最近从Hadoop 1.x 转到Hadoop 2.x 同时将一些java 程序转为Scala的程序将平台上的代码减少了很多,在实施的过程中,开到一些Spark相关的YARN的部署上都是基于之前的Hadoop 1.x的部分方式,在Hadoop2.2 +版本之上 基本上就不用这么部署了。其原因就是Hadoop YARN 统一资源管理。
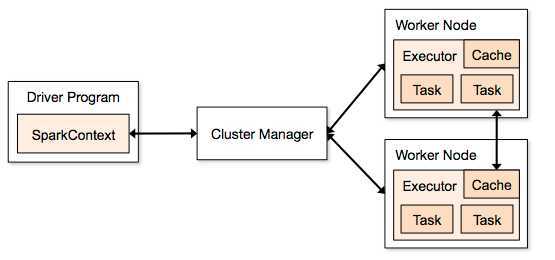
Spark应用在集群上以独立的进程集合运行,在你的主程序(称为驱动程序)中以SparkContext对象来调节。 特别的,为了在集群上运行,
SparkContext可以与几个类型的集群管理器(Spark自身单独的集群管理器或者Mesos/YARN)相连接,这些集群管理器可以在应用间分配资源。一旦连接,Spark需要在集群上的线程池子节点,也就是那些执行计算和存储应用数据的工作进程。然后,它将把你的应用代码(以JAR或者Python定义的文件并传送到SparkContext)发送到线程池。最后,SparkContext发送任务让线程池运行。(所以是通过SparkContext发送到其他节点的,在此你只是需要得到SparkContext,就行啦)。
关于这个架构有几个游泳的地方需要注意:
1.各个应用有自己的线程池进程,会在整个应用的运行过程中保持并在多个线程中运行任务。这样做的好处是把应用相互孤立,即在调度方面(各个驱动调度它自己的任务)也在执行方面(不同应用的任务在不同的JVM上运行)。然而,这也意味着若不把数据写到额外的存储系统的话,数据就无法在不同的Spark应用间(SparkContext的实例)共享。
2.对于潜在的集群管理器来说,Spark是不可知的。只要它需要线程池的进程和他们间的通信,那么即使是在也支持其他应用的集群管理器(例如,Mesos/YARN)上运行也相对简单。
3. 因为驱动在集群上调度任务,它应该运行接近到工作节点,在相同的局域网内更好。如果你想对远程的集群发送请求,较好的选择是为驱动打开一个RPC,让它就近提交操作而不是运行离工作节点很远的驱动。
集群管理类型
系统目前支持3中集群管理:
(1)单例模式 一种简单的集群管理,其包括一个很容易搭建集群的Spark
(2) Apache Mesos模式 一种通用的集群管理,可以运行Hadoop MapReduce和服务应用的模式
(3) Hadoop YARN模式 Hadoop 2.0 中的资源管理模式
其实,在Amazon EC2(亚马逊弹性计算云)中Spark的EC2启动脚本可以很容易的启动单例模式。
给集群发布代码
给集群发布代码的一种推荐的方式是通过SparkContext的构造器,这个构造器可以给工作节点生成JAR文件列表(Java/Scala)或者.egg文件和.zip包文件(Python)。你也可以执行SparkContext.addJar和addFile来动态的创建发送文件。
监控器
每个驱动程序有一个Web UI,典型的是在4040端口,你可以看到有关运行的任务,程序和存储空间大小等信息。你可以在浏览器中输入简单的URL方式来访问:http://<驱动节点>::4040.监控器也可以指导描述其它监控信息。(如果你使用的Spark YARN 模式的,只有运行Spark才能看到UI页面,你停止了,log数据就没了,但你可以将log持久化)。
任务调度
Spark可以通过在应用外(集群管理水平)和应用里(如果在同一个SparkContext中有多个计算指令)资源分配。