标签:
Clustering-Based Ensembles as an Alternative to Stacking
作者:Anna Jurek, Yaxin Bi, Shengli Wu, and Chris D. Nugent, Member, IEEE
杂志:IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
这篇论文是聚类集成问题,聚类框架是传统的框架,按论文的说法有点创新,是将传统的分类集成框架,后半部分用聚类集成代替,最终的框架便是:
这样简单的结合其实很多发表论文已经用过,我认为这篇论文主要创新点是后半部分的论述:
为什么结合了分类标号作为新的属性,能够提升准确度。
论文指出以前论文的做法其实属于经验主义,而该论文则通过理论来推论证明。
对于监督学习,这个其实便是按传统的分类集成框架,如下:
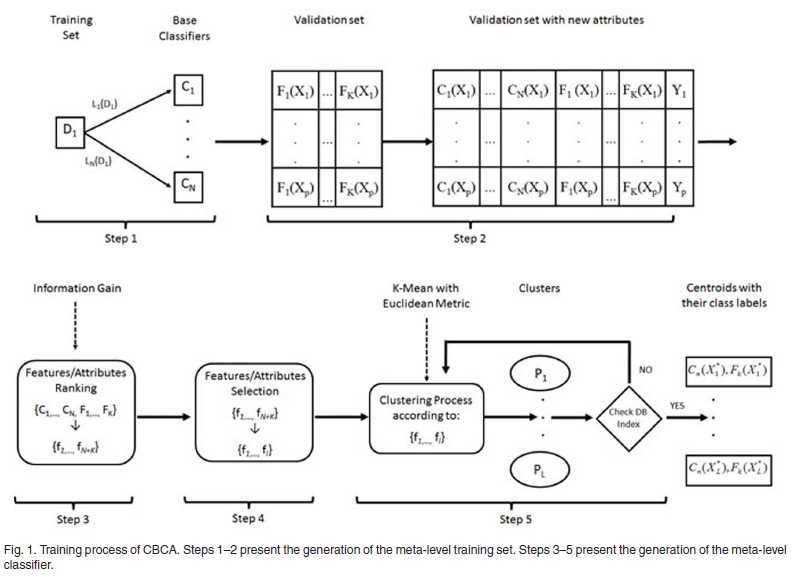
模型的训练如上,在模型训练后,对于新输入的数据集,便只计算样本原来的属性。
下面是论文的论述:
对于连个确定的集合(validation sets):
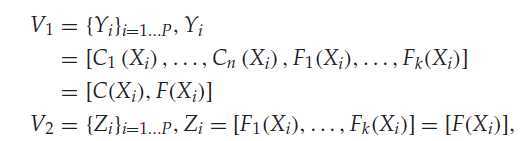
V1,V2,其实便是初始数据集通过了N个分类器之后的分类结果,作为样本的新属性C1 to Cn,与就的属性 F1 to Fk结合,这里的n k 小写意思是提取过的,P 是样本个数。
既然是讨论:为什么结合了分类标号作为新的属性,能够提升准确度。
那么便是一个添加了分类结果,一个没有添加,前者便是V1,后者便是V2.
问题便是:分别使用者两个确定集合,作kmeans 聚类,然后样本的类标号通过k 中心确定,为什么V1比V2准确率高。
分别对V1 V2进行kmeans 聚类,假设例子如下,左图的是V1,有图的是V2,其中的Y* Z* 便是类中心,可以看出V1 聚类成8个,V2聚类成7个:
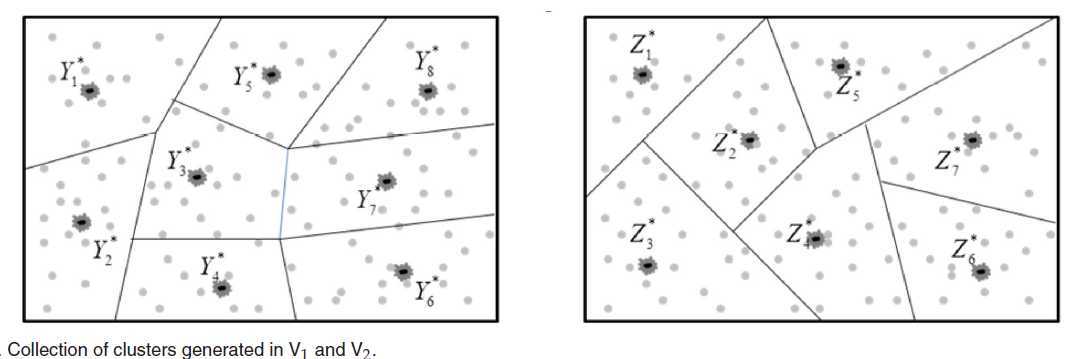
怎么确定一个聚类结果的类标号? 因为这是监督学习,所以是知道样本的类标号的,那么便是一个类中属于哪个类标号多的,这个类标号便是类中心的标号。这句话比较重要,因为后边的论述是以其为基础。
当然并不是全部的都考虑,例如上面划分直线附近的点,容易导致overlap,所以引入了如下约束:
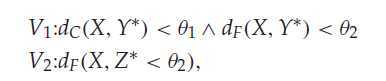
意思是便是只考虑距离类中心一定距离的样本点,其中dC、dF 表示样本X与中心Y* 之间的欧式距离,可以看出是拆开考虑,这两个临界值的取值如下:
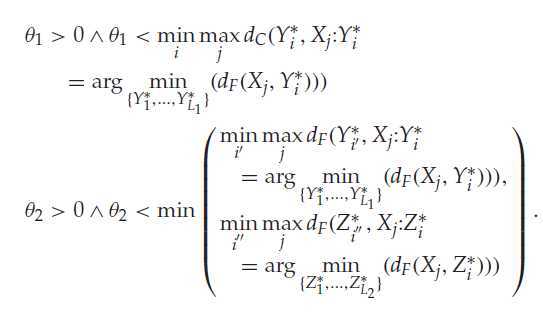
对于第一条,每个类中心,在其类中的样本点,选出到中心点最大的距离(dc),每个类都有一个这样 的距离,最后选择最小的作为θ1。
第二条,跟上面的类似的,只是衡量有dc 变成df,同时选择V1 V2 中较小的作为θ2.
这样的图示如下:
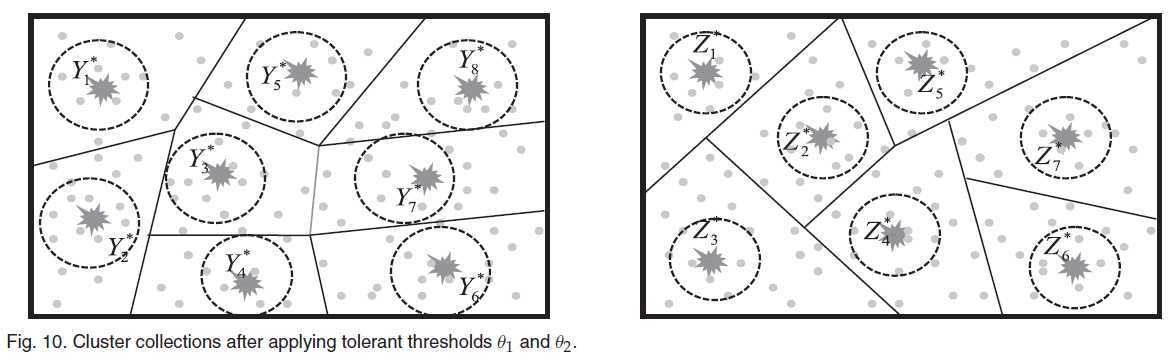
这样加了约束后,影响的是类中心的类标号确定,因为只考虑了约束内的样本点。在知道了类中心的类标号后,考虑分类阶段,对于一个不知道标号的样本X,通过原始属性F1 to Fk,来计算他离得最近的中心,然后用这个中心的类标号作为其标号,假设这个样本X的真实类标号为cr ,通过公式表示便是:
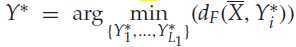
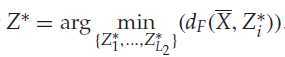
其中L1,表示类的个数,上图中L1 =8.
衡量准确度,便是衡量被预测样本X将要归属的类中心的标号是否与X 的真实类标号一样。通过概率表现如下:
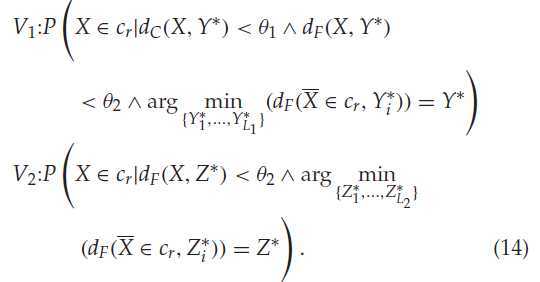
其中:
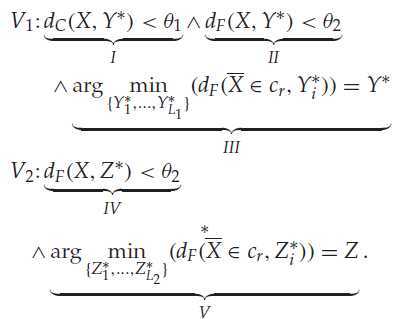
V1:I II 是为了为了约束的,III约束X 将要被分配到的类中心。
这样来看,其实证明上面的概率比下面的概率大,即X最近的聚类中心,通过添加分类标号作为属性的话,更有可能被确认为cr 标号。
通过一定推导可以得出下面公式,推导过程见论文附录。
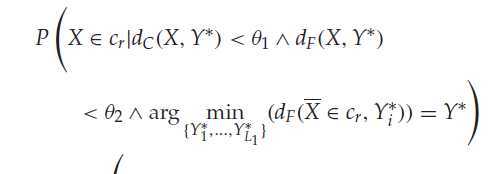 |
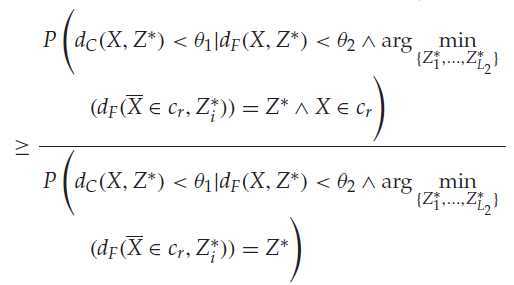 |
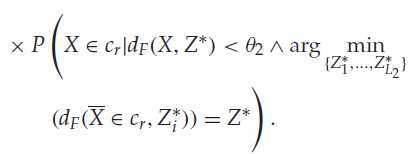 |
左边其实是V1 概率,右边是V2 概率。那么假如中间部分>=1,便可以得出左边>=右边。
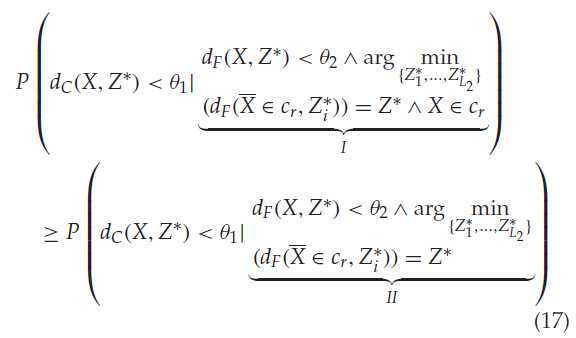
上面这个条件的成立,只需要下面条件成立,推导过程也在附录中。
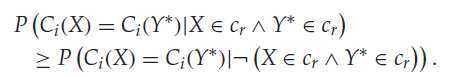
上面这条件的意思是:两个真实标号一样的样本,被分配到同一个分类中的概率,比两个真实标号不同的样本,分配到同一个分类中的概率大。
这其实是分类的作用了,论文中附录还证明了对于真实标号数目只有2时候,分类器的准确率达到0.5便可以使上式成立。
上面的 是分类标号+样本属性 > 样本属性,同时论文还证明 分类标号+样本属性 > 分类标号,只需满足一下条件:
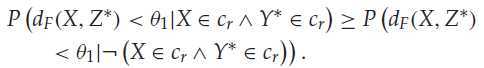
意思是:两个真实标号一样的样本,比两个真实标号不一样的样本更相似。
[论文]Clustering-Based Ensembles as an Alternative to Stacking
标签:
原文地址:http://www.cnblogs.com/Azhu/p/4213704.html