标签:
首先安装JDK,从Oracle官网下载

在 /usr/目录下mkdir java创建一个java目录
将jdk-7u72-linux-x64.rpm 放入java目录下
执行
rpm –ivh jdk-7u72-linux-x64.rpm
再从Apache官网下载
在 /usr/目录下 mkdir hadoop 创建一个hadoop目录
将hadoop-2.6.0.tar.gz 放入hadoop目录下
执行
tar –zxvf hadoop-2.6.0.tar.gz
接下来配置环境变量
vim /etc/profile
添加内容如下

export JAVA_HOME=/usr/java/ jdk1.7.0_72 export HADOOP_HOME=/usr/hadoop/hadoop-2.6.0 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
保存并退出文件,然后运行source命令使文件生效:
source /etc/profile
执行 java –version 测试Java是否配置成功

执行 hadoop version 测试hadoop是否配置成功

设置一下软连接
ln -s /usr/hadoop/hadoop-2.6.0 /opt/hadoop
ln -s /usr/java/jdk1.7.0_72 /opt/java
接下来修改Hadoop配置文件
export JAVA_HOME=/usr/java/jdk1.7.0_72
vim /etc/hosts
添加你的虚拟机的IP,如下图(我的虚拟机ip是192.168.0.125)

<property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:8020</value> </property>
注意:如果你是在虚拟机中搭建 Hadoop 环境,且虚拟机经常关闭与重启,为了避免每次重新虚拟机后启动Hadoop 时出现各种问题,建议在core-site.xml中将 hadoop.tmp.dir 属性设置为一个非/tmp 目录,比如/data或者/home/hadoop/data(注意该目录对当前用户需具有读写权限)。
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
需要注意的是, 在该配置文件中需用 mapreduce.framework.name 指定采用的运行时框架的名称, 在此指定“yarn”
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<property> <name>dfs.replication</name> <value>1</value> </property>
默认情况下,HDFS数据块副本数是3,而在集群规模小于3的集群中该参数会导致出现错误, 这可通过将dfs.replication调整为1解决。
设置免密码登陆
执行
ssh-keygen –t rsa
一路回车,看到图形输出,表示密钥生成成功,在”~/.ssh/”目录下多出两个文件
私钥文件:id_raa
公钥文件:id_rsa.pub
将公钥文件id_rsa.pub内容放到authorized_keys文件中:
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
启动Hadoop
在Hadoop安装目录中,按以下三步操作启动Hadoop,我们单步启动每一个服务,以便于排查错误,如果某一个服务没有启动成功,可查看对应的日志查看启动失败原因。
1)格式化HDFS,命令如下:
bin/hadoop namenode –format
2)使用以下命令一次性启动NameNode和所有DataNode:
sbin/ ./start-dfs.sh
3)使用以下命令一次性启动ResourceManager和所有NodeManager:
sbin/ ./start-yarn.sh
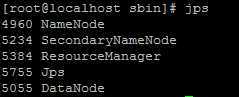
使用jps命令查看运行情况
首先将防火墙关闭,在根目录下执行
systemctl stop firewalld.service
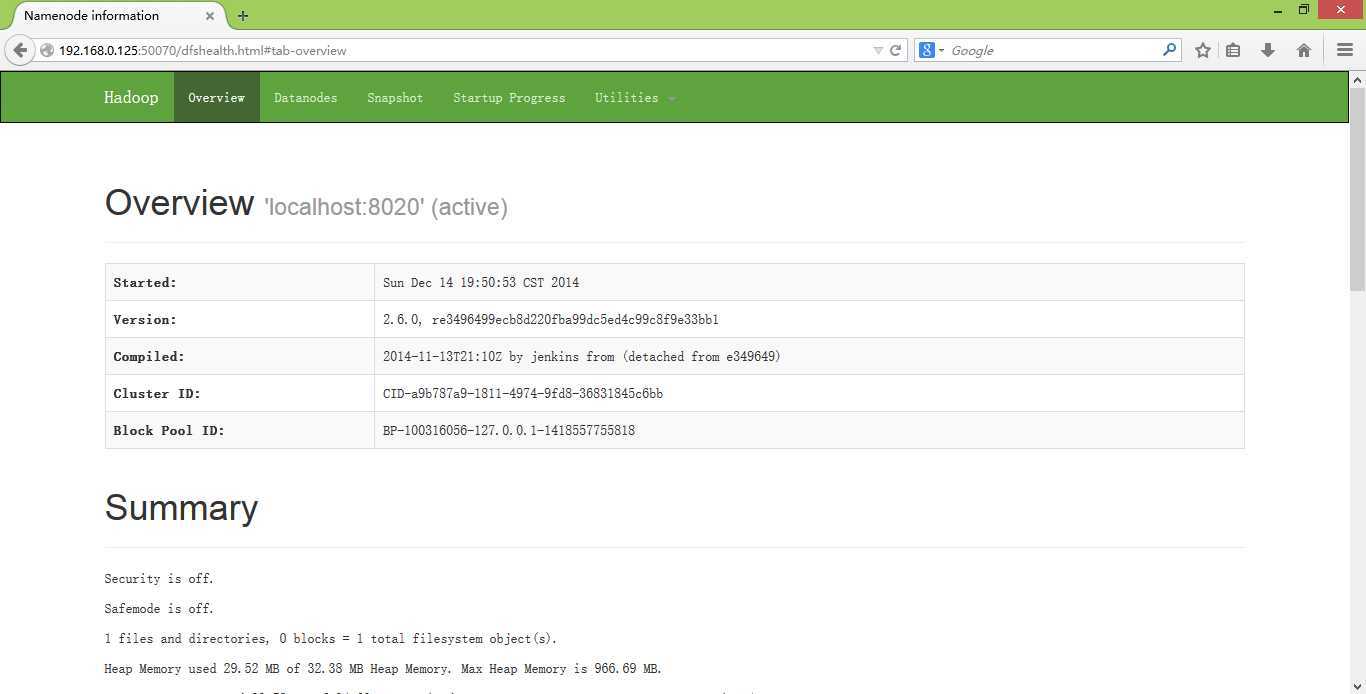
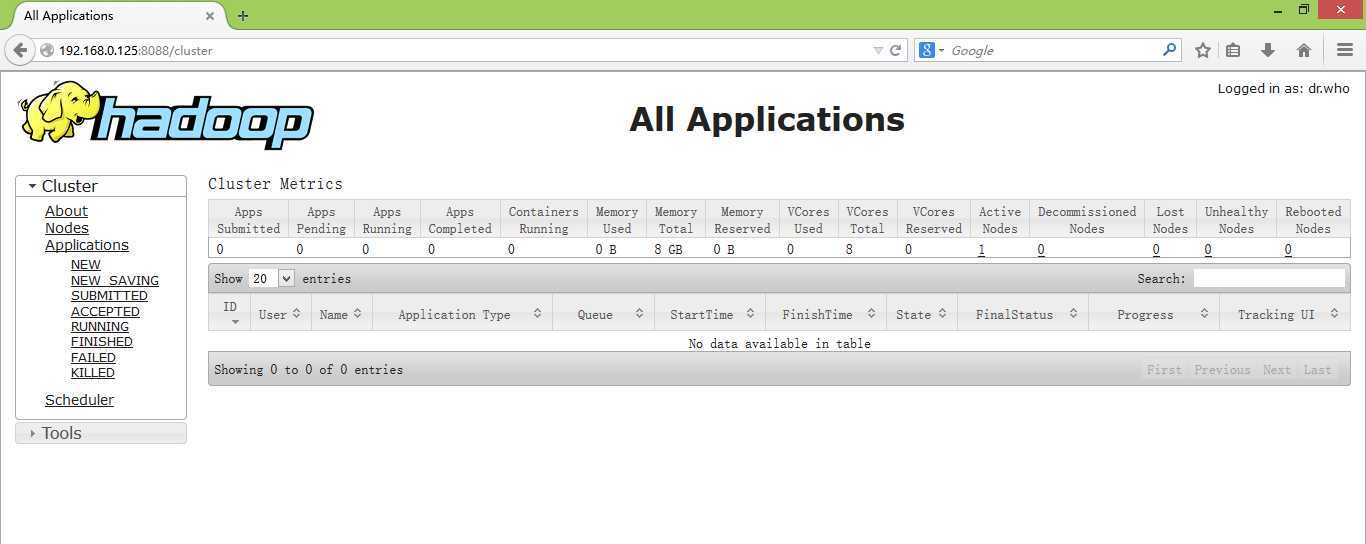
打开浏览器查看端口50070和8088
安装完成
标签:
原文地址:http://www.cnblogs.com/HappyDream/p/4246328.html