标签:
1、笔记本4G内存 ,操作系统WIN7
2、工具VMware Workstation
3、虚拟机:CentOS6.4共五台
4、搭建好Hadoop集群( 方便Spark可从HDSF上读取文件,进行实验测试)
Hadoop HA集群:
|
Ip |
hostname |
role |
|
192.168.249.130 |
SY-0130 |
ActiveNameNode |
|
192.168.249.131 |
SY-0131 |
StandByNameNode |
|
192.168.249.132 |
SY-0132 |
DataNode1 |
|
192.168.249.133 |
SY-0133 |
DataNode2 |
Spark HA集群:
|
Ip |
hostname |
role |
|
192.168.249.134 |
SY-0134 |
Master |
|
192.168.249.130 |
SY-0130 |
StandBy Master |
|
192.168.249.131 |
SY-0131 |
worker |
|
192.168.249.132 |
SY-0132 |
worker |
|
192.168.249.133 |
SY-0133 |
worker |
实验环境仅作学习用,4G内存确实蛮拼的,资源非常有限。下周换上几台台式机作集群。
上述SY-0134是新克隆的虚拟机,作为Spark的环境中的Master,原属于Hadoop集群中的4个节点分别作为StandByMaster 和 Worker角色。
关于虚拟机环境设置、网络配置、Hadoop集群搭建参见 《Hadoop2.6集群环境搭建》
本文重点关注Spark1.2环境、Zookeeper环境简易搭建,仅作学习与实验原型,且不涉及太多理论知识。
(注:用户hadoop登录SY-0134)
1、在节点SY-0134,hadoop用户目录创建toolkit 文件夹,用来保存所有软件安装包,建立labsp文件作为本次实验环境目录。
[hadoop@SY-0134 ~]$ mkdir labsp
[hadoop@SY-0134~]$ mkdir toolkit
我将下载的软件包存放在toolkit中如下
[hadoop@SY-0134 toolkit]$ ls hadoop-2.5.2.tar.gz hadoop-2.6.0.tar.gz jdk-7u71-linux-i586.gz scala-2.10.3.tgz spark-1.2.0-bin-hadoop2.3.tgz zookeeper-3.4.6.tar.gz
2、这次实验我下载的Spark包是spark-1.2.0-bin-hadoop2.3.tgz ,Scala版本是2.10.3,Zookeeper是3.4.6。这里需要注意的是,Spark和Scala有版本对应关系,可在Spark官网介绍中找到Spark版本支持的Scala版本。
3、JDK安装及环境变量设置
[hadoop@SY-0134 ~]$ mkdir lab
#我将jdk7安装在lab目录
[hadoop@SY-0134 jdk1.7.0_71]$ pwd
/home/hadoop/lab/jdk1.7.0_71
#环境变量设置:
[hadoop@SY-0134 ~]$ vi .bash_profile
# User specific environment and startup programs export JAVA_HOME=/home/hadoop/lab/jdk1.7.0_71 PATH=$JAVA_HOME/bin:$PATH:$HOME/bin export PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#设置生效
[hadoop@SY-0130 ~]$ source .bash_profile
4、Scala安装及环境变量设置
我将scala解压到/home/hadoop/labsp/scala-2.10.3位置。
修改.bash_profile文件
增加:export SCALA_HOME=/home/hadoop/labsp/scala-2.10.3
修改:PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$SCALA_HOME/bin
#设置生效
[hadoop@SY-0130 ~]$ source .bash_profile
检验Scala是否安装好:
[hadoop@SY-0134 ~]$ scala
Welcome to Scala version 2.10.3 (Java HotSpot(TM) Client VM, Java 1.7.0_71).
上述显示安装成功。
5、Spark安装及环境配置
我将spark解压到/home/hadoop/labsp/spark1.2_hadoop2.3位置。下载的这个包是预编译包。
修改.bash_profile文件
增加:export SPARK_HOME=/home/hadoop/labsp/spark1.2_hadoop2.3
修改:PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
#设置生效
[hadoop@SY-0130 ~]$ source .bash_profile
#修改spark-env.sh
[hadoop@SY-0134 conf]$ pwd
/home/hadoop/labsp/spark1.2_hadoop2.3/conf
[hadoop@SY-0134 conf]$vi spark-env.sh
核心配置:
export JAVA_HOME=/home/hadoop/lab/jdk1.7.0_71
export SCALA_HOME=/home/hadoop/labsp/scala-2.10.3
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=SY-0134:2181,SY-0130:2181,SY-0131:2181,SY-0132:2181,SY-0133:2181 -Dspark.deploy.zookeeper.dir=/spark"
至此JDK,Scala,Spark 安装及环境变量设置好,当然上述配置步骤也可一次修改完成。
6、Zookeeper安装
我将zookeeper解压到/home/hadoop/labsp/zookeeper-3.4.6位置。
#配置zoo.cfg文件
[hadoop@SY-0134 zookeeper-3.4.6]$ pwd
/home/hadoop/labsp/zookeeper-3.4.6
[hadoop@SY-0134 zookeeper-3.4.6]$ mkdir data
[hadoop@SY-0134 zookeeper-3.4.6]$ mkdir datalog
[hadoop@SY-0134 zookeeper-3.4.6]$ cd conf
[hadoop@SY-0134 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@SY-0134 conf]$ vi zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/hadoop/labsp/zookeeper-3.4.6/data dataLogDir=/home/hadoop/labsp/zookeeper-3.4.6/datalog # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=SY-0134:2888:3888 server.2=SY-0130:2888:3888 server.3=SY-0131:2888:3888 server.4=SY-0132:2888:3888 server.5=SY-0133:2888:3888
#配置myid文件
[hadoop@SY-0134 data]$ pwd
/home/hadoop/labsp/zookeeper-3.4.6/data
输入1进入SY-0134的zookeeper中的myid文件
echo "1"> home/hadoop/labsp/zookeeper-3.4.6/data/myid
7、SSH免密码登录
虽然在Hadoop集群中,SY-0130,能够免密码登录到SY-0131,SY-0132,SY-0133 。
但是在本次Spark集群中,Master为SY-0134 ,他需要能够免密码登录到SY-0130,SY-0131,SY-0132,SY-0133。
#我是先在SY-0134中,生成公钥。
[hadoop@SY-0134 ~]$ ssh-keygen -t rsa
[hadoop@SY-0134 ~]$ cd .ssh
[hadoop@SY-0134 .ssh]$ ls
id_rsa id_rsa.pub known_hosts
#将id_rsa.pub文件拷贝给SY-0130
[hadoop@SY-0134 .ssh]$ scp id_rsa.pub hadoop@SY-0130:~/.ssh/authorized_keys
#在SY-0130中,生成公钥。
[hadoop@SY-0130 ~]$ ssh-keygen -t rsa
[hadoop@SY-0130 ~]$ cd .ssh
[hadoop@SY-0130 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
#将id_rsa.pub文件的内容追加写入到authorized_keys中。稍微有点特殊。
[hadoop@SY-0130 .ssh]$ cat id_rsa.pub >>authorized_keys
#将SY-0130下的authorized_keys文件使用SCP命令复制到SY-0131,SY-0132,SY-0133 。
8、其他节点Spark,Scala, zookeeper安装
上述7步仅完成了SY-0134 ,Spark,Scala, Zookeeper的安装,须将三个安装文件目录SCP命令拷贝到SY-0130,SY-0131,SY-132,SY-0133目录,并且同样设置环境变量。
[hadoop@SY-0134 labsp]$ ls
scala-2.10.3 spark1.2_hadoop2.3 zookeeper-3.4.6
另外一点,Zoookeeper 的Server在不同节点上,myid文件内容不一样。
echo "1"> home/hadoop/labsp/zookeeper-3.4.6/data/myid #SY-0134
echo "2"> home/hadoop/labsp/zookeeper-3.4.6/data/myid #SY-0130
echo "3"> home/hadoop/labsp/zookeeper-3.4.6/data/myid #SY-0131
echo "4"> home/hadoop/labsp/zookeeper-3.4.6/data/myid #SY-0132
echo "5"> home/hadoop/labsp/zookeeper-3.4.6/data/myid #SY-0133
1、在5个节点上分别启动zookeeper .
[hadoop@SY-0134 zookeeper-3.4.6]$ bin/zkServer.sh start
[hadoop@SY-0130 zookeeper-3.4.6]$ bin/zkServer.sh start
[hadoop@SY-0131 zookeeper-3.4.6]$ bin/zkServer.sh start
[hadoop@SY-0132 zookeeper-3.4.6]$ bin/zkServer.sh start
[hadoop@SY-0133 zookeeper-3.4.6]$ bin/zkServer.sh start
2、在SY-0134启动 Spark Master
[hadoop@SY-0134 spark1.2_hadoop2.3]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/labsp/spark1.2_hadoop2.3/sbin/../logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-SY-0134.out SY-0133: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/labsp/spark1.2_hadoop2.3/sbin/../logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-SY-0133.out SY-0132: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/labsp/spark1.2_hadoop2.3/sbin/../logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-SY-0132.out SY-0131: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/labsp/spark1.2_hadoop2.3/sbin/../logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-SY-0131.out
3、在SY-0130启动 Standby Spark Master
[hadoop@SY-0130 spark1.2_hadoop2.3]$ sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /lab/labsp/spark1.2_hadoop2.3/sbin/../logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-SY-0130.out
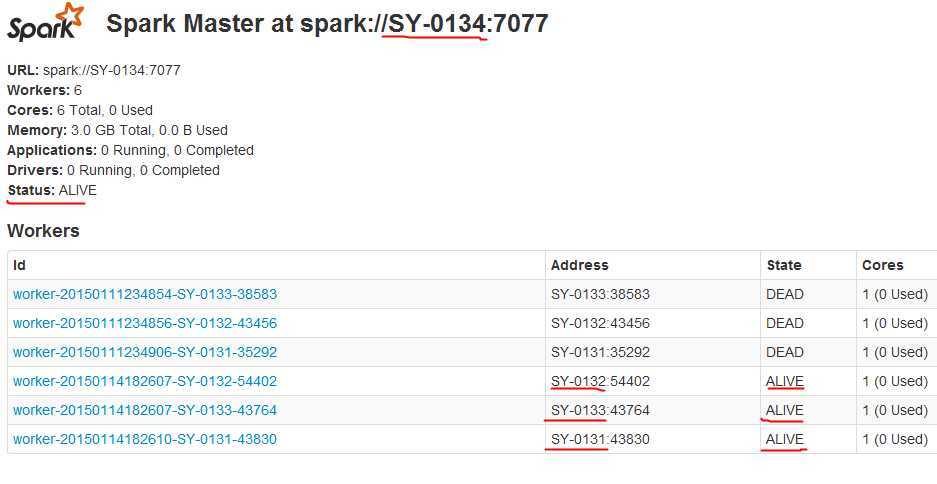
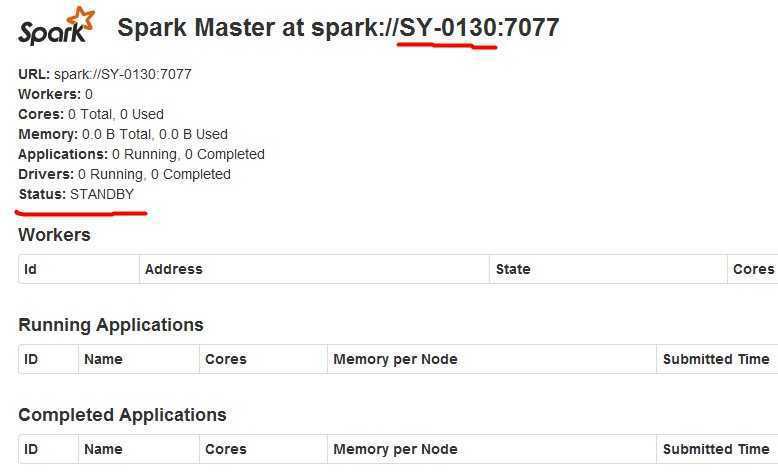
有了这样的实验环境,就可以继续深入学习Spark运行架构、SparkSQL等知识啦.
本博客文章除特别声明,全部都是原创!
可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明。
尊重原创,转载请注明: 转载自JackyKen (http://www.cnblogs.com/xiejin)
本文链接地址:《Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的》(http://www.cnblogs.com/xiejin/p/4213082.html)
Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的
标签:
原文地址:http://www.cnblogs.com/xiejin/p/4213082.html