一、PCA:
PCA是一种用来对图像特征降维的方法,PCA通过将多个变量通过线性变换以选出较少的重要变量。它往往可以有效地从过于“丰富”的数据信息中获取最重要的元素和结构,去除数据的噪音和冗余,将原来复杂的数据降维,揭示隐藏在复杂数据背后的简单结构。近年来,PCA方法被广泛地运用于计算机领域,如数据降维、图像有损压缩、特征追踪等等。PCA方法是一个高普适用方法,它的一大优点是能够对数据进行降维处理,我们通过PCA方法求出数据集的主元,选取最重要的部分,将其余的维数省去,从而达到降维和简化模型的目的,间接地对数据进行了压缩处理,同时很大程度上保留了原数据的信息,就如同人脑在感知神经处理时进行了降维处理。所以在机器学习和模式识别及计算机视觉领域,PCA方法被广泛的运用。
在人脸识别中,假设训练集是30幅不同的N×N大小的人脸图像。把图像中每一个像素看成是一维信息,那么一副图像就是N2维的向量。因为人脸的结构有极大的相似性,如果是同一个人脸的话相似性更大。而我们的所希望能够通过人脸来表达人脸,而非用像素来表达人脸。那么我们就可以用PCA方法对30幅训练集图像进行处理,寻找这些图像中的相似维度。我们提取出最重要的主成份后,让被识别图像与原图进行过变化后的主元维度进行相似度比较,以衡量两幅图片的相似性。
在图像压缩方面,我们还可以通过PCA方法进行图像压缩,又称Hotelling或者Karhunen and Leove变换。我们通过PCA提取出图像的主分量,去除掉一些次分量,然后变换回原图像空间,图像因为维数的降低得到了很大程度上的压缩,同时图像还很大程度上保留了原图像的重要信息。
算法实现:
1、获得图像的特征数据;
2、减去特征数据的均值:需要在每一个维度进行,即x = x-(x的均值),y = y - (y的均值);
3、计算协方差矩阵:
4、计算协方差矩阵的特征值和特征向量:有两种方法,一种是通过特征值分解来求,
5、将特征值从大到小排序,选择最大的前P个特征值对应的特征向量,组成一个特征向量。其中p可以选择特征总数的98%或者自己根据情况自己选择。
6、产生新的数据集:利用下式对原始数据进行转化,得到转化后的具有较低维度的数据。
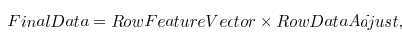
PCA融合特点:
PCA是一种与类别无关的降维方法,所以PCA是一种unsupervised learning。
二、LDA
LDA的全称是Linear Discriminant Analysis(线性判别分析),是一种supervised learning.有些资料上也称为是Fisher’s Linear Discriminant,因为它被Ronald Fisher发明自1936年,Discriminant这次词我个人的理解是,一个模型,不需要去通过概率的方法来训练、预测数据,比如说各种贝叶斯方法,就需要获取数据的先验、后验概率等等。LDA是在目前机器学习、数据挖掘领域经典且热门的一个算法,据我所知,百度的商务搜索部里面就用了不少这方面的算法。
LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。要说明白LDA,首先得弄明白线性分类器(Linear Classifier):因为LDA是一种线性分类器。对于K-分类的一个分类问题,会有K个线性函数:
![]()
当满足条件:对于所有的j,都有Yk > Yj,的时候,我们就说x属于类别k。对于每一个分类,都有一个公式去算一个分值,在所有的公式得到的分值中,找一个最大的,就是所属的分类了。
上式实际上就是一种投影,是将一个高维的点投影到一条高维的直线上,LDA最求的目标是,给出一个标注了类别的数据集,投影到了一条直线之后,能够使得点尽量的按类别区分开。

原文地址:http://www.cnblogs.com/jiangnanrain/p/3751333.html