标签:
今天看了一篇 ECML 14 的文章(如题),记录一下。
原文链接:http://link.springer.com/chapter/10.1007/978-3-662-44848-9_38
这篇文章提出了一个显式考虑 x 与 y 之间的相关性的 lasso 算法。
方法很简单,就是用 μj=(1 - |rho(aj, y)|)2 作为回归系数 βj 的惩罚系数。
如下图:
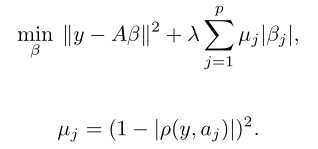
所以每个回归系数的惩罚都不同,与 y 相关性越大的变量,惩罚系数 μj 就越小,相应的 βj 就越不可能为 0。
这篇文章的主要贡献在于给出了一个高效的迭代算法,并证明了其收敛性
(注意,这是一个凸问题,所以如果收敛则一定会收敛到全局最优)。
算法的初始化是对应 ridge regression 的解。
迭代就两步,如下图

算法的收敛性:证明了目标函数是非增的(non-increasing),即 L(α(t+1)) ≤ L(α(t)) 。
先证明了两个引理。
第一个引理定义了一个辅助函数
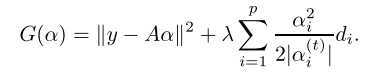
并证明 G(α(t+1)) ≤ G(α(t))。
第二个引理证明 L(α(t+1)) - L(α(t)) ≤ G(α(t+1)) - G(α(t)).
结合两个引理得出:L(α(t+1)) - L(α(t)) ≤ 0.
最后在两个基因数据(Colon Cancer Data 和 Leukemia Dataset)上实验。
[ZF(XTI{EYD3@_7PM8T{1.png)
2014 ECML: Covariate-correlated lasso for feature selection (ccLasso)
标签:
原文地址:http://www.cnblogs.com/shalijiang/p/4234715.html