标签:
参考引用文章地址:
http://hllvm.group.iteye.com/group/wiki/3053-JVM
http://blog.csdn.net/william001zs/article/details/6749946
推荐文章:http://www.cnblogs.com/gw811/archive/2012/10/18/2730117.html#undefined
1. 在新的线程创建时,JVM会为每个线程创建一个专属的栈(stack),其栈是先进后出的数据结构,这种方式的特点,让程序员编程时,必须特别注意递归方法
要尽量少使用,另外栈的大小也有一定的限制,如果过多的递归,容易导致stack overflow。
2. JVM的体系结构包含几个主要的子系统和内存区:
1). 类装载子系统 ,负责把类从文件系统中装入内存
2). GC子系统 ,垃圾收集器的主要工作室自动回收不再运行的程序引用对象所占用的内存,此外,它还可能负责那些还在使用的对象,以减少的堆碎片。
3). 内存区 ,用于存储字节码,程序运行时创建的对象,传递给方法的参数,返回值,局部变量和中间计算结果。
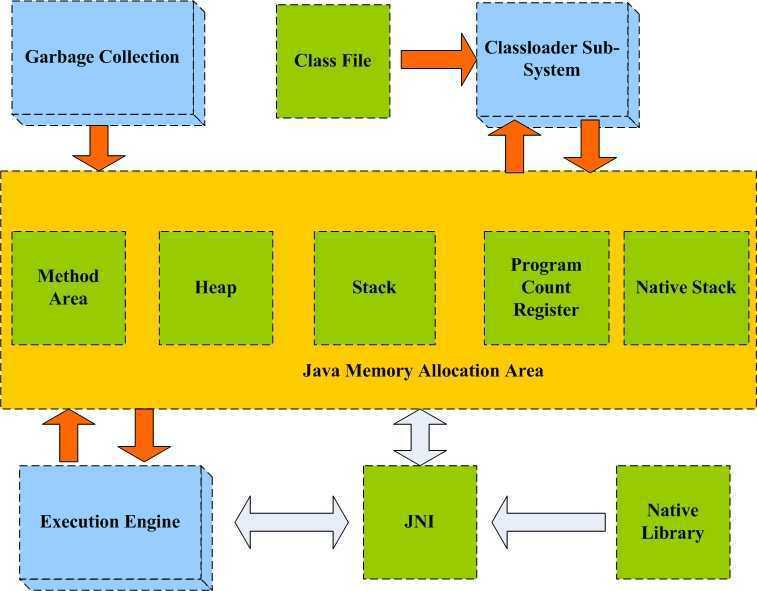
3. Java的内存分配
在Java程序运行过程中,JVM定义了各种区域用于存储运行时数据。其中的有些数据区域在JVM启动时创建,并只在JVM退出时销毁。其它的数据区域与每个线程
相关。这些数据区域,在线程创建时创建,在线程退出时销毁。
1). 程序计数器寄存器(The pc Register)
JVM支持多个线程同时运行。每个JVM都有自己的程序计数器。在任何一个点,每个JVM线程执行单个方法的代码,这个方法是线程的当前方法。如果方法不是
native的,程序计数器寄存器包含了当前执行的JVM指令的地址,如果方法是 native的,程序计数器寄存器的值不会被定义。 JVM的程序计数器寄存器的宽度足
够保证可以持有一个返回地址或者native的指针。
总的来说,程序计数器寄存器一块较小的内存,它的作用可以看作是当前线程锁执行的字节码的行号指示器。任一时刻一个处理器只会执行一条线程中的指令,为
了线程切换后能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器。
2). 栈
a). 栈与线程
JVM是基于栈的虚拟机.JVM为每个新创建的线程都分配一个栈.也就是说,对于一个Java程序来说,它的运行就是通过对栈的操作来完成的。栈以帧为单位保存线
程的状态。JVM对栈只进行两种操作:以帧为单位的压栈和出栈操作。
我们知道,某个线程正在执行的方法称为此线程的当前方法.我们可能不知道,当前方法使用的帧称为当前帧。当线程激活一个Java方法,JVM就会在线程的 Java堆栈
里新压入一个帧。这个帧自然成为了当前帧.在此方法执行期间,这个帧将用来保存参数,局部变量,中间计算过程和其他数据.这个帧在这里和编译原理中的活动纪录
的概念是差不多的.
从Java的这种分配机制来看,堆栈又可以这样理解:栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,
该区域具有先进后出的特性。
b). 栈中的方法调用,嵌套方法的出栈和入栈示意图:
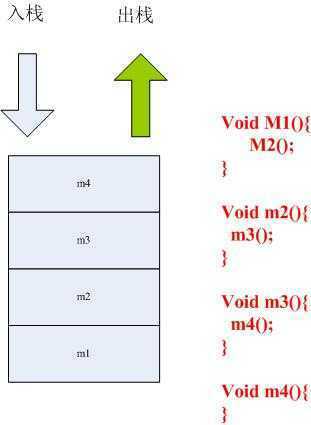
上图中描述了嵌套方法时,stack的内存分配图,由上面可以知道,当嵌套方法调用时,嵌套越深,stack的内存就越晚才能释放,因此,在实际
开发过程中,不推荐大家使用递归来进行方法的调用,递归很容易导致stack flow。
非嵌套方法的出栈入栈过程:
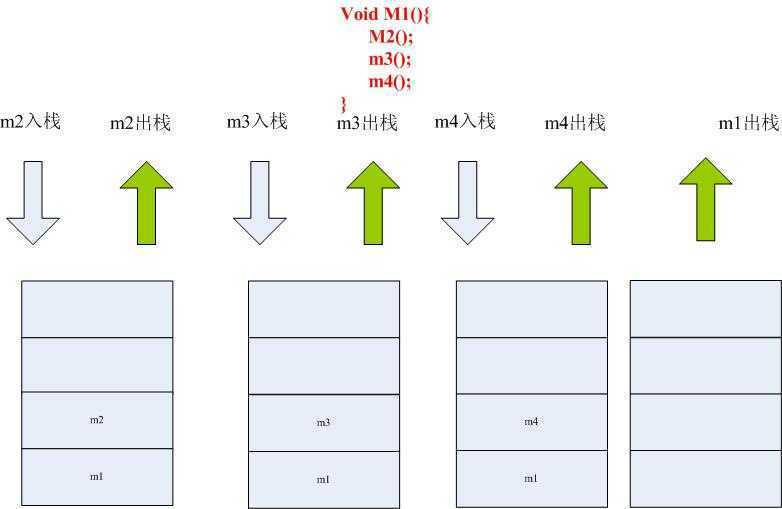
c). 与程序计数器一样,也是线程私有的,负责几乎局部变量表、操作栈、动态链接、方法出口等信息,每一个方法被调用直至执行完成的过程,就对应着
一个栈帧在虚拟机栈中入栈和出栈的过程(也称之为线程栈,线程栈分配的大小可以在jvm启动参数的-Xss中配置,当使用虚拟机默认参数时,栈深度
在大多数情况下达到1000-2000完全没有问题,线程栈的大小开大了,系统可生成的线程数就会相应减少),当线程请求的栈深入超过虚拟机所允许的
深度,将抛出StackOverFlowError异常,若虚拟机动态扩展后仍无法请求到足够的内存,则抛出OutOfMemoryError异常。
3). 堆
a). 每一个Java应用都唯一对应一个JVM实例,每一个实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或数组都放在这个堆中,并由应用所有的
线程共享.跟C/C++不同,Java中分配堆内存是自动初始化的。Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,
也就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
b). 专门存放Java对象的内存,是垃圾收集器管理的主要区域,也称为GC堆,其中又分为新生代和老年代,其大小由jvm启动参数来决定,
如–Xms 128m –Xmx 512m表示初始大小为128m,内存不足时可动态扩展,最多扩展到512m。
4). 方法区
a). JVM有一个被所有的线程共享方法区。方法区类似于传统语言的编译后代码的存储区,或者UNIX进程中的text段。它存储每个类结构例如常量池(constant pool),
成员字段域和方法和构造函数,包含类和实例初始化和接口类型类型中用到的特殊方法的代码。方法区在虚拟机启动时创建。尽管方法区在逻辑上时heap的一部分,
简单的实现仍然可以选择对它既不回收也不压缩。
b). 存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据,又叫Non-Heap(非堆),也有人称之为“永久代”(并不一定是“永久”存在的,
它也可能被垃圾收集器回收),可通过虚拟机的-XX:PermSize 和 -XX:MaxPermSize来限制大小。
5). 常量池
属于方法区的一部分,用于存放编译期生成的各种字面量和符号引用,如一些在运行时才生成的常量。
常量池在java用于保存在编译期已确定的,已编译的class文件中的一份数据。它包括了关于类,方法,接口等中的常量,也包括字符串常量,如String s = "java"这
种申明方式;当然也可扩充,执行器产生的常量也会放入常量池,故认为常量池是JVM的一块特殊的内存空间。(百度百科)
字符串池属于常量池的一部分。
6). 直接内存
不属于Java虚拟机管理的内存,一般是在使用NIO的时候分配的内存空间,可通过-XX:MaxDirectMemorySize指定,若不指定则默认使用-Xmx的大小。若虚拟机
的内存开辟过大,会导致直接内存的不足,而导致OutOfMemoryError的错误,这时候需要把Java虚拟机的内存占用调低
4. 栈和堆的比较:
栈的优势是,存取速度比堆要快 ,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享。堆的
优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
5. 有些分类中还有一种本地栈区,是用来存储本地方法(native)运行时数据的。
标签:
原文地址:http://www.cnblogs.com/Jtianlin/p/4231969.html