前言
并行就是让计算中相同或不同阶段的各个处理同时进行。目前有很多种实现并行的手段,如多核处理器,分布式系统等。本专题的文章将主要介绍使用 GPU 实现并行的方法。参考本专题文章前请务必搭建好 CUDA 开发平台,搭建方法可以参考上一篇文章。
GPU 并行的优缺点
优点:
1. 显存具有更大的内存带宽
2. GPU 具有更大量的执行单元
3. 价格低廉
缺点:
1. 对于不能高度并行化的工作,能带来帮助不大。
2. 对于绝大多数显卡型号,CUDA 仅支持 float 类型而不支持 double 类型运算,因此运算精度不高。
3. 目前还没有出现通用的 GPU 并行编程标准。
4. 处理前需要先将数据传输进显存,增加了一些时间开销。
5. 需要特定显卡型号(英伟达)的支持
较之 CPU ,GPU 适合一次性进行大量相同的工作,而 CPU 则比较有弹性,能同时进行变化较多的工作。
CUDA 结构
CUDA 是一种底层库,比 C/C++ 等语言以及 Open CV 之类的库更加底层,是附加在操作系统和这类程序之间的一层:
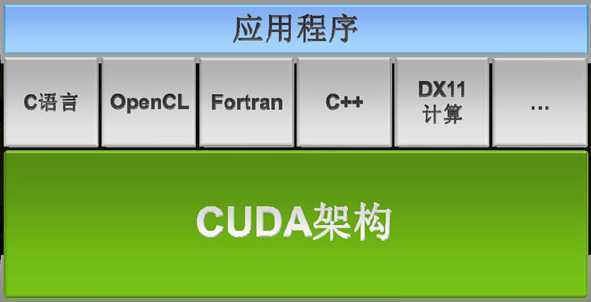
CUDA 程序架构
CUDA 架构下,程序分成两个部分:host 端和 device 端,前者在 CPU 部分执行,后者是在 GPU 部分执行。
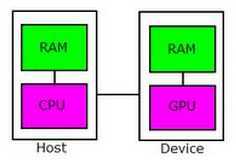
具体的 CUDA 程序执行过程如下:
1. host 端程序先将待处理数据传递进显存
2. GPU 执行 device 端程序
3. host 端程序将结果从显存取回
如下图所示:
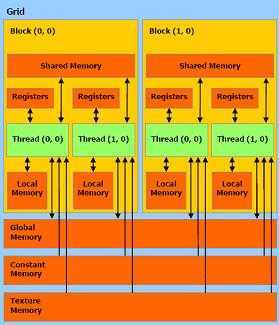
CUDA thread 架构
thread 架构分成三个等级:
1. 执行的最小单元是 thread
2. 多个 thread 可以组成一个 block,block 中的 thread 可并行执行且可存取同一块共享的显存。但要注意的是每个 block 中的 thread 是有数量限制的。
3. 多个 block 可以组成一个 grid,但 grid 中的 block 无法共享显存( 只能共享些别的信息 ),因此可合作度并不高。
如下图所示:
CUDA 程序执行模式
1. CUDA 程序利用并行化来替代内存 cache,即一个 thread 需要等待内存则 GPU 会切换到另一个 thread 执行。
2. CUDA 程序对于 "分支预处理" 的实现也是采用和 1 类似的方式
原文地址:http://www.cnblogs.com/scut-fm/p/3749455.html