标签:
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员现在可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是就可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
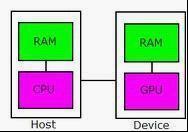
随着显卡的发展,GPU越来越强大,而且GPU为显示图像做了优化。在计算上已经超越了通用的CPU。如此强大的芯片如果只是作为显卡就太浪费了,因此NVidia推出CUDA,让显卡可以用于图像渲染和计算以外的目的(例如这里提到的通用并行计算)。CUDA是一种由NVIDIA提出的并由其制造的图形处理单元(GPUs)实现的一种并行计算平台及程序设计模型。CUDA给程序开发人员提供了直接访问CUDA GPUs中的虚拟指令集和并行计算组件的存储器。使用CUDA技术,GPUs可以用来进行通用处理(不仅仅是图形);这种方法被称为GPGPU。与CPUs不同的是,GPUs有着侧重以较慢速度运行大量并发线程的并发流架构,而非快速运行单一线程。开发人员可以利用C言、OpenCL、Fortran、c++等为CUDA架构编写程序。它们同CUDA之间的关系如下图所示:
上图就很好的反映出了CUDA与应用程序接口(API)以及各种语言编译器的关系,其中的DX11计算也就是Direct Compute。包括CUDA自家编译器所采用的C语言扩展、OpenCL应用程序接口、Fortran甚至C++等都可以运行在CUDA架构之上,未来CUDA还将支持更多的语言。在整个产业的共同推动下,GPU计算可谓是前途无量!
从CUDA体系结构的组成来说,它包含了三个部分:开发库、运行期环境和驱动。
(1)开发库是基于CUDA技术所提供的应用开发库。
(2)运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。
(3)驱动部分是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。目前于CUDA开发的应用必须有NVIDIA CUDA-enable的硬件支持。CPU,GPU,应用程序,CUDA开发库,运行环境,驱动之间的关系如下图所示:
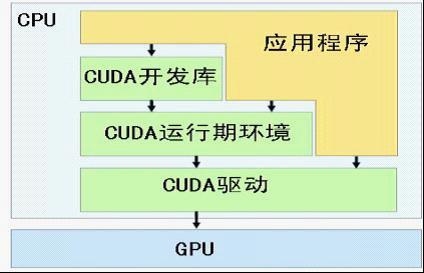
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片(GPU)上执行的部份。Device 端的程序又称为 "kernel"。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。由于 CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能经常进行这类动作,以免降低效率。
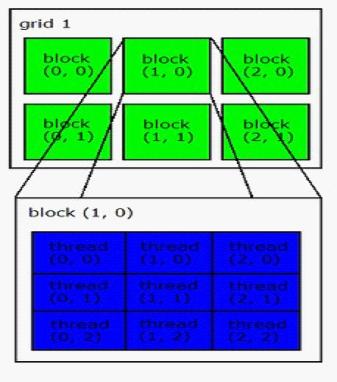
在 CUDA 架构下,显示芯片执行时的最小单位是 thread。数个thread 可以组成一个 block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。Grid、block 和 thread 的关系,如下图所示:
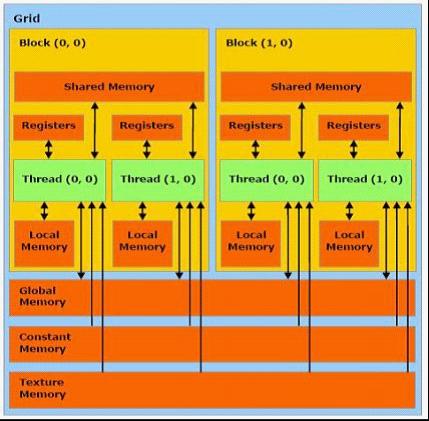
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。如下图所示:
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
1. 内存存取 latency (等待时间)的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
2. 分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline(流水线) bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的 latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。在这个过程中,CPU担任的工作为控制 GPU执行,调度分配任务,并能做一些简单的计算,而大量需要并行计算的工作都交给 GPU 实现。另外需要注意的是,由于 CPU 存取显存时只能通过 PCI-Express 接口,速度较慢,因此不能经常进行,以免降低效率。通常可以在程序开始时将数据复制进GPU显存,然后在 GPU内进行计算,直到获得需要的数据,再将其复制到系统内存中。
标签:
原文地址:http://www.cnblogs.com/chensheng-zhou/p/4240461.html