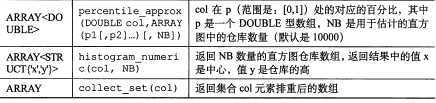
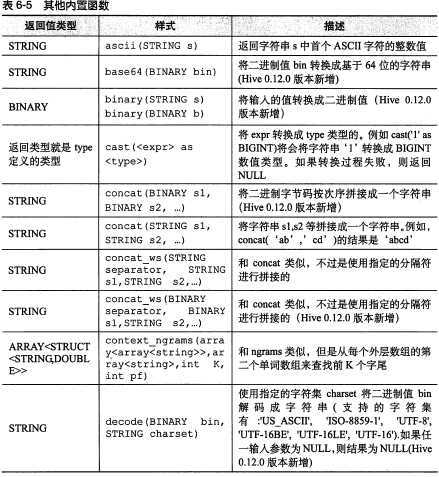
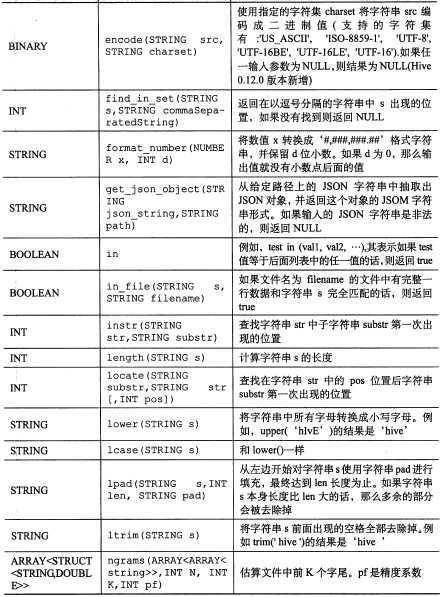
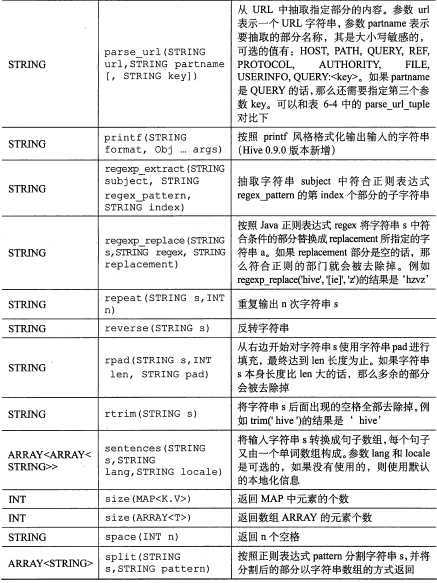
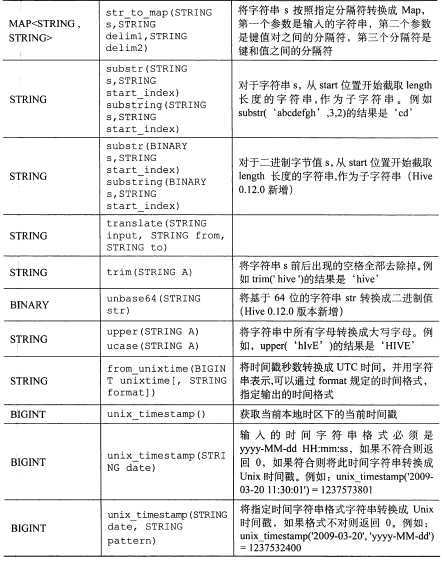
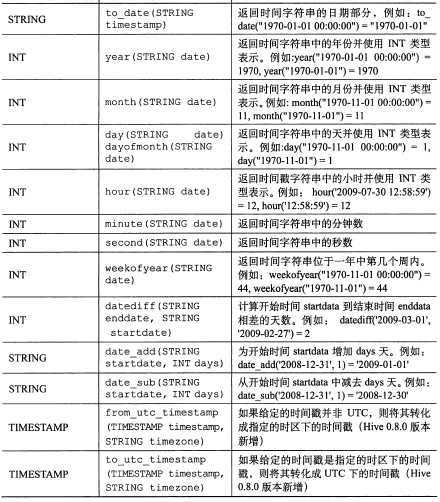
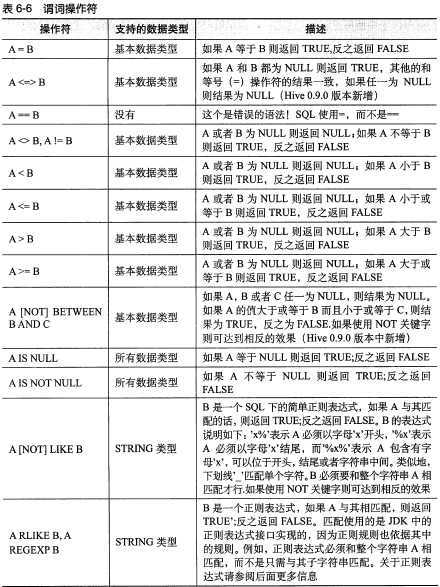
标签:
6.1 SELECT ... FROM 语句
hive> SELECT name,salary FROM employees; --普通查询
hive>SELECT e.name, e.salary FROM employees e; --也支持别名查询
当用户选择的列是集合数据类型时,Hive会使用 JSON 语法应用于输出:
hive> SELECT name,subordinates FROM employees; 显示 John Doe ["Mary Smith","Todd Jones"] 数组类型的显示
hive>SELECT name,deductions FROM employees; 显示 John Doe {"Federal Taxes":0.2,"State Taxes":0.05} MAP 输出
hive>SELECT name,adress FROM employees; 显示 John Doe {"street":"1 Michigan Ave.","city":"Chicago","state":"IL"} address 列是一个 STRUCT
hive> SELECT name,subordinates[0] FROM employees; 查看数组中的第1个元素,如果不存在元素将返回 NULL
hive>SELECT name,deductions["State Taxes"] FROM employees; 查询MAP 元素
hive>SELECT name,adress.city FROM employees; 查询STRUCT 中的一个元素,可以用 . 符号
以上三种查询 在 where 子句中同样可以使用这些方式;
hive>SELECT symbol, `price.*` FROM stocks; 用正则表达戒严 选择我们想要的列,本句是查 symbol 列和所有列名以 price 作为前缀的列;
hive>SELECT upper(name), salary, deductions["Federal Taxes"], round(salary * (1 - deductions["Federal Taxes"])) FROM employees; 使用 round() 方法返回一个 Double 类型的最近整数。
Hive 中所支持的运算符:
A + B 、A - B、A * B、A / B、A % B [求余]、A & B [按位与]、A | B [按位或]、A ^ B [按位取异或]、~A [按位取反]
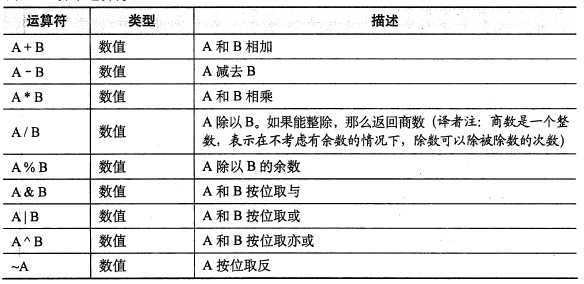

【图片取自《hive编程指南》 81页】
注意:算术运算符接受任意的数值类型,不过,如果数据类型不同,那么两种类型中值范围较小的那个数据类型转换为其他范围更广的数据类型。
当进行算术运算时,用户需要注意数据溢出或数据下溢问题,Hive 遵循的是底层 Java 中数据类型的规则,因为当溢出或下溢发生时计算结果不会自动转换为更广泛的数据类型,乘法和除法最有可能会引发这个问题;
有时使用函数将数据值按比例从一个范围缩放到另一个范围也是很有用的,如 按照 10 次方幂进行除法运算或取 log 值等。
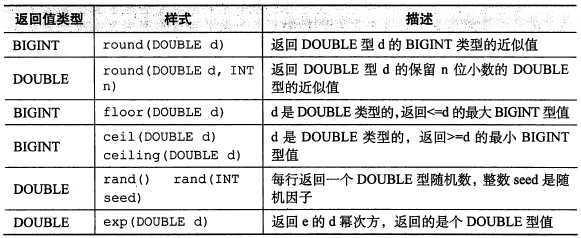
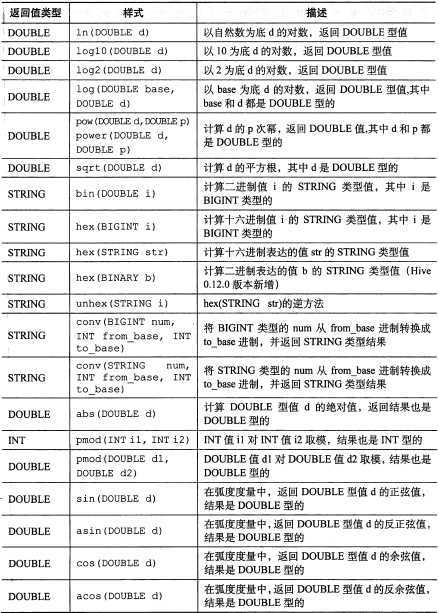
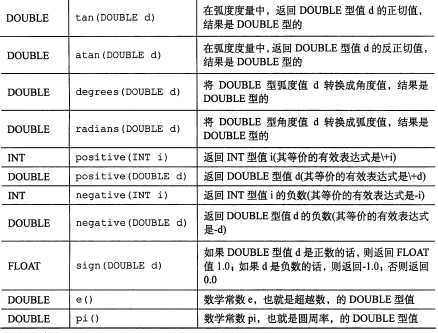
所有数学函数:

【图片取自《hive编程指南》 82页】
需要注意的是函数 floor、round、ceil (向上取整)输入的是 DOUBLE 类型的值,返回的值是 BIGINT 类型的。
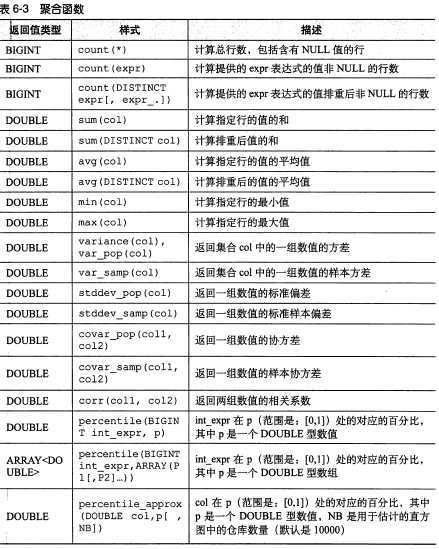
所有聚合函数:
【图片取自《hive编程指南》 85页】
hive> SET hive.map.aggr=true; --设置这个属性为 true 来提高聚合的性能
hive>SELECT count(*), avg(salary) FROM employees; --这个设置会触发在 map 阶段进行的“顶级”聚合过程,(非顶级聚合过程将会在执行一个 GROUP BY 后进行),不过这个设置将需要更多的内存。
hive>SELECT count(DISTINCT symbol) FROM stocks; 多个函数还可以接受像 DISTINCT 这个表达式,来进行排重;v如果 symbol 是分区列时会返回 0.。。。是个bug;
hive>SELECT count(DISTINCT ymd), count(DISTINCT volume) FROM stocks; 官方不允许这样查,但实际可以这样查;
表生成函数:与聚合函数相反的一类函数不是所谓的表生成函数,基可以将单列扩展成多列或者多行;
hive> SELECT explode (subordinates) AS sub FROM employees; 本语句将 employees 表中每行记录中 subordinates 字段内容转换成 0 个或者多个新的记录行,如果 subordinates 字段内容为空的话,那么将不会产生新的记录,如果不为空的话,那么这个数组的每个元素都将产生一行新记录;AS sub 子句定义了列别名 sub。当全用表生成函数时,Hive 要求使用列别名。【具体在13章中会详细介绍】
表生成函数:
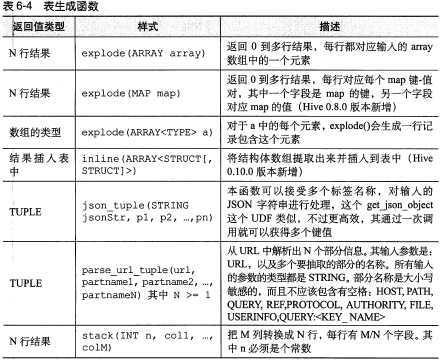
【图片取自《hive编程指南》 88-92页】
hive> SELECT upper(name), salary, deductions["Federal Taxes"], round(salary *(1 - deductions["Federal Taxes"])) FROM employees LIMIT 2;
LIMIT 子句用于限制返回的行数;
hive> SELECT upper(name), salary, deductions["Federal Taxes"] as fed_taxes, round(salary *(1 - deductions["Federal Taxes"])) as salary_minus_fed FROM employees LIMIT 2; fed_taxes、 salary_minus_fed 给新查出的结果的两个列起个别名;
hive> FROM (upper(name), salary, deductions["Federal Taxes"] as fed_taxes, round(salary *(1 - deductions["Federal Taxes"])) as salary_minus_fed FROM employees) e SELECT e.name, e.salary_minus_fed_taxes WHERE e.salary_minus_fed_taxes >7000; SELECT 的嵌套查询
CASE ... WHEN ... THEN 句式例子:
hive>SELECT name,salary, CASE
WHEN salary < 5000 THEN ‘low‘
WHEN salary >= 5000 AND salary <7000 THEN ‘middle‘
WHEN salary>=7000 AND salary < 100000 THEN ‘high‘
ELSE ‘very high‘ END AS bracket FROM employees;
Hive 大多数情况下查询都会触发一个 MapReduce 任务,Hive 中本模式的查询可以不必使用 MP;如: select * from employees;
SELECT * from employees WHERE country=‘us‘ and state=‘ca‘ limit 100; 对于 WHERE 语句中过滤条件只是分区字段这种情况(无论是否使用了 LIMT语句限制输出记录条数)也是无需MapReduce 过程的;
hive.exec.mode.local.auto=true; 如果这个值为 true Hive 还会尝试使用本地模式执行其他的操作,否则 Hive 会用 MP 来执行其他所有的查询;最好将它增加到 $HOME/.hiverc 文件中;
6.2 where 语句用于过滤查询条件 用法与 普通 SQL 一样;
谓词操作:这些词的操作同样可以用于 JION ... ON 和 HAVING 语句中
【图片取自《hive编程指南》 88-92页】
LIke 和 RLIKE :LIKE是一个标准的 SQL 操作,可以让我们通过字符串的开头或结尾,以及指定特定的子字符串,或者当子字符串出现在字符串内的任何位置时进行匹配;【RLIKE 子句是 Hive中这个功能的一个扩展,其可以通过 JAVA 的正则表达式这个更强大的语言来指定匹配条件。】
hive>SELECT name, address.street FROM employees WHERE address.street LIKE ‘%Ave.‘ --查找以Ave 开头的 雇员姓名;
hive>SELECT name, address.stree FROM employees WHERE address.street RLIKE ‘.*(Chicago|Ontario).*‘; --RLIKE 后面字符串含义:字符串中的 . 表示和任意的字符匹配,星号 * 表示重复“左边的字符串”零次到无数次,表达式(x|y)表示 和 x 或者 y 匹配;【PS:不会正则的可以百度一下去学学】
6.3 GROUP BY 语句,它通常会用 聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组执行聚合操作【用法与SQL差不多】
hive>SELECT year(ymd),avg(price_close) FROM stocks WHERE exchange=‘NASDAQ‘ AND symbol =‘APPLE‘ GROUP BY year(ymd); --示例
HAVING 语句:
hive>SELECT year(ymd),avg(price_close) FROM stocks
>WHERE exchange=‘NASDAQ‘ AND symbol =‘APPLE‘ GROUP BY year(ymd)
>HAVING avg(price_close)>50.0; --示例
6.4 JOIN 语句
INNER JOIN 内链接,只有进行链接的两个表中都存在与连接标准相关匹配的数据才会显示【用法与SQL差不多】
hive>SELECT a.ymd, a.price_close, b.price_close FROM stocks a JOIN STOCKS b ON a.ymd =b.ymd
>WHERE a.symbol =‘appl‘ AND b.symbol=‘ibm‘;
注意:hive 中不支持的查询如下【同进也不支持在ON的子句中的谓词间使用 OR,可以支持 AND 】:
hive>SELECT a.ymd, a.price_close, b.price_close FROM stocks a JOIN STOCKS b ON a.ymd<=b.ymd
>WHERE a.symbol =‘appl‘ AND b.symbol=‘ibm‘;
多张表的链接:
hive>SELECT a.ymd, a.price_close, b.price_close,c.price_close
> FROM stocks a JOIN stocks b ON a.ymd=b.ymd
> JOIN stocks c ON a.ymd = c.ymd
>WHERE a.symbol =‘appl‘ AND b.symbol=‘ibm‘ AND c.symbol=‘ge‘;
大多数情况下,Hive 会对每个 JOIN 链接对象启动一个 MapReduce 任务,上面例子中会首先启动一个 MapReduce job 对表 a 和表 b 进行连接操作,然后会再启动一个 MapReduce job 将第一个 MapReduce job 的输出和和 c 进行连接操作;【hive 都是从左向右运顺序执行的】
【提示】
对于3个或者更多表进行 JOIN 链接时,如果每个 ON 子句都使用相同的链接键的话,那么只会产生一个 MapReduce;Hive 同时假定查询中最后一个表是最大的那个表,在对每行记录进行链接操时,它会尝将其他表缓存起来,然后扫描最后那个大表进计算,因此我们需要保证连续查询中的表的大小从左到右是依次增加的;
LEFT OUTER JOIN 左外链接【与SQL用法类似】
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend FROM stocks s LEFT OUTER JION dividends d ON
>s.ydm AND s.symbol=d.symbol WHERE s.symbol=‘aapl‘ ;
在左外链接操作中, JOIN 操作符左边表中符合 WHERE 子句的所有记录将会被返回,右边表中没有符合 ON 后面的链接记录时,会返回 null;
【提示】WHERE 语句在连接操作执行后才会执行,因此 WHERE 语句应该只用于过滤那些非null值的列,同时,ON 语句中的分区过滤条件外链接(OUTER JOIN)中是无效的,不过在内链接中是有效的;
RIGHT OUTER JOIN 右外链接:会返回右边表所有符合 WHERE 语句的记录,左表中没有匹配的字段值用 NULL 代替;
FULL OUTER JOIN 完全链接:将会返回所有表中符合 where 语句条件的所有记录;
LEFT SEMI JOIN 左半开链接:会返回左边表的记录,前提是其他记录对于右边表满足ON语句中的判断条件;【不支持右关开链接】
hive>SELECT s.ymd, s.symbol, s.price_close FROM stocks s LEFT SEMI JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol;
Hive 不支持的查询:
hive>SELECT s.ymd, s.symbol, s.price_close FROM stocks s WHERE s.ymd,s.symbol IN(SELECT * FROM dividends d);
JOIN 笛卡尔积:左边链接的行数乘以右边表的行数等于返回结果集的大小;
hive> SELECT * FROM stocks JOIN dividends;
如果使用此方法查询,MapReduce 任何方式都无法法进行优化;
set hive.mapred.mode=strict 会禁止 笛卡尔积的查询;
map-side JOIN:如果所有表中只有一张表是小表,那么可以在最大的表通过 mapper 的时候将小表完全放到内存中,Hive可以在 map 端执行链接过程(称为 map-side JOIN); 因为 Hive 可以和内存中的小表进行逐一匹配,从而省略掉常规连接操作所需要的 reduce 过程 ,即使对于很小的数据庥,这个优化也明显要快于常规的连接操作,不仅减少了 reduce 过程 ,而且有时还可以同时减少 map 过程的执行步骤;
hive>set hive.auto.conver.JOIN=true; 从0.7版本开始需要设置此属性才可以生效
hive>set hive.mapjoin.smalltable.filesize=25000000; 配置能够使用这个优化的小表的大小;(单位:字节)
右外链接、全外链接不支持上面的优化;
分桶表,对于大表,在特定的情况下也可以使用这个优化,但表中的数据必须是按照ON 语句中的键进行分桶的,而且其中一张表的分桶的个数必须是另一张表分桶个数的若干倍,这样才可以按照分桶数据进行链接;hive>set hive.optimize.bucketmapJOIN=true; 也需要设置,默认是关闭的;
6.5 ORDER BY 和 SORT BY P132
Hive 的 ORDER BY 语句和其他的 SQL 语言的定义都是一样。会对查询结果一个全局排序。也就是说会有一个所有的数据都通过一个 reducer 进行处理的过程,如果有大数据集,过程可能会消耗太过漫长的时间来执行;
Hive 还有一种排序 SORT BY ,其会在每个 reducer 中对数据进行排序,也就是会执行一个局部排序过程 ,这可以保证每个 reducer 的输出数据都是有序的(但不是全局有序)这样可以提高全局排序的效率;
SELECT s.ymd, s.symbol, s.price_close FROM stocks s ORDER BY s.ymd ASC , s.symbol DESC; order by 例子
SELECT s.ymd, s.symbol, s.price_close FROM stocks s SORT BY s.ymd ASC , s.symbol DESC; sort by 例子
注意:因为 ORDER BY 操作可能会导致运行时间过长,如果属性 hvie.mapred.mode=strict 的话,那么 hive 要求这样的语句必须加 LIMIT 语句进行限制,默认情况下 属性是 nonstrict;
6.6 SORT BY 与 DISTRIBUTE BY
distribute by 控制 map 的输出在 reducer 中是如何划分的。
假设我们希望具有相同股票交易码的数据在一起处理,那么我们可以使用 distribute by 来保证具有相同股票交易码的记录会分发到同一个 reducer 中进行处理,然后使用 SOTR BY 来按照我们的期望对数据进行排序:
hive>SELECT s.ymd, s.symbol, s.price_close FROM stocks s DISTRIBUTE BY s.symbol SORT BY s.symbol ASC, s.ymd ASC;
DISTRIBUTE BY 和 GROUP BY 在其控制着 reducer 是如何接受一行行数据进行处理这方面类似类的,而 SORT BY 则控制着 reducer 内的数据是如何进行排序的。需要注意的是 DISTRIBUTE BY 语句一定要写在 SOTR BY 语句之前;
6.7 CLUSTER BY
在上面的例子中 s.symbol 列被用在 DISTRIBUTE BY 语句中,而 s.symbol 和 s.ymd 位用 SOTR BY 语句中,如果这两个语句中涉及到的完全相同的列,而且采用的是升序的排序方式(也就是默认的排序方式)在这种情况下 cluster by 就等于前面的2个语句 ,相当于简写:
hive> SELECT s.ymd, s.symbol, s.price_close FROM stock s CLUSTER BY s.symbol;
使用 DISTRIBUTE BY ... SOTR BY 语句或其简化版的 CLUSTER BY 语句会剥夺 SORT BY 的并行性,然而这样可以实现输出文件的数据是全局排序的;
6.8 类型转换
SELECT name, salary FROM employees WHERE cast(salary AS FLOAT )< 10000.0 ; 类型转换的语法: cast(value AS TYPE) 如果不成功则返回 NULL;
需要注意的是 将浮点数转换成整数的推荐方式是使用 round() 或者 floor() 函数,而不是类型转换操作符 cast;
binary 类型只支持 BINARY 类型转换为 STRING 类型;
6.9 抽样查询:
Hive 可以通过对表进行分桶抽样来满足抽样查询
hive>SELECT * FOM numbers TABLESAMPLE (BUCKET 3 OUT OF 10 ON rand()) s; 分桶语句中的分母表示的是数据将会被散列的桶的个数,而分子表示将会选择的桶的个数;
hive>SELECT * FROM numberflat TABLESAMPLE(0.1 PERCENT) s; 按照百分比方式进行抽样,这种是基于行数的;
注意:这种抽样试不一定适用于所遥 文件格式,另外这种抽样方式的最小抽样单元是一个 HDFS 数据块,如果表的数据大小小于普通的块大小的 128M 那么会返回 所有行;
基于百分比的抽样提供了一个变量用于控制基于数据块的调优的种子信息:
<property>
<name>hive.sample.seednumber</name>
<value>0</value>
</property>
6.10 UNION ALL
可以将2 个或多个表进行合并,每个 union 子查询必须都需要有相同的列,而且对应的每个字段的字段类型必须是一致的;这个功能便于将一个长的复杂的 WHERE 语句分割成 2 个或多个 union 子查询,除非源表建立了索,否则 这个查询将会对同一份源数据进行多次拷贝分发;
FROM (FROM src SELECT src.key, src,value WHERE src.key <100
UNION ALL
FROM src SELECT src.key, src,value WHERE src.key >110
) unioninput
INSERT OVERWRITE DIRECTORY ‘/tmp/union.out‘ SELECT unionimput.*
Hive[6] HiveQL 查询
标签:
原文地址:http://www.cnblogs.com/jiuyi/p/4232452.html