标签:
关于误用、滥用MDX和SSAS的场合,这里引用一篇老外的文章(http://www.bp-msbi.com/2010/03/when-not-to-write-mdx-and-when-not-to/),重点请看下最后一节(2. No Aggregations)里的内容,考虑到看官网速可能不太给力,引用此部分内容如下:
2. No Aggregations Another way SSAS gets misused is when a lot of textual data gets stored in a large number of big dimensions, and those get linked in a “fact table”. I have previously worked on a solution where there were no measure columns in the fact table at all and the cube was used to retrieve information about dimension members of the largest dimension called “Member”, containing 4-5 million customers. The rest were dimensions like “Sign Up Date”, “Date Suspended”, “Country of Birth”, “Age Band”, etc. In the end, the main report consisted of the information about the members. No data was aggregated apart from a simple count. The entire OLAP solution could have been replaced by a SQL query with a WHERE clause and an index.
当查询结果集里的维度层级过多时mdx的性能是不如sql的,例如上文作者举的例子,会员维度里的诸如“注册日期”、“国籍”、“年龄”、“住址”、“会员卡号”等属性在oltp数据结构里可能都存在于一张会员表,现在需要做一张会员信息明细的报表,如果是对二维存储的OLTP单表进行sql查询,性能是要远远高于常规MOLAP MDX查询的,你可以试着使用excel pivottable访问ssas,把多个维度属性逐个拖放在行上,会发现维度的层级越多,执行mdx查询的效率会越低,因为默认的pivottable生成的mdx脚本是要对每层维度做聚合查询(即使是PowerPivot支持的Flattened Pivot性能也是糟糕的),pivottable擅长的是做多维数据聚合分析,而对这种重复性不高的二维个人信息维度做聚合查询通常来说是没有多大意义的,所以作者建议这种场合应该使用sql去代替mdx,那么似乎就没什么好讨论的了,而我接下来所描述的特殊应用场景正是使用mdx来解决此类问题。
应用场景是这样的,用户希望能在excel一站式平台既能做多维分析又能做二维分析,多维分析不用多说了,直接访问ssas即可,强大的pivottable几乎能解决所有分析需求(设计合理的话),但是二维分析就遇到了上文提到的麻烦,用户想要在pivottable里做一些filter筛选,然后调出筛选到的会员明细,包括会员卡号、年龄、住址等等信息,如果把这些信息都做成常规维度,在pivottable里的行区域展现,效率是非常低的,测试下来看经常会造成excel崩溃,原因上文已解释。那么看起来只能用sql去解决问题了,使用excel querytable访问一个存储过程,返回会员明细信息结果集到excel里,刁钻的用户又来问题了,这样的话很难解决以下几个问题:
1. 终端用户需要可视化操作想要展现出来的会员信息,例如这次只想看会员卡号,下次又想看住址和注册日期,sql实现的报表很难做到这一点。
2. 终端用户需要可视化配置Filters逻辑,用来降低结果集的行数,Filter条件是未知的。(都是被pivottable惯出来的毛病)
3. 会增加权限管理的复杂程度,ssas里的权限管理是和windows user挂钩的,现在需要去db里做查询,需要打通ssas和db的鉴权逻辑,要么把鉴权信息都配置在db里,要么分别为ssas和db实现鉴权,怎么说都不是那么容易实现
说明一点,以上三个问题是我根据用户反馈的信息总结的,用户不懂技术,又被self-service BI这种理念冲昏了头脑,经常会提出些令人抓狂的需求
言归正传,刚拿到这个需求,我首先想到的是pivottable在导入数据之前的一步,是可以选择使用Table, PivotTable还是PivotChart展现的,结果如下图,发现在访问ssas时是不可以选择展现为Table
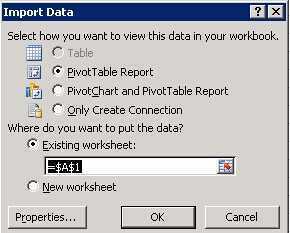
本来想利用PivotTable Field List的可视化操作使数据展现到二维Table里,后来想想也是醉了,既然叫PivotTable Field List,自然不是给Table使用的了,此路不通
还是用vsto插件解决吧,步骤如下
1. 首先用户在pivottable里定义好各种Filters(支持多选),然后点击插件上的功能按钮【Tabular Report】,下图示例是917位法国爷们。
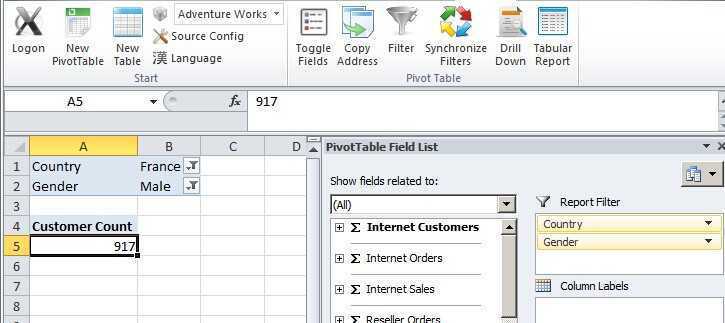
这里点击【Tabular Report】所做的事情是获取到当前pivottable的mdx脚本,传给弹出的一个winform窗体,winform首次打开时要去ssas服务器上获取整个cube的Field List(脚本如下),就像PivotTable Field List一样以树状菜单展现在winform上。
SELECT ‘[‘+[MEASUREGROUP_NAME]+‘]‘ as TableName, [MEASURE_UNIQUE_NAME] as FieldName FROM $SYSTEM.MDSCHEMA_MEASURES WHERE [CUBE_NAME]=‘@Cube‘ AND [MEASURE_IS_VISIBLE] ORDER BY [MEASUREGROUP_NAME] SELECT [DIMENSION_UNIQUE_NAME] AS TableName, [DIMENSION_UNIQUE_NAME]+‘.[‘+[LEVEL_NAME]+‘]‘ AS FieldName FROM $SYSTEM.MDSCHEMA_LEVELS WHERE [CUBE_NAME]=‘@Cube‘ AND [LEVEL_NUMBER]>0 ORDER BY [DIMENSION_UNIQUE_NAME]
补充一点,以上脚本是可以设置是否显示那些隐藏的维度或事实字段,这个很有用,比如说会员住址这种维度不希望显示给PivotTable使用,但又希望做【Tabular Report】时使用
2. 在winform上选取需要展现到QueryTable里的维度字段,然后确认。
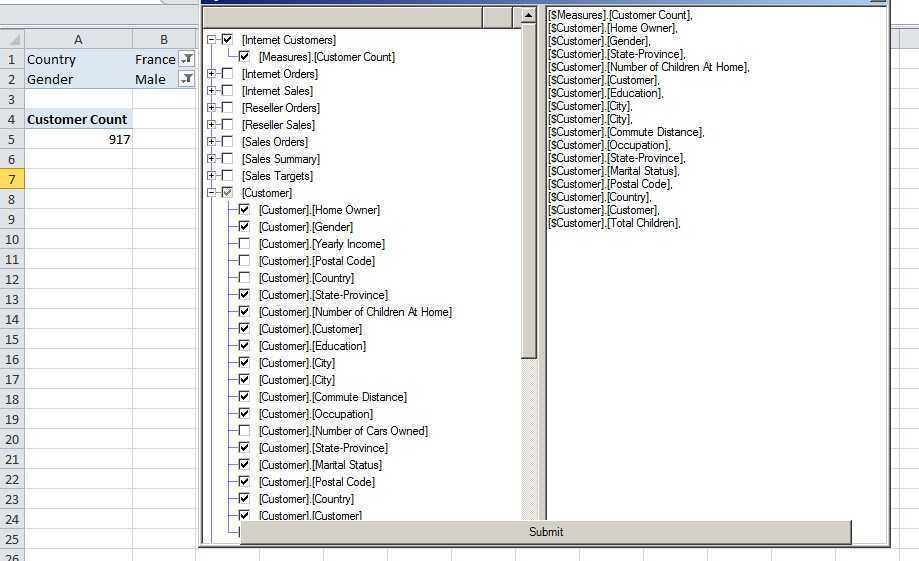
此时做的事情是把前面传进来的mdx脚本和在winform上选取的字段一起拼成一段mdx脚本,主要用到的是DrillThrough函数,拼出的脚本如下:
DRILLTHROUGH MAXROWS /*B1*/1000/*B1*/ SELECT FROM [Adventure Works] WHERE ([Customer].[Country].&[France],[Customer].[Gender].&[M],[Measures].[Customer Count]) RETURN [$Measures].[Customer Count], [$Customer].[Home Owner], [$Customer].[Gender], [$Customer].[State-Province], [$Customer].[Number of Children At Home], [$Customer].[Customer], [$Customer].[Education], [$Customer].[City], [$Customer].[City], [$Customer].[Commute Distance], [$Customer].[Occupation], [$Customer].[State-Province], [$Customer].[Marital Status], [$Customer].[Postal Code], [$Customer].[Country], [$Customer].[Customer], [$Customer].[Total Children]
然后会自动新建一个sheet页面,并创建一个QueryTable,使其访问ssas执行上面的脚本返回结果集如下:
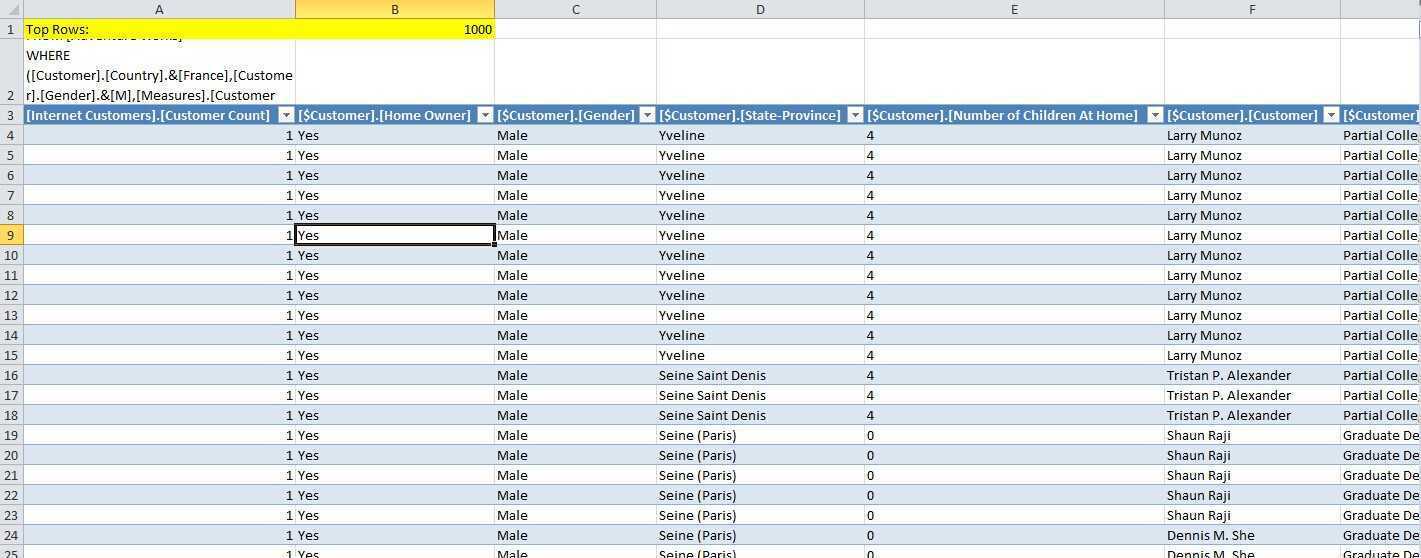
至此任务结束,完美解决了上文提到的三个问题,就用户体验而言整个流程很清晰,操作也很简便,而且不需要终端用户有任何代码能力
如何用Excel QueryTable以二维表的方式展现MOLAP里的多维数据
标签:
原文地址:http://www.cnblogs.com/xpivot/p/4201825.html