标签:
将之前会议中记录的设计要点进行总结和规划,供团队内开发者和测试人员进行代码编写与测试。
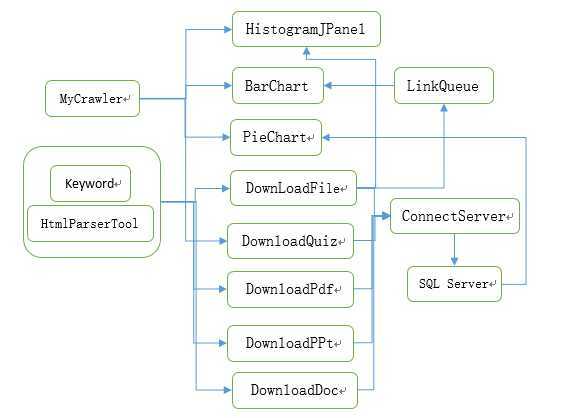
软件名: 网络资源收集工具
本软件任务:为下一组元数据抽取和整理工具进行对接,为下一组提供其所需的各类海量数据。
将35w+个符合条件的网页,问答,文章放入数据库,具体请参见需求文档。

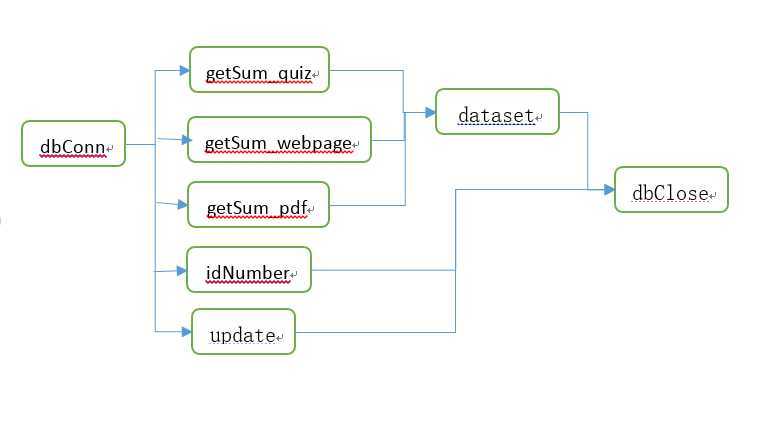
连接数据库服务器,进行插入以及查询数据库操作。
快速打开和关闭数据库连接,执行sql查询和插入时不会出现连接死锁。
|
程序 |
input |
processing |
output |
|
dbConn |
|
初始化数据库连接 |
数据库连接结果 |
|
dbClose |
|
断开数据库连接 |
断开数据库连接结果 |
|
dataset |
数据库查询SQL语句 |
执行sql查询 |
查询结果 |
|
getSum_webpage |
|
执行sql查询 |
全部网页个数 |
|
getSum_quiz |
|
执行sql查询 |
全部问答页个数 |
|
getSum_pdf |
|
执行sql查询 |
全部pdf个数 |
|
update |
数据库查询SQL语句 |
互斥更新数据库 |
更新结果 |
|
idNumber |
|
执行sql查询 |
数据库最大ID号 |
Sql语句有:
1、得到全部网页个数
declare @a int select @a=dbo.getSum_webpage(‘webpage‘) select num=@a
2、得到全部问答页个数
declare @a int select @a=dbo.getSum_quiz(‘quiz‘) select num=@a
3、得到全部pdf个数
declare @a int select @a=dbo.getSum_pdf(‘pdf‘) select num=@a
4、获取数据库最大ID号
select max(id) from fileinfo
SQLException的捕获
异步更新的互斥性
查询的准确性
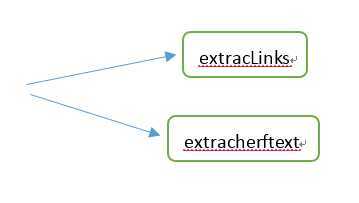
过滤并获取指定网址的子链接,同时更新网站子链接的修改时间。
能快速地过滤并获取指定网址的子链接,同时获得网站子链接的修改时间。
|
程序 |
input |
processing |
output |
|
extracLinks |
网址url,过滤器filter |
爬取得到url的所有子链接,并且根据过滤器filter对得到的子链接进行过滤。 |
爬取并过滤的结果 |
|
extracherftext |
网址url |
获得该网址子链接的修改时间 |
获得的修改时间 |
利用OrFilter筛选出所有 <a> 标签和 <frame> 标签(满足两者之一即可被选中),再利用标签类别过滤(LinkTag.class => <a>标签)。本程序中,过滤了后缀为"mp4","rar","wmv","ppt","zip","gz","aspx"的文件。

指定一个链接,其子链接中有各种指定的需要过滤的类型,使用程序进行爬取,查看是否如预期一般爬取了所有的子链接并且将指定类型文件过滤掉未爬取。
实现精确爬取指定的链接,从该链接及其所有子链接中将指定类型的文件下载到本地,并更新数据库。
采用多线程爬取,对于不同网站,采用不同爬取措施,少量国外网站因为网路问题和权限问题需要通过暂停线程避免异常,大部分网站可以实现快速爬取。而且此次版本解决了因为异常造成的线程中断的问题,可以持续不断地大量爬取。
|
程序 |
input |
processing |
output |
|
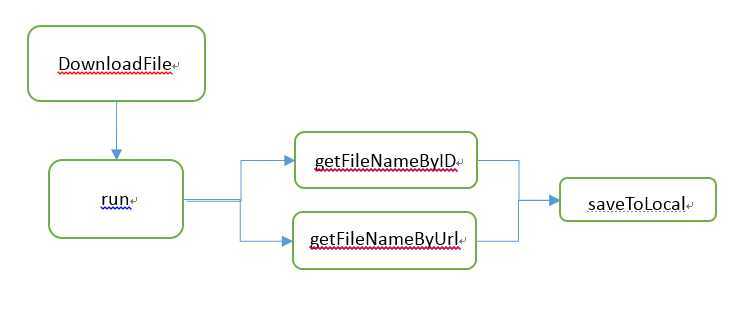
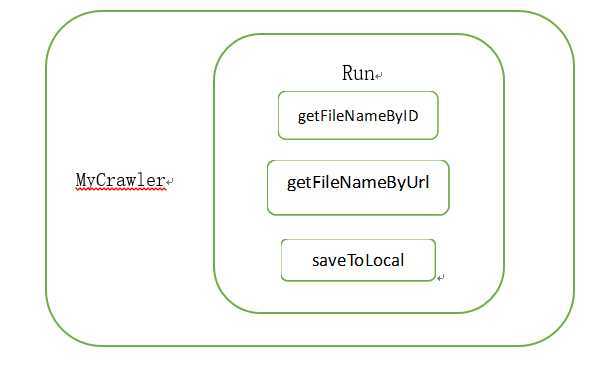
DownLoadFile |
网站链接和过滤器 |
初始化爬取线程 |
生成新的爬取线程 |
|
run |
|
执行爬取线程 |
爬取线程执行结果 |
|
getFileNameByID |
文件在数据中的id号和网站类型 |
根据id计算网站在本地和数据库存取的文件名 |
生成网站在本地和数据库存取的文件名 |
|
getFileNameByUrl |
网址和网站类型 |
根据url计算网站在本地和数据库存取的文件名 |
生成网站在本地和数据库存取的文件名 |
|
saveToLocal |
暂存网站内容的数组和存在本地的路径 |
将网站内容存在指定路径的文件中 |
将网站存进本地中 |
根据输入的url,爬取该网址下所有子链接,对于爬取到的文件,符合过滤器条件的则滤去,不符合的则下载到本地并以指定的方式命名,同时插入数据库。
每个网站的爬取占用一个线程,因为不同网站结构和下载速度不同,故将同一网站的爬取放在同一个线程。每个线程扫描一个问题列表页面的子链接,并下载子页面。每个线程设定一个标记变量,代表当前网站正在爬取中或者处于空闲。爬取某个网站遇到异常,或者当前线程结束,就将标记变量置为空闲状态,这样做解决了多次遇到异常后,所有网站仍处于工作状态导致爬取无法继续的bug。
爬取是否会中断,中断后是否有重连措施;
爬取的速度;
本地文件与数据库的一致性。
SQLException, HttpException, IOException的捕获;
异步更新的互斥性;
实现精确爬取quiz界面,从特定网站中筛选出相应的问答页面,下载到本地,并更新数据库。
采用多线程爬取,对于不同网站,采用不同爬取措施,少量国外网站因为网路问题和权限问题需要通过暂停线程避免异常,大部分网站可以实现快速爬取。而且此次版本解决了因为异常造成的线程中断的问题,可以持续不断地大量爬取。
|
程序 |
input |
processing |
output |
|
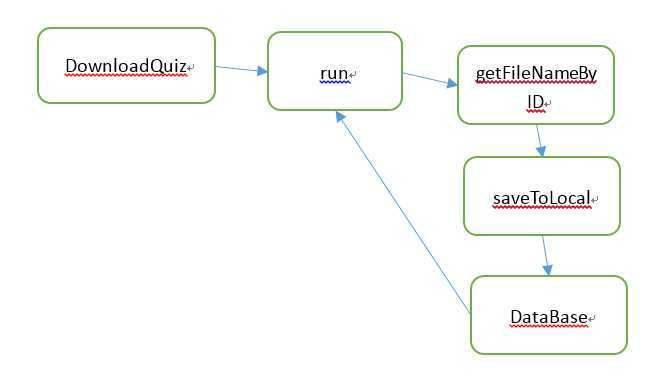
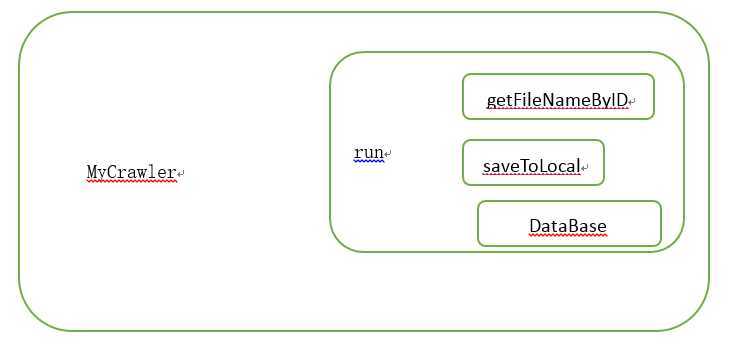
DownloadQuiz |
网站链接和代表网站种类的编号 |
初始化爬取所需数据 |
生成新的爬取线程 |
|
run |
|
执行爬取线程 |
爬取线程结束 |
|
DataBase |
下载的网站的链接和下载到本地的位置 |
确定网站信息并执行sql语句更新数据库 |
更新刚下载的文件在数据库中的信息 |
|
getFileNameByID |
文件在数据中的id号和网站类型 |
根据id计算网站在本地和数据库存取的文件名 |
生成网站在本地和数据库存取的文件名 |
|
getSum_quiz |
|
执行sql查询 |
全部问答页个数 |
|
saveToLocal |
暂存网站内容的数组和存在本地的路径 |
将网站内容存在指定路径的文件中 |
将网站存进本地中 |
1.选择国内外知名问答网站:搜搜问问,百度知道,stackoverflow,德问,博客园等。确定这些网站的”已解决问题“列表。
2.扫描”已解决问题列表“,根据字符串匹配,确定列表下的问答子页面的链接。调用URL类的openstream方法,下载问答页面源代码。
3.多线程方面,每个网站的爬取占用一个线程,因为不同网站结构和下载速度不同,故将同一网站的爬取放在同一个线程。每个线程扫描一个问题列表页面的子链接,并下载子页面。每个线程设定一个标记变量,代表当前网站正在爬取中或者处于空闲。爬取某个网站遇到异常,或者当前线程结束,就将标记变量置为空闲状态,这样做解决了多次遇到异常后,所有网站仍处于工作状态导致爬取无法继续的bug。
SQLException, HttpException, IOException的捕获;
异步更新的互斥性;
线程的安全性与健壮性,爬取是否会中断;
爬取的速度;
本地文件与数据库的一致性。
实现精确爬取pdf页面,从给定网站中筛选出pdf页面,下载到本地,并更新数据库。
由于服务器网速限制,采用多线程的方式对速度基本没有改善,故采用单线程爬取,对于不同网站,采用不同爬取措施,对于1M以内的pdf页面可以实现快速爬取。
|
程序 |
input |
processing |
output |
|
DownloadPdf |
网站链接 |
初始化爬取所需数据 |
爬取结果 |
|
run |
|
执行爬取一般pdf |
爬取结束 |
|
runForBerkeley |
|
执行爬取伯克利publication操作 |
爬取结束 |
|
DataBase |
下载的网站的链接和下载到本地的位置 |
确定网站信息并执行sql语句更新数据库 |
更新刚下载的文件在数据库中的信息 |
|
getFileNameByID |
文件在数据中的id号和网站类型 |
根据id计算网站在本地和数据库存取的文件名 |
生成网站在本地和数据库存取的文件名 |
|
getSum_pdf |
|
执行sql查询 |
全部问答页个数 |
|
saveToLocal |
暂存网站内容的数组和存在本地的路径 |
将网站内容存在指定路径的文件中 |
将网站存进本地中 |
1.选择国内外知名大学课程网站:stanford、berkeley、buffalo、MIT等等。
2.扫描各个大学网站的课程网站页面,获取lecture、handout、publications等链接,将符合条件的pdf下载到本地。
3.下载文件方面需要使用输入输出流,不能逐行复制网页源代码。


SQLException, HttpException, IOException的捕获;
爬取的速度;
本地文件与数据库的一致性。
实现精确爬取doc页面,从给定网站中筛选出doc页面,下载到本地,并更新数据库。
由于服务器网速限制,采用多线程的方式对速度基本没有改善,故采用单线程爬取,对于不同网站,采用不同爬取措施,对于1M以内的pdf页面可以实现快速爬取。
|
程序 |
input |
processing |
output |
|
DownloadDoc |
网站链接 |
初始化爬取所需数据 |
爬取结果 |
|
run |
|
执行爬取doc |
爬取结束 |
|
DataBase |
下载的网站的链接和下载到本地的位置 |
确定网站信息并执行sql语句更新数据库 |
更新刚下载的文件在数据库中的信息 |
|
getSum_doc |
|
执行sql查询 |
全部doc个数 |
|
saveToLocal |
暂存网站内容的数组和存在本地的路径 |
将网站内容存在指定路径的文件中 |
将网站存进本地中 |
1.选择国内外知名大学课程网站:stanford、berkeley、buffalo、MIT等等。
2.扫描各个大学网站的课程网站页面,获取lecture、handout、publications等链接,将符合条件的doc下载到本地。
3.下载文件方面需要使用输入输出流,不能逐行复制网页源代码。

SQLException, HttpException, IOException的捕获;
爬取的速度;
本地文件与数据库的一致性。
实现精确爬取ppt页面,从给定网站中筛选出ppt页面,下载到本地,并更新数据库。
由于服务器网速限制,采用多线程的方式对速度基本没有改善,故采用单线程爬取,对于不同网站,采用不同爬取措施,对于1M以内的pdf页面可以实现快速爬取。
|
程序 |
input |
processing |
output |
|
DownloadPPt |
网站链接 |
初始化爬取所需数据 |
爬取结果 |
|
run |
|
执行爬取ppt |
爬取结束 |
|
DataBase |
下载的网站的链接和下载到本地的位置 |
确定网站信息并执行sql语句更新数据库 |
更新刚下载的文件在数据库中的信息 |
|
getSum_ppt |
|
执行sql查询 |
全部ppt个数 |
|
saveToLocal |
暂存网站内容的数组和存在本地的路径 |
将网站内容存在指定路径的文件中 |
将网站存进本地中 |
1.选择国内外知名大学课程网站:stanford、berkeley、buffalo、MIT等等。
2.扫描各个大学网站的课程网站页面,获取lecture、handout、publications等链接,将符合条件的ppt下载到本地。
3.下载文件方面需要使用输入输出流,不能逐行复制网页源代码。
SQLException, HttpException, IOException的捕获;
爬取的速度;
本地文件与数据库的一致性。
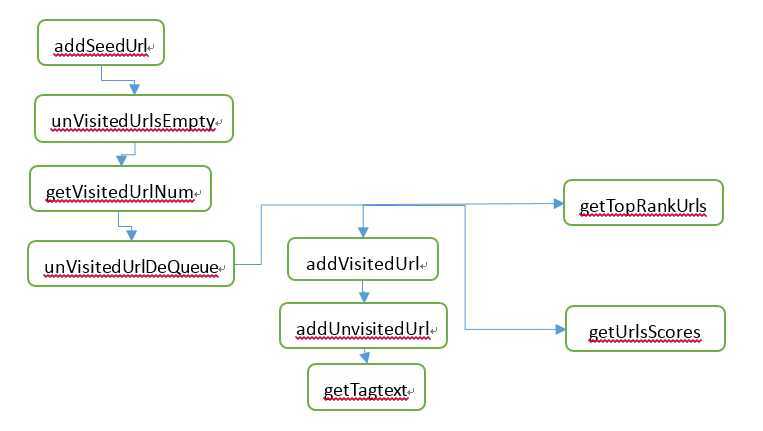
管理所有待访问和已访问的网址链接,并服务于PageRank排序,并能产出TOP10个最热网页。
队列可以承受足够数量的网址存储空间,出队与入队可以快速完成,使用hash表加速到O(1)的查询复杂度。
|
程序 |
input |
processing |
output |
|
getUnVisitedUrl |
|
获得RankUrl队列 |
未访问需排名链接 |
|
getTagtext |
|
获得tag表 |
所有tag |
|
addVisitedUrl |
已访问url |
添加url到访问过的URL队列中 |
查询结果 |
|
addSeedUrl |
未访问url |
添加url到未访问的URL队列中 |
添加结果 |
|
unVisitedUrlDeQueue |
|
未访问的URL出队列 |
添加结果 |
|
addUnvisitedUrl |
要访问的链接和刚刚访问的链接 |
记录刚刚访问的链接的子链接并将要访问的链接入队 |
添加结果 |
|
getVisitedUrlNum |
|
获得已经访问的URL数目 |
查询结果 |
|
unVisitedUrlsEmpty |
|
判断未访问的URL队列中是否为 |
查询结果 |
|
getUrlsScores |
|
使用PageRank算法计算Url的重要性排序 |
获得Url的重要性排序 |
|
getTopRankUrls |
|
获得排序top10以内的Url和分数 |
获得排序top10以内的Url和分数 |
核心思想有2点:
1.如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是pagerank值会相对较高;
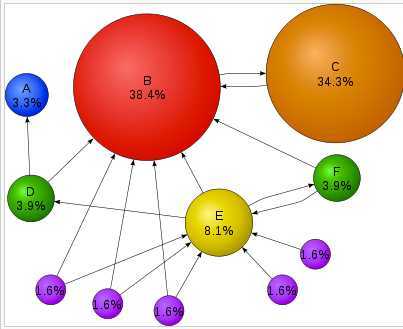
2.如果一个pagerank值很高的网页链接到一个其他的网页,那么被链接到的网页的pagerank值会相应地因此而提高。
下面是一张来自WikiPedia的图,每个球代表一个网页,球的大小反应了网页的pagerank值的大小。指向网页B和网页E的链接很多,所以B和E的pagerank值较高,另外,虽然很少有网页指向C,但是最重要的网页B指向了C,所以C的pagerank值比E还要大。

海量数据承受力。
获取待访问网址速度。
热度排序准确性。
过滤符合过滤条件的网页。
过滤速度稳定。
|
程序 |
input |
processing |
output |
|
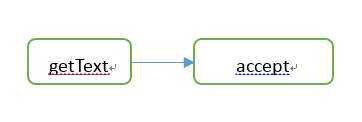
getText |
网址链接url |
获取此URL对应网页的纯文本信息 |
网页的纯文本信息 |
|
accept |
URL对应网页的纯文本信息 |
给出指定URL是否符合过滤条件 |
是否符合过滤条件 |
若页面中不含关键词则满足过滤条件。
获取网页纯文本速度。
关键词筛选是否准确。
通用型爬取、聚集型爬取、综合型爬取、问答页爬取、pdf爬取、doc爬取、ppt爬取功能的入口。
海量数据爬取速度可以接受。
问答页筛选的准确性。
|
程序 |
input |
processing |
output |
|
initCrawlerWithSeeds |
种子网址链接 |
使用种子初始化 URL队列 |
初始化结果 |
|
STCrawling |
种子网址链接 |
抓取stackoverflow页面 |
抓取结果 |
|
CNCrawling |
种子网址链接 |
抓取q.cnblogs页面过程 |
抓取结果 |
|
DWCrawling |
种子网址链接 |
抓取dwen页面过程 |
抓取结果 |
|
BZCrawling |
种子网址链接 |
抓取zhidao.baidu页面过程 |
抓取结果 |
|
WWCrawling |
种子网址链接 |
抓取wenwen页面过程 |
抓取结果 |
|
QuizCrawling |
种子网址链接 |
抓取问答页面过程 |
抓取结果 |
|
pdfCrawling |
种子网址链接 |
抓取pdf过程 |
抓取结果 |
|
docCrawling |
种子网址链接 |
抓取doc过程 |
抓取结果 |
|
pptCrawling |
种子网址链接 |
抓取ppt过程 |
抓取结果 |
|
crawling |
种子网址链接 |
通用型抓取过程 |
抓取结果 |
|
setKeyword |
关键字 |
设置关键字 |
设置结果 |
|
main |
命令行参数 |
整个项目入口 |
|
FileNotFoundException、IOException、InterruptedException、InstantiationException、IllegalAccessException、UnsupportedLookAndFeelException的捕获
爬取是否会中断,中断后是否有重连措施;
爬取的速度需要稳定;
本地文件与数据库的一致性。
通过管理数据库表[yuanhang].[dbo].[fileinfo],为下一组提供其所需的各类海量数据的查询服务。
数据查询和插入的速度可以接受。
|
数据组名:fileinfo 文件信息 |
||||
|
数据项名 |
数据类型 |
数据宽度 |
允许空值否 |
值约束 |
|
[id]网页id |
int |
11 |
否 |
无 |
|
[myUrl]域名 |
nvarchar |
max |
是 |
无 |
|
[filepath] 文件存储路径 |
nvarchar |
max |
是 |
无 |
|
[encode] 编码方式 |
nchar |
10 |
是 |
无 |
|
[pagetype] 网页类型 |
nchar |
10 |
是 |
无 |
|
[lastcrawlertime] 最后被爬到的时间 |
datetime |
25 |
是 |
无 |
|
[freshtime] 更新时间 |
datetime |
25 |
是 |
无 |
|
[keywords]关键词 |
text |
|
是 |
无 |
|
[tag] 标签 |
text |
|
是 |
无 |
|
[host] IP地址 |
nvarchar |
max |
是 |
无 |
得到所有doc的数目
USE [yuanhang]
GO
/****** Object: UserDefinedFunction [dbo].[getSum_doc] Script Date: 01/13/2015 18:00:51 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create function [dbo].[getSum_doc] (@a nchar(10))
returns int
as begin
if((select COUNT(pagetype) from fileinfo where pagetype=‘doc‘)!=0)
begin
return (select COUNT(pagetype) from fileinfo where pagetype=‘doc‘)
end
return 0
end
得到所有pdf的数目
USE [yuanhang]
GO
/****** Object: UserDefinedFunction [dbo].[getSum_pdf] Script Date: 01/13/2015 18:03:40 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create function [dbo].[getSum_pdf] (@a nchar(10))
returns int
as begin
if((select COUNT(pagetype) from fileinfo where pagetype=‘pdf‘)!=0)
begin
return (select COUNT(pagetype) from fileinfo where pagetype=‘pdf‘)
end
return 0
end
得到所有ppt的数目
USE [yuanhang]
GO
/****** Object: UserDefinedFunction [dbo].[getSum_ppt] Script Date: 01/13/2015 18:03:55 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create function [dbo].[getSum_ppt] (@a nchar(10))
returns int
as begin
if((select COUNT(pagetype) from fileinfo where pagetype=‘ppt‘)!=0)
begin
return (select COUNT(pagetype) from fileinfo where pagetype=‘ppt‘)
end
return 0
end
得到所有quiz的数目
USE [yuanhang]
GO
/****** Object: UserDefinedFunction [dbo].[getSum_quiz] Script Date: 01/13/2015 18:04:07 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create function [dbo].[getSum_quiz] (@a nchar(10))
returns int
as begin
if((select COUNT(pagetype) from fileinfo where pagetype=‘quiz‘)!=0)
begin
return (select COUNT(pagetype) from fileinfo where pagetype=‘quiz‘)
end
return 0
end
得到所有webpage的数目
USE [yuanhang]
GO
/****** Object: UserDefinedFunction [dbo].[getSum_webpage] Script Date: 01/13/2015 18:04:19 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create function [dbo].[getSum_webpage] (@a nchar(10))
returns int
as begin
if((select COUNT(pagetype) from fileinfo where pagetype=‘webpage‘)!=0)
begin
return (select COUNT(pagetype) from fileinfo where pagetype=‘webpage‘)
end
return 0
end
为了防止数据库中出现具有重复域名的网页,需要在每次插入数据时设置触发器使得每次插入的数据中的域名不会与数据库中任意一项相同。
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <LYP>
-- Create date: <2014.12.27>
-- Description:
-- =============================================
CREATE TRIGGER tgr_classes_insert_yuanhang
ON [yuanhang].[dbo].[fileinfo]
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
declare @id int , @name nvarchar(MAX);
--在inserted表中查询已经插入记录信息
select @id = [id] , @name = [myUrl] from inserted;
delete from [yuanhang].[dbo].[fileinfo]
where [myUrl] in (select [myUrl] from [yuanhang].[dbo].[fileinfo] where [myUrl] = @name group by [myUrl])
and [id] not in (select min([id]) from [yuanhang].[dbo].[fileinfo] where [myUrl] = @name group by [myUrl]) ;
END
数据库中是否存在myUrl列值重复的元组
插入和查询数据的速度
本地文件与数据库的一致性。
标签:
原文地址:http://www.cnblogs.com/newbe/p/4189893.html