标签:
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及project等领域都很重要的概率分布,在统计学的很多方面有着重大的影响力。
若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布,记为:
则其概率密度函数为
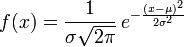
正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。因其曲线呈钟形,因此人们又常常称之为钟形曲线。我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布(见右图中绿色曲线)。
文件夹[隐藏] |
正态分布是自然科学与行为科学中的定量现象的一个方便模型。各种各样的心理学測试分数和物理现象比方光子计数都被发现近似地服从正态分布。虽然这些现象的根本原因常常是未知的, 理论上能够证明假设把很多小作用加起来看做一个变量,那么这个变量服从正态分布(在R.N.Bracewell的Fourier transform and its application中能够找到一种简单的证明)。正态分布出如今很多区域统计:比如, 採样分布均值是近似地正态的,既使被採样的样本整体并不服从正态分布。另外,常态分布信息熵在全部的已知均值及方差的分布中最大,这使得它作为一种均值以及方差已知的分布的自然选择。正态分布是在统计以及很多统计測试中最广泛应用的一类分布。在概率论,正态分布是几种连续以及离散分布的极限分布。
常态分布最早是亚伯拉罕·棣莫弗在1734年发表的一篇关于二项分布文章中提出的。拉普拉斯在1812年发表的《分析概率论》(Theorie Analytique des Probabilites)中对棣莫佛的结论作了扩展。如今这一结论通常被称为棣莫佛-拉普拉斯定理。
拉普拉斯在误差分析试验中使用了正态分布。勒让德于1805年引入最小二乘法这一重要方法;而高斯则宣称他早在1794年就使用了该方法,并通过如果误差服从正态分布给出了严格的证明。
“钟形曲线”这个名字能够追溯到Jouffret他在1872年首次提出这个术语"钟形曲面",用来指代二元正态分布(bivariate normal)。正态分布这个名字还被Charles S. Peirce、Francis Galton、Wilhelm Lexis在1875分布独立的使用。这个术语是不幸的,由于它反应和鼓舞了一种谬误,即非常多概率分布都是正态的。(请參考以下的“实例”)
这个分布被称为“正态”或者“高斯”正好是Stigler名字由来法则的一个样例,这个法则说“没有科学发现是以它最初的发现者命名的”。
有几种不同的方法用来说明一个随机变量。最直观的方法是概率密度函数,这样的方法可以表示随机变量每一个取值有多大的可能性。累积分布函数是一种概率上更加清楚的方法,可是非专业人士看起来不直观(请看下边的样例)。另一些其它的等价方法,比如cumulant、特征函数、动差生成函数以及cumulant-生成函数。这些方法中有一些对于理论工作很实用,可是不够直观。请參考关于概率分布的讨论。
正态分布的概率密度函数均值为μ 方差为σ2 (或标准差σ)是高斯函数的一个实例:
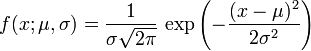 。
。(请看指数函数以及π.)
假设一个随机变量X服从这个分布,我们写作 X ~ N(μ,σ2). 假设μ = 0而且σ = 1,这个分布被称为标准正态分布,这个分布可以简化为
 。
。右边是给出了不同參数的正态分布的函数图。
正态分布中一些值得注意的量:
累积分布函数是指随机变量X小于或等于x的概率,用密度函数表示为

正态分布的累积分布函数可以由一个叫做误差函数的特殊函数表示:

标准正态分布的累积分布函数习惯上记为Φ,它不过指μ = 0,σ = 1时的值,

将一般正态分布用误差函数表示的公式简化,可得:
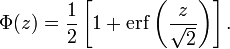
它的反函数被称为反误差函数,为:
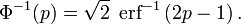
该分位数函数有时也被称为probit函数。probit函数已被证明没有初等原函数。
正态分布的分布函数Φ(x)没有解析表达式,它的值能够通过数值积分、泰勒级数或者渐进序列近似得到。
动差生成函数被定义为exp(tX)的期望值。
正态分布的矩生成函数例如以下:
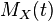 |
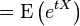 |
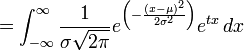 |
|
 |
能够通过在指数函数内配平方得到。
特征函数被定义为exp(itX)的期望值,当中i是虚数单位. 对于一个正态分布来讲,特征函数是:
 |
 |
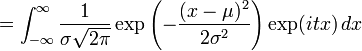 |
|
 |
把矩生成函数中的t换成it就能得到特征函数。
正态分布的一些性质:
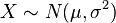 且a与b是实数,那么aX + b∼N(aμ
+ b,(aσ)2) (參见期望值和方差).
且a与b是实数,那么aX + b∼N(aμ
+ b,(aσ)2) (參见期望值和方差). 与
与 是统计独立的正态随机变量,那么:
是统计独立的正态随机变量,那么:
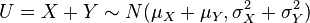 (proof).
(proof). .
. 和
和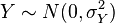 是独立正态随机变量,那么:
是独立正态随机变量,那么:
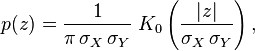 当中K0是贝塞尔函数(modified
Bessel function)
当中K0是贝塞尔函数(modified
Bessel function) 为独立标准正态随机变量,那么
为独立标准正态随机变量,那么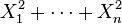 服从自由度为n的卡方分布。
服从自由度为n的卡方分布。一些正态分布的一阶动差例如以下:
| 阶数 | 原点矩 | 中心矩 | 累积量 |
|---|---|---|---|
| 0 | 1 | 0 | |
| 1 | μ | 0 | μ |
| 2 | μ2 + σ2 | σ2 | σ2 |
| 3 | μ3 + 3μσ2 | 0 | 0 |
| 4 | μ4 + 6μ2σ2 + 3σ4 | 3σ4 | 0 |
正态分布的全部二阶以上的累积量为零。
正态分布有一个很重要的性质:在特定条件下,大量统计独立的随机变量的和的分布趋于正态分布,这就是中心极限定理。中心极限定理的重要意义在于,依据这一定理的结论,其它概率分布能够用正态分布作为近似。
近似正态分布平均数为μ = np且方差为σ2 = np(1 ? p).
近似正态分布平均数为μ = λ且方差为σ2 = λ.
这些近似值是否全然充分正确取决于使用者的使用需求
正态分布是无限可分的概率分布。
正态分布是严格稳定的概率分布。
在实际应用上,常考虑一组数据具有近似于正态分布的概率分布。若其如果正确,则约68%数值分布在距离平均值有1个标准差之内的范围,约95%数值分布在距离平均值有2个标准差之内的范围,以及约99.7%数值分布在距离平均值有3个标准差之内的范围。称为"68-95-99.7法则"或"经验法则".
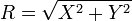 ,这里X∼N(0,σ2)和Y∼N(0,σ2)是两个独立正态分布。
,这里X∼N(0,σ2)和Y∼N(0,σ2)是两个独立正态分布。 是卡方分布具有ν自由度,假设
是卡方分布具有ν自由度,假设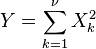 这里Xk∼N(0,1)当中
这里Xk∼N(0,1)当中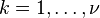 是独立的。
是独立的。 因而
因而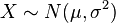 .
.多元正态分布的协方差矩阵的预计的推导是比較难于理解的。它须要了解谱原理(spectral theorem)以及为什么把一个标量看做一个1×1 matrix的trace而不不过一个标量更合理的原因。请參考协方差矩阵的预计(estimation of covariance matrices).
《饮料装填量不足与超量的概率》
某饮料公司装瓶流程严谨,每罐饮料装填量符合平均600毫升,标准差3毫升的常态分配法则。随机选取一罐,容量超过605毫升的概率?容量小于590毫升的概率
容量超过605毫升的概率 = p ( X > 605)= p ( ((X-μ) /σ) > ( (605 – 600) / 3) )= p ( Z > 5/3) = p( Z > 1.67) = 0.9525
容量小于590毫升的概率 = p (X < 590) = p ( ((X-μ) /σ) < ( (590 – 600) / 3) )= p ( Z < -10/3) = p( Z < -3.33) = 0.0004
《6-标准差(6-sigma或6-σ)的品质管制标准》
6-标准差(6-sigma或6-σ),是制造业流行的品质管制标准。在这个标准之下,一个标准常态分配的变量值出如今正负三个标准差之外,仅仅有2* 0.0013= 0.0026 (p (Z < -3) = 0.0013以及p(Z > 3) = 0.0013)。也就是说,这样的品质管制标准的产品不良率仅仅有万分之二十六。如果例3-16的饮料公司装瓶流程採用这个标准,而每罐饮料装填量符合平均600毫升,标准差3毫升的常态分配法则。预期装填容量的范围应该多少? 6-标准差的范围 = p ( -3 < Z < 3)= p ( - 3 < (X-μ) /σ < 3) = p ( -3 < (X- 600) / 3 < 3)= p ( -9 < X – 600 < 9) = p (591 < X < 609) 因此,预期装填容量应该介于591至609毫升之间。
《计算学生智商高低的概率》
如果某校入学新生的智力測验平均分数与方差分别为100与12。那么随机抽取50个学生,他们智力測验平均分数大于105的概率?小于90的概率?
本例没有常态分配的如果,还好中心极限定理提供一个可行解,那就是当随机样本长度超过30,样本平均数xbar近似于一个常态变量,因此标准常态变量Z = (xbar –μ) /σ/ √n。
平均分数大于105的概率 = p(Z> (105 – 100) / (12 /√50))= p(Z> 5/1.7) = p( Z > 2.94) = 0.0016
平均分数小于90的概率 = p(Z< (90 – 100) / (12 /√50))= p(Z < 5.88) = 0.0000
在计算机模拟中,常常须要生成正态分布的数值。最主要的一个方法是使用标准的正态累积分布函数的反函数。除此之外还有其它更加高效的方法,Box-Muller变换就是当中之中的一个。还有一个更加快捷的方法是ziggurat算法。以下将介绍这两种方法。一个简单可行的而且easy编程的方法是:求12个在(0,1)上均匀分布的和,然后减6(12的一半)。这样的方法能够用在非常多应用中。这12个数的和是Irwin-Hall分布;选择一个方差12。这个随即推导的结果限制在(-6,6)之间,而且密度为12,是用11次多项式预计正态分布。
Box-Muller方法是以两组独立的随机数U和V,这两组数在(0,1]上均匀分布,用U和V生成两组独立的标准正态分布随即变量X和Y:

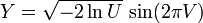 。
。这个方程的提出是由于二自由度的卡方分布(见性质4)非常easy由指数随机变量(方程中的lnU)生成。因而通过随机变量V能够选择一个均匀围绕圆圈的角度,用指数分布选择半径然后变换成(正态分布的)x,y坐标。
正态分布(Normal distribution)又名高斯分布(Gaussian distribution)
标签:
原文地址:http://www.cnblogs.com/bhlsheji/p/4249744.html




 ,
在
,
在 这里
这里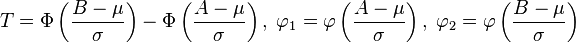 ,
,