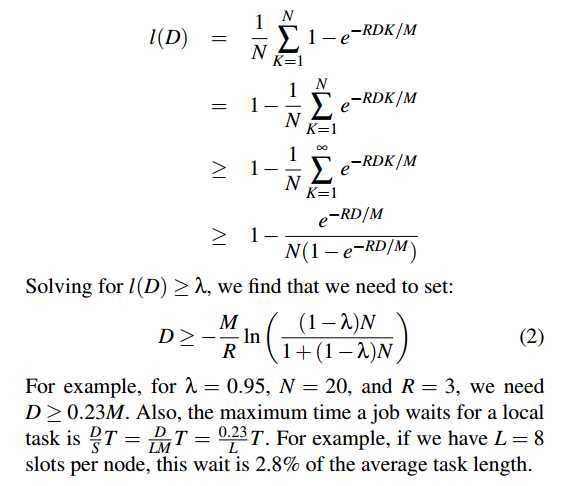标签:
Abstract
delay scheduling: when the job that should be scheduled next according to fairness cannot launch a local task, it waits for a small amount of time, letting other jobs launch tasks instead.
当调度器调度到一个task运行,但是这个task无法创建一个本地task,那这个task就等待一小段时间,让其他task先执行。
1. Introduction
HFS has two main goals:
- Fair sharing: divide resources using max-min fair sharing [7] to achieve statistical multiplexing
- Data locality: place computations near their input data, to maximize system throughput
At a high level, two approaches can be taken:
1. Kill running tasks to make room for the new job.
2. Wait for running tasks to finish
HDFS的HFS调度器有两个功能,提供基于统计和最大最小值的公平调度,同时将计算放在离数据近的地方。为了达到公平,在创建新任务时,调度器可以选择
1)停止一个整整执行的task,腾出资源;
2)等待足够资源后执行。 前者浪费了被停止的task的(已完成那部分)的工作,而后者难以保证公平。
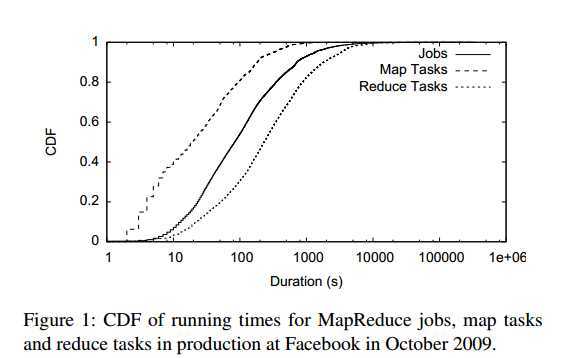
Our principal result in this paper is that, counterintuitively, an algorithm based on waiting can achieve both high fairness and high data locality. We show first that in large clusters, tasks finish at such a high rate that resources can be reassigned to new jobs on a timescale much smaller than job durations. However, a strict implementation of fair sharing compromises locality, because the job to be scheduled next according to fairness might not have data on the nodes that are currently free. To resolve this problem, we relax fairness slightly through a simple algorithm called delay scheduling, in which a job waits for a limited amount of time for a scheduling opportunity on a node that has data for it. We show that a very small amount of waiting is enough to bring locality close to 100%. Delay scheduling performs well in typical Hadoop workloads because Hadoop tasks are short relative to jobs, and because there are multiple locations where a task can run to access each data block
2. Background
Users submit jobs consisting of a map function and a reduce function. Hadoop breaks each job into tasks. First, map tasks process each input block (typically 64 MB) and produce intermediate results, which are key-value pairs. There is one map task per input block. Next, reduce tasks pass the list of intermediate values for each key and through the user’s reduce function, producing the job’s final output.
Job scheduling in Hadoop is performed by a master, which manages a number of slaves. Each slave has a fixed number of map slots and reduce slots in which it can run tasks. Typically, administrators set the number of slots to one or two per core. The master assigns tasks in response to heartbeats sent by slaves every few seconds, which report the number of free map and reduce slots on the slave.
Hadoop’s default scheduler runs jobs in FIFO order, with five priority levels. When the scheduler receives a heartbeat indicating that a map or reduce slot is free, it scans through jobs in order of priority and submit time to find one with a task of the required type. For maps, Hadoop uses a locality optimization as in Google’s MapReduce [18]: after selecting a job, the scheduler greedily picks the map task in the job with data closest to the slave (on the same node if possible, otherwise on the same rack, or finally on a remote rack)
hadoop将job拆分为task。每个map task处理一个block,并产生K-V形式的中间文件;reduce task中间文件的每一个key传给用户的reduce函数,并产生输出文件。
hadoop的调度在master进行,每个slave有定的map-slot和reduce-slot资源可以用来执行task;
slave每隔几秒通过心跳消息告诉master自己有多少空闲的slot,master根据这些信息进行调度分配task到slave上执行。
hadoop模式是FIFO调度,且区分了5个优先级别,不同优先级间是严格优先级调度。
默认的本地化优化方法,使用了谷歌论文的算法:每次调度到一个job后,用贪心法选择离数据最近的slave执行。
3. Delay Scheduling
1. How should resources be reassigned to new jobs?
We show that waiting imposes little impact on job response times when jobs are longer than the average task length and when a cluster is shared between many users
等待几乎不影响响应时间。
2. How should data locality be achieved?
We propose an algorithm called delay scheduling that temporarily relaxes fairness to improve locality by asking jobs to wait for a scheduling opportunity on a node with local data
为得到本地化的slave,等待有限的时间
3.1 Na?ve Fair Sharing Algorithm 原始的公平调度算法
3.2 Scheduling Responsiveness
假设一个job j需要F个slot,且这个job独立执行时需要J秒; 假设每个task平均耗时T秒,且集群有S个slot,那么
等待一个slot平均耗时T/S, job j需要等待FT/S。如果要求相比于job的运行时间J是可以忽略的, 需要满足
J>>FT/S.
只要下面条件之一满足,等待就不会影响响应时间:
- 有很多的job;
- 很小的job(执行时间短)
- 很长的job(执行时间远大于它的task)
3.3 Locality Problems with Na?ve Fair Sharing
Running on a node that contains the data (node locality) is most efficient, but when this is not possible, running on the same rack (rack locality) is faster than running off-rack.
在包含数据的节点上执行task效率最高;其次是数据在同一机架的其他机器上。
3.3.1 Head-of-line Scheduling
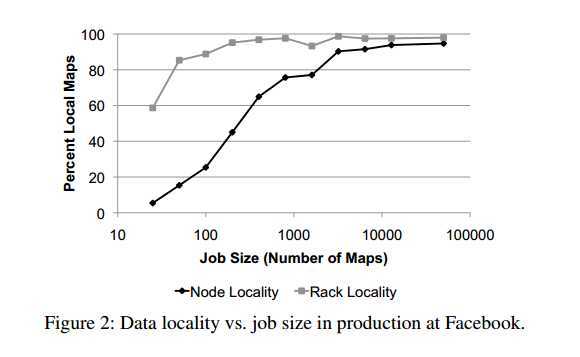
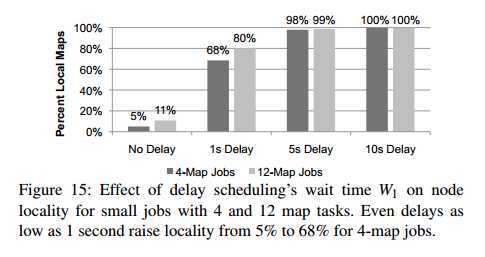
If the head-of-line job is small, it is unlikely to have data on the node that is given to it. For example, a job with data on
10% of nodes will only achieve 10% locality
如果执行的都是小的task,那么很难达到本地化效果。
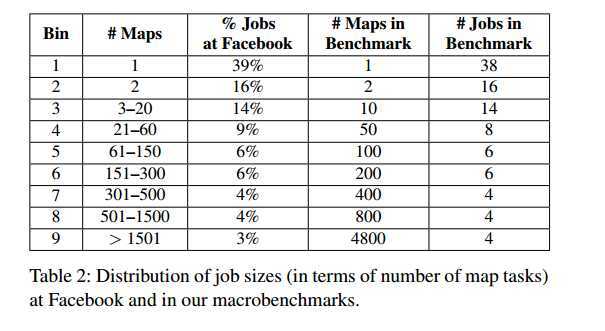
在facebook, 包含1到25个map 的job站大部分的比例。但是他们的节点本地化只有5%,机架本地化只有59%。
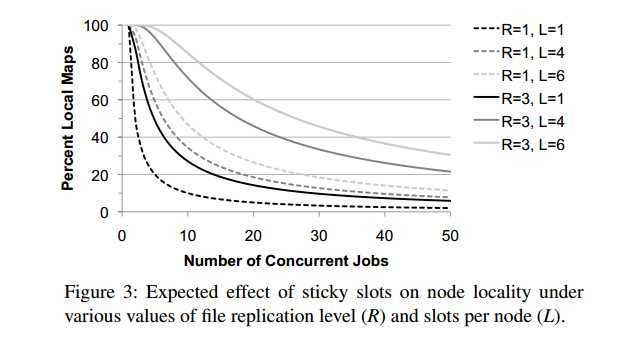
3.3.2 Sticky Slots
slot粘性是指一个job的task始终在同一个slot执行,即使它的本地化情况不是最优的,也难以摆脱(从而去找到更优的slot)。
3.4 Delay Scheduling
3.5 Analysis of Delay Scheduling
如何选择延时D的大小?
1. Non-locality decreases exponentially with D.
非本地化比例随延时增大而以指数行下降低。
2. The amount of waiting required to achieve a given level of locality is a fraction of the average task length and decreases linearly with the number of slots per node L
We first consider how much locality improves depending on D?
为了达到某个本地化程度,总共的等待时间与task的平局长度成正比(协变更准确);与每个节点上slot数成反比(逆变更准确)。
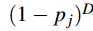 exponentially with D
exponentially with DA second question is how long a job waits below its fair share to launch a local task?
in our experiments, local tasks ran up to 2x faster than non-local tasks.
3.5.1 Long Tasks and Hotspots
4. Hadoop Fair Scheduler Design
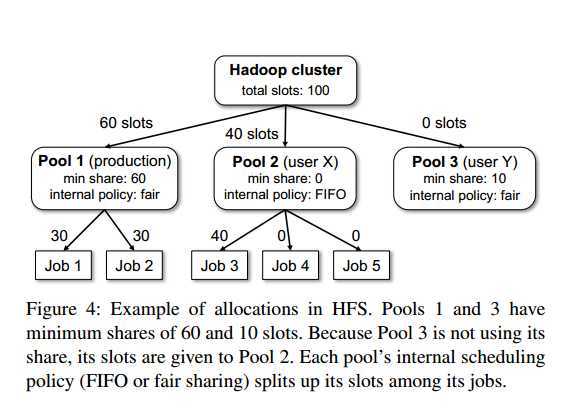
1. 只要一个pool有task,至少保证它有min数量的slot;
2. 允许kill长任务:
First, each pool has a minimum share timeout, T-min。每个pool有最小资源保证时间T-min,当超过T-min时,会kill其他任务来满足这个最小的资源需求。
Second, there is a global fair share timeout, T-fair , used to kill tasks if a pool is being starved of its fair share.
如果一个pool饿死状态超过T-fair,将kill任务来释放资源。
T-min应该基于应用的服务级别设置,而T-fair应该基于应用能容忍的最大超时设置。
4.1 Task Assignment in HFS
First, we create a sorted list of jobs according to our hierarchical scheduling policy. Second, we scan down this list to find a job to launch a task from, applying delay scheduling to skip jobs that do not have data on the node being assigned for a limited time. The same algorithm is applied independently for map slots and reduce slots although we do not use delay scheduling for reduces because they usually need to read data from all nodes.
当有一个slot是空闲的,HDFS按如下步骤分配
1)将jobs按照调度层级和策略排序;
2)使用延时调度算法扫描排好序的jobs,选出一个job来执行。
另外,map和reduce独立地使用相同的调度算法,但是reduce不使用延时调度,因为reduce通常需要从所有节点读取数据。
4.1 Task Assignment in HFS
We expect administrators to set the wait times W1 and W2 based on the rate at which slots free up in their cluster and the desired level of locality, using the analysis in Section 3.5.
configured with a block size of 128 MB because this improved performance (Facebook uses this setting in production).
在facebook,使用128M的块大小性能更好。
5. Evaluation
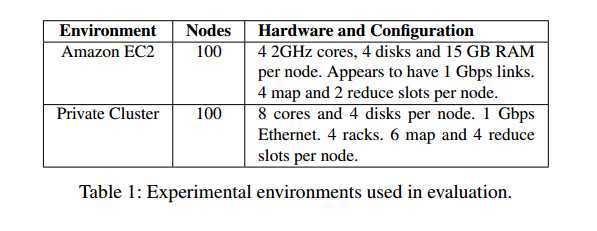

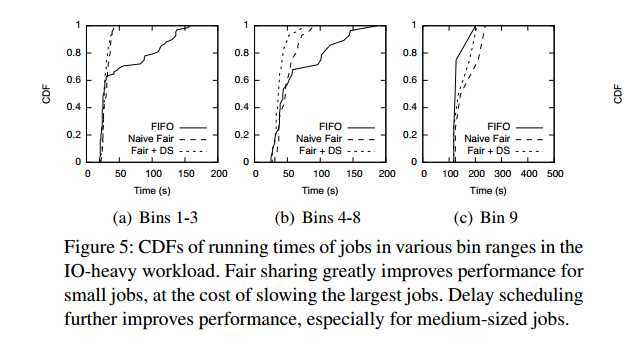
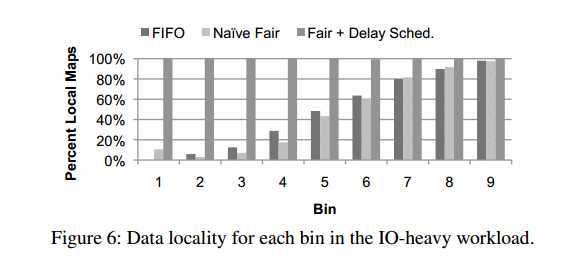
5.1.1 Results for IO-Heavy Workload
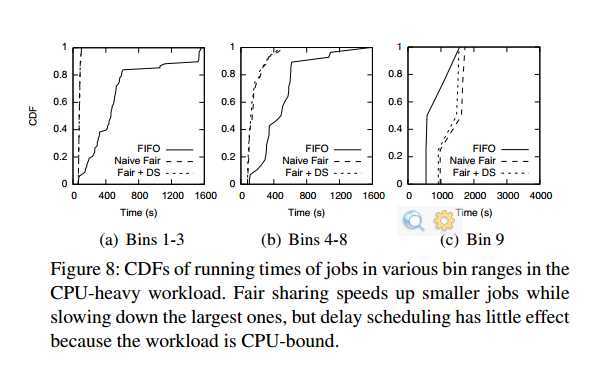
5.1.2 Results for CPU-Heavy Workload
We note two behaviors:
First, fair sharing improves response times of small jobs as before, but its effect is much larger (speeding some jobs as much as 20x), because the cluster is more heavily loaded (we are running on the same data but with more expensive jobs).
Second, delay scheduling has a negligible effect, because the workload is CPU-bound, but it also does not hurt performance.
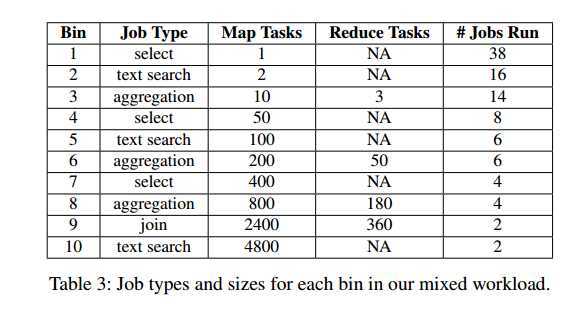
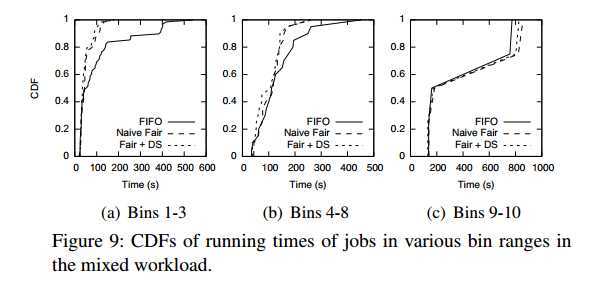
5.1.3 Results for Mixed Workload
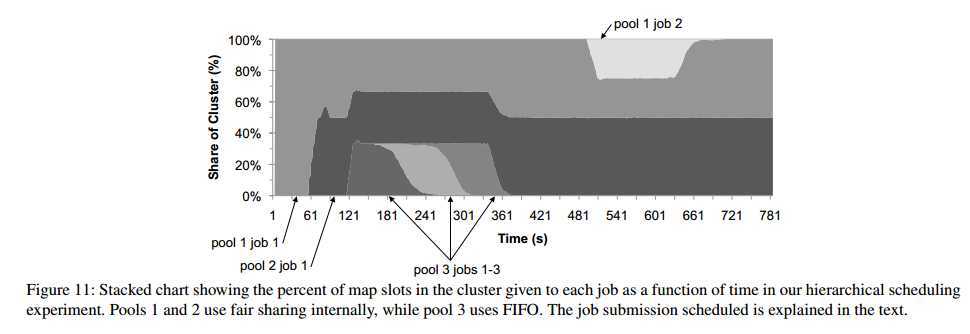
5.2.1 Hierarchical Scheduling
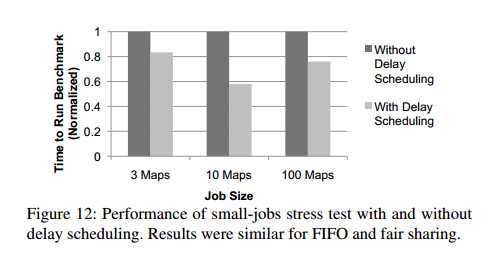
5.2.2 Delay Scheduling with Small Jobs
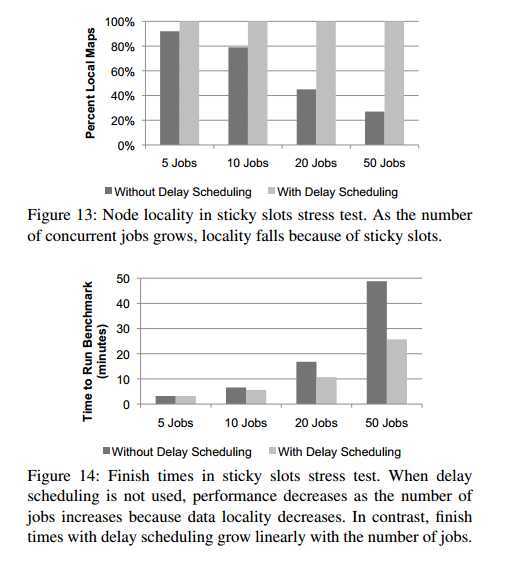
5.2.3 Delay Scheduling with Sticky Slots
5.3 Sensitivity Analysis
6. Discussion
Two key aspects of the cluster environment enable delay scheduling to perform well: 两个前提条件:
- first, most tasks are short compared to jobs, and
- second, there are multiple locations in which a task can run to read a given data block, because systems like Hadoop support multiple task slots per node
Because delay scheduling only involves being able to skip jobs in a sorted order that captures “who should be scheduled next,” we believe that it can be used in a variety of environments beyond Hadoop and HFS 其他使用场景:
- Scheduling Policies other than Fair Sharing 其他调度策略,不局限于公平调度
- Scheduling Preferences other than Data Locality 其他优先偏好,不局限于本地化
- Load Management Mechanisms other than Slots 其他资源管理机制,不局限于slot
- Distributed Scheduling Decisions 分布式调度,不局限于单个调度器
spark 笔记 3:Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling
标签:
原文地址:http://www.cnblogs.com/zwCHAN/p/4235129.html