标签:
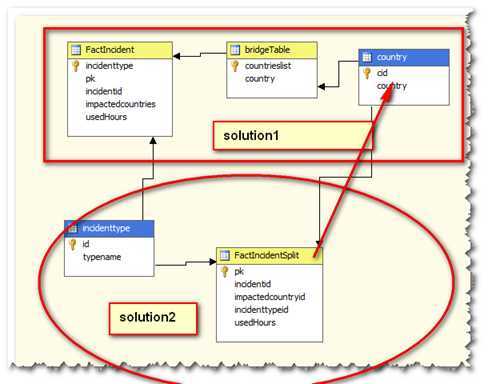
基本业务:一个事件发生后,影响到多个国家,这个事件也会被定一个事件类型(这里简化为type1,2,3),处理这个事件花费多长时间。
我们的事实表就记录这个事情,相对应的我们设计两个维表,一个是国家,一个是事件类型,我们可以从这两个维度slice数据。
因为受影响的国家是多值的,所以一条fact表中的记录,会对应多条维度表中的记录,在这里,我使用了一个桥接表来处理这种多对多
的关系,这是第一种实现方案,是正确的方案。
第二种是我引入了另外一张规范化的表,来直接建立一个星型模型,实现后有一些问题,引以为戒。
因为这种方式实现后,事实表的多行可能都表示同一个事件,只是影响的国家不同而已,这样通过国家维度聚合是没有问题,但是通过
其他维度如事件类型,进行聚合, 就会发生重叠计算。计算事件的count都需要distinct.而在SSAS中还需要单独列出一个measuregroup,
性能上也不佳。
Create database mybi; create table FactIncident(pk int,incidentid int,impactedcountries varchar(2000),incidenttype int,usedHours int); insert into FactIncident values(1,1,‘china,japan,India‘,1,100); insert into FactIncident values(2,2,‘china,japan,India,USA‘,2,200); insert into FactIncident values(3,3,‘china,japan‘,3,300); select * from FactIncident; create table country(cid int,country varchar(50)); insert into country values(1,‘china‘); insert into country values(2,‘japan‘); insert into country values(3,‘India‘); insert into country values(4,‘USA‘); create table incidenttype(id int, typename varchar(20)); insert into incidenttype values(1,‘type1‘); insert into incidenttype values(2,‘type2‘); insert into incidenttype values(3,‘type3‘); create table bridgeTable(countrieslist varchar(2000),country varchar(50)); select * from FactIncident; --insert into bridgeTable --SELECT clist, split.Part.value(‘text()[1]‘, ‘VARCHAR(30)‘) as country --FROM (SELECT impactedcountries,CAST(‘<p>‘ + REPLACE(impactedcountries,‘,‘,‘</p><p>‘)+‘</p>‘ AS XML) -- FROM FactIncident) innerQ(clist,xmlField) --CROSS APPLY innerQ.xmlField.nodes(‘p‘) split(Part)
如果我们直接构建星型模,需要把多值合并的列数据给规范化起来,需要创建另外一张Fact表,需要如下代码:
create table FactIncidentSplit(pk int,incidentid int,impactedcountryid int,incidenttypeid int,usedHours int); insert into FactIncidentSplit select ROW_NUMBER() over (order by incidentid) as pk, f.incidentid, cc.cid as impactedcountryid, f.incidenttype, f.usedHours from factincident f join ( select pk, splits.country.value(‘text()[1]‘, ‘VARCHAR(30)‘) as country from (select pk, CAST( ‘<p>‘ + REPLACE(impactedcountries,‘,‘,‘</p><p>‘) +‘</p>‘ as XML) from FactIncident) xx(pk,clist) cross apply xx.clist.nodes(‘p‘) splits(country) ) ff on f.pk=ff.pk join country cc on cc.country=ff.country
然后把这张表加到DSV中来,建立好关系,建立一个measuregroup,设定好dimensionusage.
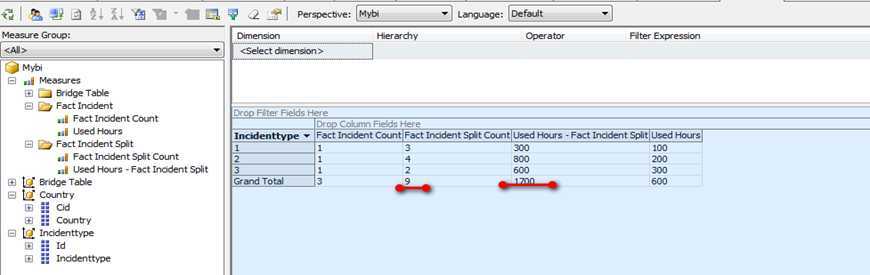
由下图可见,在使用事件类型维度的时候,规范化的事实表的事件总数和花费时长都是有问题的。
当然,如果把国家维度拖进来的话,就会正确。但这种影响是不应该的。
而使用桥接表的事实表是得到了正确的计算。
附件是SSAS项目的压缩文件,欢迎下载:
http://files.cnblogs.com/huaxiaoyao/AnalysisServicesProject1.rar
SSAS-many 2 many one simple sample
标签:
原文地址:http://www.cnblogs.com/huaxiaoyao/p/4245384.html