标签:
1.爬虫的介绍

图1-1 爬虫(spider)
网络爬虫(web spider)是一个自动的通过网络抓取互联网上的网页的程序,在当今互联网中得到越来越广泛的使用。这种技术一般用来爬取网页中链接,资源等,当然,更为高级的技术是把网页中的相关数据保存下来,成为搜索引擎,例如著名的google和百度。常见的爬虫应用还有像一淘这样的比价网站,电影推荐网站等。
为了让大家进一步感受到爬虫的魅力,笔者编写了一个爬取淘宝和京东数据的比价网站(http://jiafei.org:8888/),如图1-2所示。由于淘宝和京东的搜索结果页面中有部分内容引(如价格)是通过ajax动态获得的,再用javascript把内容写入到相应的标签中的,当搜索Iphone 5s时,后台爬虫利用webkit生成去最终的dom树,爬取有用的数据,经过简单的处理后返回相应的结果。

图1-2 一个简单的比较网站
2.为何需要爬虫
爬虫对于扫描器来说至关重要,站在整个扫描器的最前线(如图2-1所示)。在一个专业扫描器中,一般首先会由爬虫爬取指定的页面,接着把爬到的url传递给调度server,最后由调度server分发需要扫描的url给扫描agent来完成整个扫描过程。

图2-1 扫描器的组成
2.爬虫的架构与分析
Web安全对于互联网公司来说至关重要,为了让公司的扫描器与业界的扫描器看齐,server安全组自研了一款功能强大的爬虫——SuperSpider,主要用来为漏洞扫描提供丰富的urls。SuperSpider的架构如图3-1所示,首先由下载器模块下载指定的页面,分析页面模块分析完成后一方面把需要的数据传递给存储模块,另一方面将爬取的urls传递给去重模块,去重后放到url队列中,最后由调度器安排次序传递url给下载器下载新的页面。接下来详细讲讲分析页面,调度器和去重这3个模块。
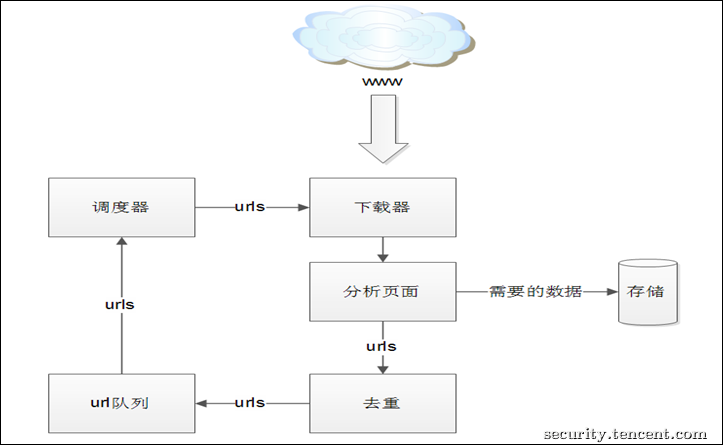
图3-1 爬虫的架构
3.1分析页面
简单的来说, 爬虫主要作用就是用来分析页面。
难点:因为现在是web2.0时代,绝大部分网页都会使用javascript处理页面,而且很多网页内容都是通过Ajax技术加载的。因此,只是简单地解析HTML文件会远远不够。
解决:如何做到这点?编写一个基于webkit的爬虫SuperSpider。下面将详细说明SuperSpider所具有的5个功能强大的爬取能力。
a. 静态页面链接分析
简单点来说,就是分析html文档,例如下图的一个<a>标签的超链接,SuperSpider会识别出href中的值为一个超链接,提取其值html_link.php?id=1。

b. javascript动态解析
下图为一段javascript代码,该代码的目的是在id为hi的a标签中提交属性href。

SuperSpider利用webkit内核执行以上javascript代码生成出以下html代码,再通过静态页面链接分析获取js_link.php?id=1&msg=abc这个url。

c. 自动分析表单
SuperSpider会自动识别出action中的值为所提交的地址,提取input标签中的name和value作为参数,最终生成出 post_link.php?id=1&msg=abc 这个url。

d. 自动交互
自动交换就是说要模仿出人的行为,例如点击鼠标,按下回车键等,下图就是一个需要点击鼠标的例子。

SuperSpider会自动识别出onclick是一个交换行为,从而执行里面的js代码生成出以下html,从而爬到了 click_link.php?id=1 这个url。
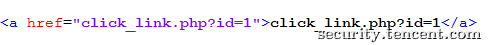
e. hook所有的网络请求
这是一个ajax请求,有别于以上4种基于dom树解析的分析技术,要捉到其请求的url只能通过hook请求,而webkit文档中并没有提到hook 网络请求的方法。于是通过修改webkit代码hook住每一个由webkit发送出去的请求,从而拿到了 ajax_link.php?id=1&t=1这个url。

3.2调度器
SuperSpider的调度器使用广度优先搜索策略,具体的逻辑如下图所示。首先,从入口页面1.html中爬到了2.html, 3.html和4.html,依次把它们放到url队列中。接着取出2.html,把爬到的5.html和6.html放到url队列中,随后便开始爬取3.html,依广度次序进行。
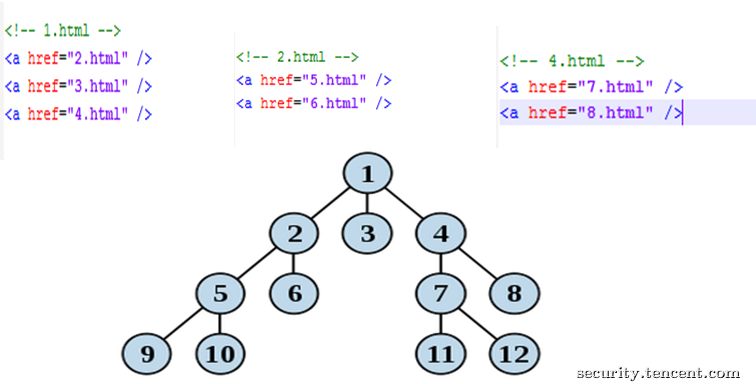
图3-2-1 爬虫调度的广度优先搜索策略
3.3去重
为了扫描的质量和效率,需要进行去重。例如大部分网站中日期作为其url的组成部分,尤其是门户网站。SuperSpider使用将数字替换成d+的算法对url进行去重。例如,
1.http://video.sina.com.cn/ent/s/h/2010-01-10/163961994.shtml?a=1&b=10
2.http://video.sina.com.cn/ent/s/h/2009-12-10/16334456.shtml?a=12&b=67
对数字进行模式处理为:
http://video.sina.com.cn/ent/s/h/d+-d+-d+/d+.shtml?a=d+&b=d+
如果链接1已经爬取过,链接2与链接1类似, 不重复爬取。
试验证明这种方法简捷高效,漏爬率极低,大大提升扫描器的效率。
4.爬虫的具体实现
a.webkit的易用性
常用的chrome, safari等浏览器都是基于webkit内核,不过提起这个内核,大家可能会觉得有点庞大艰深。但如果只是对于应用层面来说,webkit使用起来还是挺简易的。如图4-1所示,只需14行便可以写出一个浏览器。
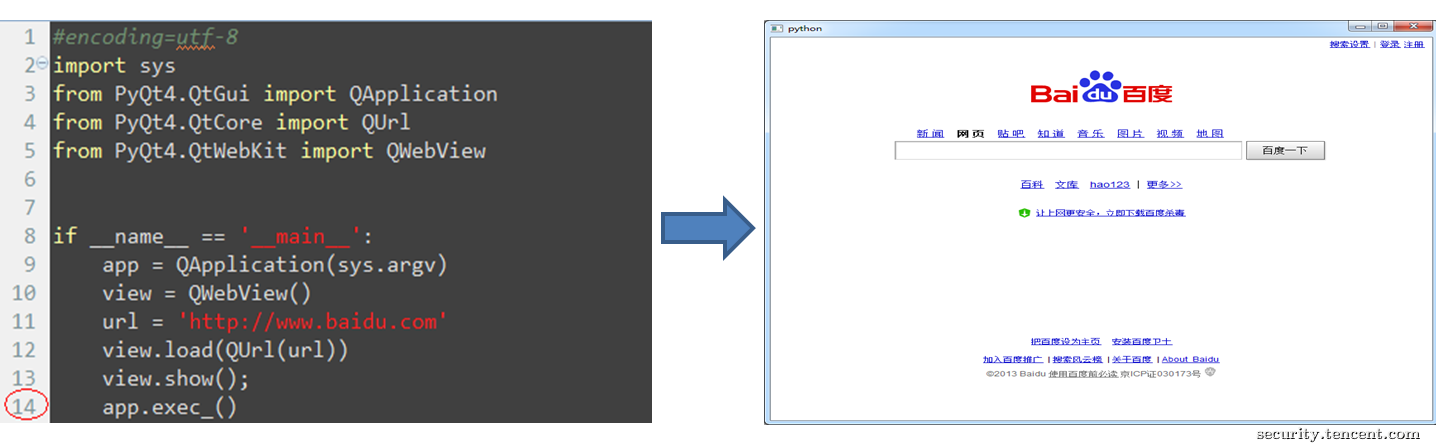
图4-1 使用webkit编写的浏览器
b.难点解决
问题:Webkit需要视窗系统才能正常启动,而服务器一般都没有视窗系统的,那么如何在后台稳定地运行webkit?之前是去掉webkit中的图形渲染,css等与gui有关的代码,太麻烦,易出众多bug。
解决:使用xvfb虚拟出一个视窗系统,只需把alert, confirm, prompt的代码注释掉(因为会让浏览器卡住),简单快捷稳定。
c.爬虫的逻辑代码
图4-2为爬虫的逻辑代码,在parse函数里利用webkit生成出来的dom树来做具体的第三部分所提到的分析逻辑。

图4-2 爬虫的逻辑代码
5.效果
SuperSpider与wvs的爬虫对比,在著名的爬虫测试平台http://demo.aisec.cn/demo/进行测试,该平台要求爬虫要完全具备3.1所提到的5个功能才能爬取到所有的url,上图为扫描器的爬虫,下图为wvs的爬虫, 其中click_link.php (在3.1.d提到)是需要爬虫具有自动交换能力才能爬取到的。
结论:SuperSpider全部都能爬到, 在自动交互方面比wvs表现更好
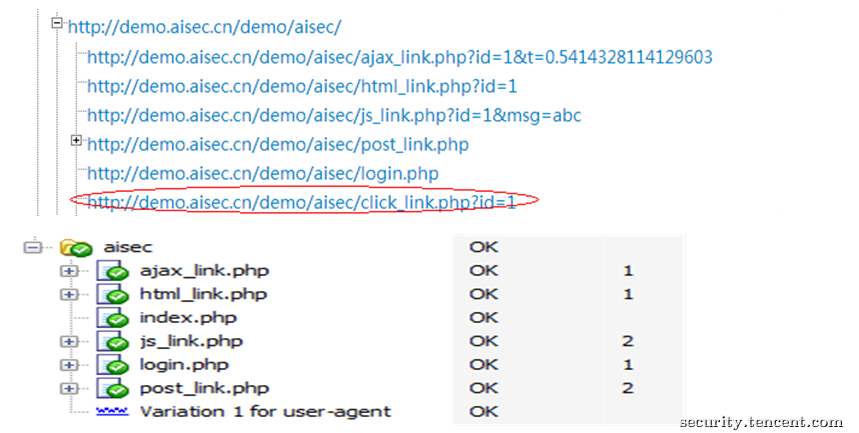
图4-1 SuperSpider与wvs的结果对比
6.结尾
以上笔者的一些思考与总结,欢迎大牛们的意见和建议!
标签:
原文地址:http://my.oschina.net/u/1454298/blog/364961