标签:
介绍
K-means算法是是最经典的聚类算法之一,它的优美简单、快速高效被广泛使用。它是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
图示
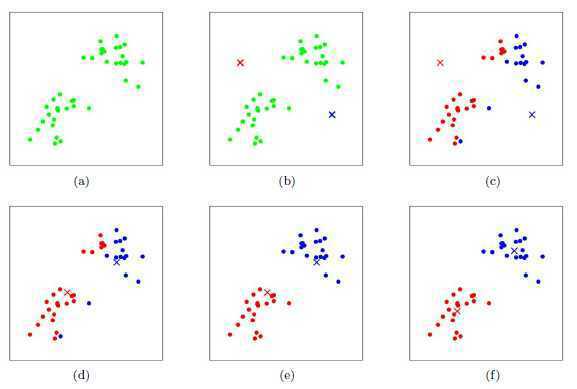
步骤
优点
缺点
改进
http://tech.ddvip.com/2013-12/1387352834207177.html
标签:
原文地址:http://www.cnblogs.com/kaituorensheng/p/3976053.html