标签:
了解RDD之前,必读UCB的论文,个人认为这是最好的资料,没有之一。http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,
* partitioned collection of elements that can be operated on in parallel. This class contains the
* basic operations available on all RDDs, such as `map`, `filter`, and `persist`. In addition,* Internally, each
* [[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value
* pairs, such as `groupByKey` and `join`;
* [[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of
* Doubles; and
* [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that
* can be saved as SequenceFiles.
* These operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)]
* through implicit conversions when you `import org.apache.spark.SparkContext._`.
*RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
* All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
* to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for
* reading data from a new storage system) by overriding these functions. Please refer to the
* [[http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf Spark paper]] for more details
* on RDD internals.
*/abstract class RDD[T: ClassTag](
@transient private var sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {RDD是spark中最基础的数据表达形式,它的compute方法用来产生partition。由子类实现。/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]RDD的persist是一个主要的功能,它负责将RDD以某个存储级别保留给后续的计算流程使用,是的迭代计算高效。/**
* Set this RDD‘s storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet..
*/
def persist(newLevel: StorageLevel): this.type = {
// TODO: Handle changes of StorageLevel
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
sc.persistRDD(this)
// Register the RDD with the ContextCleaner for automatic GC-based cleanup
sc.cleaner.foreach(_.registerRDDForCleanup(this))
storageLevel = newLevel
this
}RDD可以设置本地化优先策略,这是在使用Hadoop做存储时提高性能的主要手段。/**
* Get the preferred locations of a partition (as hostnames), taking into account whether the
* RDD is checkpointed.
*/
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}RDD可以转化为其他的RDD,map/flatMap/filter是三个最常用的转化方式// Transformations (return a new RDD)/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = new MappedRDD(this, sc.clean(f))
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] =
new FlatMappedRDD(this, sc.clean(f))
/**
* Return a new RDD containing only the elements that satisfy a predicate.
*/
def filter(f: T => Boolean): RDD[T] = new FilteredRDD(this, sc.clean(f))注意,大部分时候RDD是推迟计算的,也就是在做transformation时,其实只是记录“如何做”,而真正的转化,是等到“Actions”来出发的。这样做的优势是使得串行化成为可能,这是spark性能高于hadoop的主要原因之一。// Actions (launch a job to return a value to the user program)
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit) {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}/**
* Reduces the elements of this RDD using the specified commutative and
* associative binary operator.
*/
def reduce(f: (T, T) => T): T = {
val cleanF = sc.clean(f)
val reducePartition: Iterator[T] => Option[T] = iter => {
if (iter.hasNext) {
Some(iter.reduceLeft(cleanF))
} else {
None
}
}
var jobResult: Option[T] = None
val mergeResult = (index: Int, taskResult: Option[T]) => {
if (taskResult.isDefined) {
jobResult = jobResult match {
case Some(value) => Some(f(value, taskResult.get))
case None => taskResult
}
}
}
sc.runJob(this, reducePartition, mergeResult)
// Get the final result out of our Option, or throw an exception if the RDD was empty
jobResult.getOrElse(throw new UnsupportedOperationException("empty collection"))
}/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum/**
* Returns the top K (largest) elements from this RDD as defined by the specified
* implicit Ordering[T]. This does the opposite of [[takeOrdered]]. For example:
* {{{
* sc.parallelize(Seq(10, 4, 2, 12, 3)).top(1)
* // returns Array(12)
*
* sc.parallelize(Seq(2, 3, 4, 5, 6)).top(2)
* // returns Array(6, 5)
* }}}
*
* @param num the number of top elements to return
* @param ord the implicit ordering for T
* @return an array of top elements
*/
def top(num: Int)(implicit ord: Ordering[T]): Array[T] = takeOrdered(num)(ord.reverse)RDD的checkpoint功能意义也很重大,因为它会将RDD存到可靠存储设备,所以在这个RDD之前的历史记录就可以不用记录了(因为这个RDD已经是可靠的,不需要更老的历史了)。对于RDD以来很长的应用,选择合适的checkpiont显得格外重要。/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with SparkContext.setCheckpointDir() and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint() {
if (context.checkpointDir.isEmpty) {
throw new Exception("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new RDDCheckpointData(this))
checkpointData.get.markForCheckpoint()
}
}这个调试函数会打印绝大部分的RDD的状态和信息。/** A description of this RDD and its recursive dependencies for debugging. */
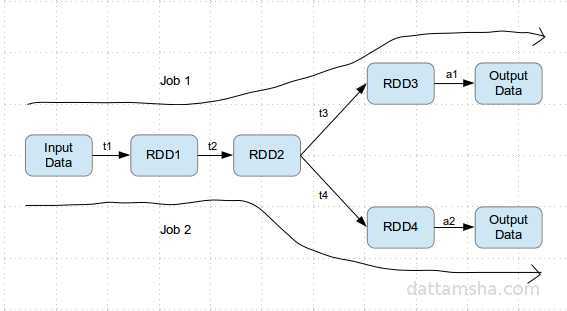
def toDebugString: String = {RDD的转换示意图:
标签:
原文地址:http://www.cnblogs.com/zwCHAN/p/4243075.html