise 2 fall 3# server rqmaster 172.16.3.32:5672 check inter 2000 rise 2 fall 3#---------------------------------------------------------------------
在cluster中任意节点启用策略,策略会自动同步到集群节点 # rabbitmqctl set_policy -p hrsystem ha-allqueue"^" ‘{"ha-mode":"all"}‘这行命令在vhost名称为hrsystem创建了一个策略,策略名称为ha-allqueue,策略模式为 all 即复制到所有节点,包含新增节点,
策略正则表达式为 “^” 表示所有匹配所有队列名称。
例如rabbitmqctl set_policy -p hrsystem ha-allqueue "^message" ‘{"ha-mode":"all"}‘
注意:"^message" 这个规则要根据自己修改,这个是指同步"message"开头的队列名称,我们配置时使用的应用于所有队列,所以表达式为"^"官方set_policy说明参见
| ha-mode | ha-params | Result |
|---|---|---|
| all | (absent) | Queue is mirrored across all nodes in the cluster. When a new node is added to the cluster, the queue will be mirrored to that node. |
| exactly | count | Queue is mirrored to count nodes in the cluster. If there are less than count nodes in the cluster, the queue is mirrored to all nodes. If there are more than countnodes in the cluster, and a node containing a mirror goes down, then a new mirror will not be created on another node. (This is to prevent queues migrating across a cluster as it is brought down.) |
| nodes | node names | Queue is mirrored to the nodes listed in node names. If any of those node names are not a part of the cluster, this does not constitute an error. If none of the nodes in the list are online at the time when the queue is declared then the queue will be created on the node that the declaring client is connected to. |

标签:
原文地址:http://www.cnblogs.com/wjoyxt/p/4201145.html