标签:des style class blog c code
近期总有开发同事过来抱怨说有写执行超时,但是查看相关语句又没有任何问题,统计正常,执行计划合理,IO压力较低,锁也正常,正常5ms可以结束的SQL竟然超时,不可思议,但由于超时的时间和频率不固定,我们很难捕捉到超时的时间点上服务器的状态,肖磊同志明锐地发现该数据库日志日志已暴涨至200+GB,于是慢慢折腾路开始。。。
--===========================================================
首先出场的是肖桑,我在旁围观,当我们发现日志暴涨这么大的时候,第一时间检查日志的使用情况
首先查看日志的大小和使用情况
DBCC SQLPERF(LOGSPACE)
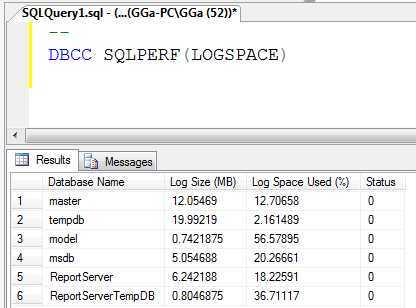
发现日志文件超过200GB,日志使用率为99%,也就是说大部分是活动日志
肖桑作为DBR,自然优先考虑
DBCC LOGINFO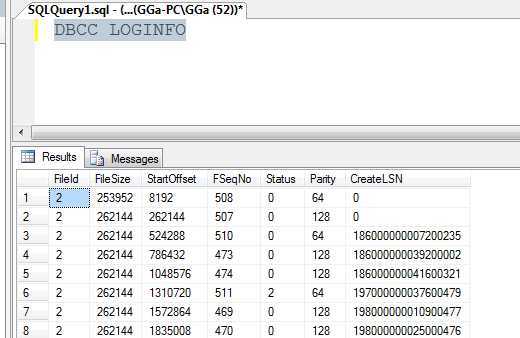
DBCC LOGINFO显示数据库日志文件有1.6W,几乎全部处于活跃状态(status=2)(上图只是示例)
不知道肖桑有没有运行查看过日志等待状态,反正我当时没查
--查看日志等待状态 SELECT DB.name, DB.log_reuse_wait_desc FROM SYS.databases DB
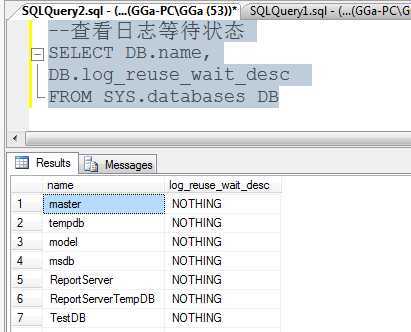
由于我们经常遇到镜像阻塞复制或者镜像问题导致日志增大的情况,而问题数据库恰好配置为镜像,显示状态为正在同步,SO,我们做了一个艰难的决定--取消镜像
这应该算一个轻率的决定,正常情况即使确定是镜像问题,我们仍需要确定什么导致镜像出现问题(如何检查请参考http://www.cnblogs.com/TeyGao/p/3521677.html)以及寻找最佳解决办法,或许是由于重做镜像太过简单,我们就轻易地选择了移除镜像。
镜像移除后,我们查看复制情况
--================================================= --为每个发布数据库返回有关滞后时间、吞吐量和事务计数的复制统计信息。 --此存储过程在发布服务器的任何数据库中执行。 --http://msdn.microsoft.com/ZH-CN/library/ms190486.aspx EXEC SP_REPLCOUNTERS
结果我们惊奇地发现:
日志中等待传送到分发数据库的事务数(Replicated transactions):12000W+
平均每秒传送到分发数据库的事务数(Replication rate trans/sec): 7000+
我们做了一个简单的运算:SELECT 120000000.0/7000/60/60=5,考虑Replication
rate
trans/sec 的值上下波动,我们将预估时间定位4到6个小时,这个时间还在我们接受范围内,于是乎,我们选择了等待。。。
随着时间的飞逝(当年常用的可是白马过隙),Replication rate
trans/sec的值逐渐从7000+减低到4000+再到700+然后到400+,我们的预估时间变成2-4天,很恐怖的一个数字啊!
由于我们之前已经定位到vlf为数量过多,而我们潜在认为这既是影响复制的问题,所以我们没有做过多的分析便坐等复制正常,直到预估时间超过我们接受范围,此时时间距离问题发现已经过去一天多。
由于复制恢复时间超出我们预期,而且订阅对整个业务的重要性很低,可以先移除再重做,为不影响业务,我们选择移除订阅,为谨慎起见,我们没有直接删除订阅,而是选择修改订阅的存储过程,我们认为注释掉存储过程中的代码,也可以达到移除订阅类似的目的,避免订阅运行复制命令所产生的消耗,于是我们发动同事一起修改相关的付复制存储过程。
当我们费了九牛二虎之力把存储过程修改完以后,发现没有任何帮助(好悲催的赶脚)
本着生命在于折腾的精神,我开始分析传送事务越来越慢的原因,优先是检查磁盘,由于发布分发和订阅使用的都是IO卡,虽然在订阅上能捕获到一些写日志等待,但是还在接受范围内,于是我开始检查是否因为大事务导致复制问题。

--=============================================================== --在分发库上查找大事务 USE distribution GO SELECT xact_seqno, COUNT(*) AS [COUNT] INTO #MSrepl_commands FROM dbo.MSrepl_commands GROUP BY xact_seqno HAVING COUNT(*)>100 SELECT t.xact_seqno,t.entry_time,c.[count] FROM MSrepl_Transactions t INNER JOIN #MSrepl_commands c ON t.xact_seqno=c.xact_seqno ORDER BY c.count DESC,t.entry_time
天佑我大中华,我顺利抵捕获到一个包含120w命令的大事务(另外一个发布库上的发布,但是与问题发布库使用相同的分发库和订阅库),于是乎,全世界的目光集中在这个大事务上,各种炮火对准,在确定相关影响后,我们快刀斩乱码,直接将那个复制干掉了。
我们悲哀地发现,以上操作都对Replication rate
trans/sec没有任何影响,就好比北京到西藏的车流很慢,我们就把西藏到北京北京周边的路修成十车道的高速路,结果悲催发现车都堵在三环路上一样。
问题还在发布库上,我们要解决日志过大问题,要么等复制相关事务从日志被读取到分发库,要么删除复制,前者太慢不可取,只能选择删除复制,又是一个手起刀落,复制被干掉了。。。
正准备高唱“解放区的天是蓝蓝的天”的时候,心急的同事已经忙着备份日志收缩数据库了,结果悲催地发现,备份收缩无效,使用EXEC SP_REPLCOUNTERS依然发现还有大量等待传送的事务已经慢的可怜的传说速度。。。
一定是我们打开方式不对,一定是的。。。
查看日志等待状态,小伙伴们惊奇发现,日志等待状态依然是复制,这是为什么呢?
经过仔细分析,CDC成为焦点,有业务需要依据CDC的变更记录来同步数据到ORACLE数据库,ORACLE的同事很傲娇地告诉我们,他们程序运行正常,没有问题,数据已同步。。。
当我们差点要忽略CDC的时候,作死的我还是逼着同事检查了一遍,因为复制和CDC是共用一个logreader,既然复制延迟了好几天,没道理CDC正常同步啊!
果不其然,CDC大有问题,大概了解的结果是有个应用程序会读取CDC相关的数据到ORACLE数据库,其中一个表出了问题,导致程序没有正常运行,然后就阻塞了CDC,EXEC SP_REPLCOUNTERS显示的就是CDC的相关信息,只是被打上了复制的旗号,于是乎CSC成了挡在我们前面的绊脚石,带着佛挡杀佛人挡杀人的气势,反正我们相继灭杀了“镜像”和“复制”这两大令日志暴涨的罪恶之手,也不在乎在多灭杀一个CDC,果断再次手起刀落,整个数据库级别禁用CDC.
终于,世界清静了,日志文件的使用率也有原来的99%降低到1%,在经过几次日志备份和收缩,日志文件又恢复到正常大小,正义战胜了邪恶,七个小矮人和白雪公主又过上了幸福美满的生活,世界和平是如此的美好。。。
--========================================================
在整个处理过程中,我们急于求成到心理导致出现了很多问题,由于想着尽快解决问题,以及一定的自负心理(各位同事不要打我),让我们将没有经过太多的理论分析操作直接在生产服务器上运行,尽管我们在操作前已经评估这些操作带来的影响,却没有仔细评估这些操作是否能带来我们期望的结果,因此导致我们做了很多的无用功和浪费了很多宝贵时间,所幸所有影响都在可控和可接受范围内
PS:以上总结值得很多DBA同仁的引以为戒
--=======================================================
夜深了,你看妹子都趴着想睡觉了


杂谈--一次”失败“问题处理过程,布布扣,bubuko.com
标签:des style class blog c code
原文地址:http://www.cnblogs.com/TeyGao/p/3750688.html