标签:
Map类:
1 package lyc.yushao.hadoop.mr.wc; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Mapper; 8 9 public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> { 10 11 @Override 12 protected void map(LongWritable key, Text value, Context context) 13 throws IOException, InterruptedException { 14 // 首先,接收数据 15 // accept data 16 String line = value.toString(); 17 // 进行拆分 18 // split 19 String[] words = line.split(" "); 20 // 进行循环 21 // loop 22 for (String w : words) { 23 // 发送 24 // send 25 context.write(new Text(w), new LongWritable(1)); 26 } 27 28 } 29 30 }
Reduce类:
1 package lyc.yushao.hadoop.mr.wc; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Reducer; 8 9 public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { 10 11 @Override 12 protected void reduce(Text key, Iterable<LongWritable> values, 13 Context context) throws IOException, InterruptedException { 14 // 定义一个计数器 15 // define a counter 16 long counter = 0; 17 18 // 接收数据 循环 19 // accept data and loop 20 for (LongWritable i : values) { 21 // sum 22 counter += i.get(); 23 24 } 25 // send 26 context.write(key, new LongWritable(counter)); 27 28 } 29 30 }
WordCount类:
1 package lyc.yushao.hadoop.mr.wc; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 public class WordCount { 12 13 public static void main(String[] args) throws Exception { 14 Configuration conf = new Configuration(); 15 // 将mapreduce抽象成一个作业 16 Job job = Job.getInstance(conf); 17 18 // notice!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 19 job.setJarByClass(WordCount.class); 20 21 // 将自定义的类组装起来 22 23 // set mapper‘s properties 24 job.setMapperClass(WCMapper.class); 25 26 job.setMapOutputKeyClass(Text.class); 27 28 job.setMapOutputValueClass(LongWritable.class); 29 30 // 读取HDFS数据 31 FileInputFormat.setInputPaths(job, new Path("/words.txt")); 32 33 // set reducer‘s properties 34 job.setReducerClass(WCReducer.class); 35 // 输出到HDFS里面 36 job.setOutputKeyClass(Text.class); 37 job.setOutputValueClass(LongWritable.class); 38 FileOutputFormat.setOutputPath(job, new Path("/wcout111")); 39 40 // 调用job的一些方法来提交 41 // submit,but this is not good 42 // job.submit(); 43 job.waitForCompletion(true); 44 } 45 46 }
右键:工程名
Export
JAR File
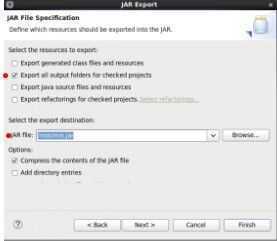
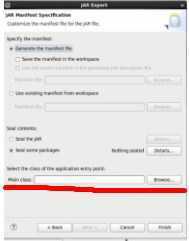
Finish
命令行中:
hadoop jar /root/mrs.jar
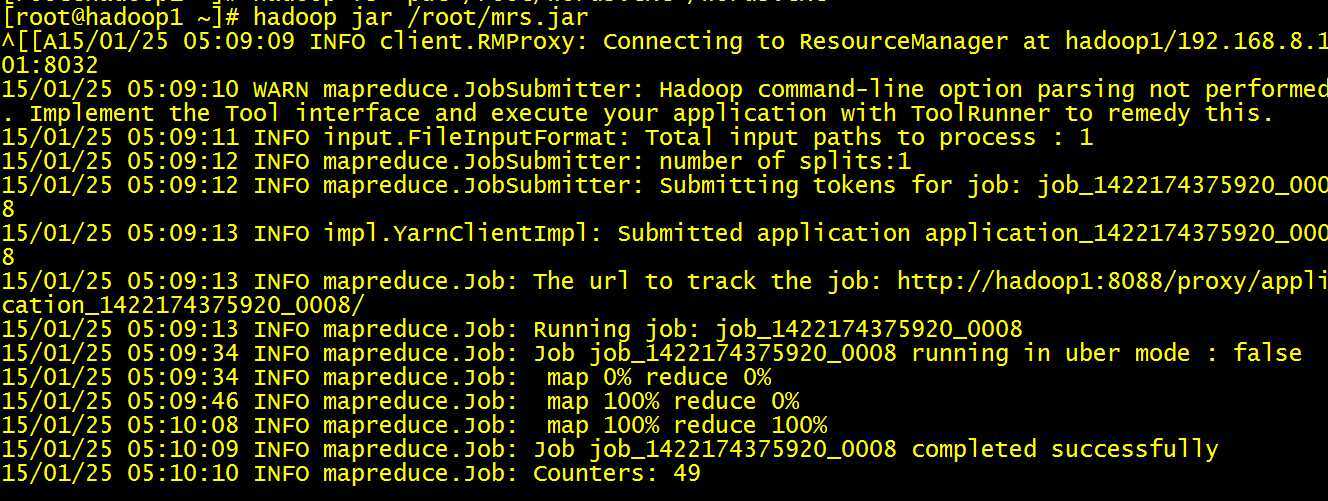
SUCCESS!!
标签:
原文地址:http://www.cnblogs.com/muziyushao/p/4248983.html